No CUDA Code Needed, Accelerate H100 by 33%-50%!
A new work by Tri Dao, co-author of Flash Attention and Mamba, has gone viral.
He and two Princeton CS PhD students proposed a new SOL memory-bound kernel library called QuACK. Using CuTe-DSL, it is written entirely in Python, with absolutely no CUDA C++ code involved.
On an H100 with 3TB/s bandwidth, its speed is 33%-50% faster than deeply optimized libraries like PyTorch’s torch.compile and Liger.
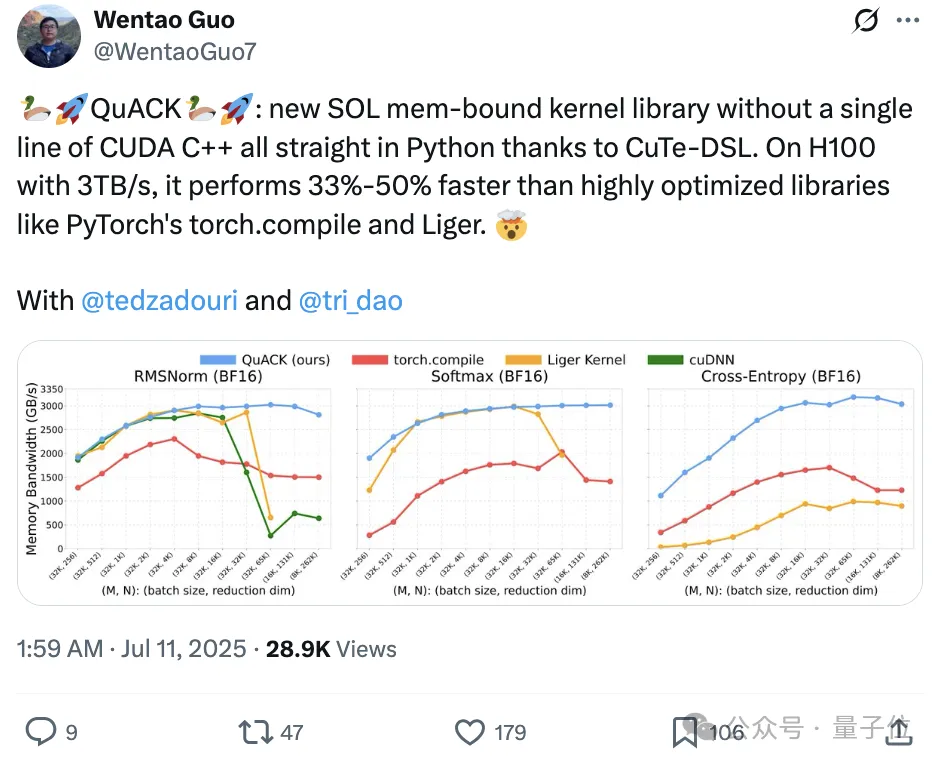
Tri Dao stated that achieving “light speed” for memory-intensive kernels is not a mystery; it simply requires getting several details right.

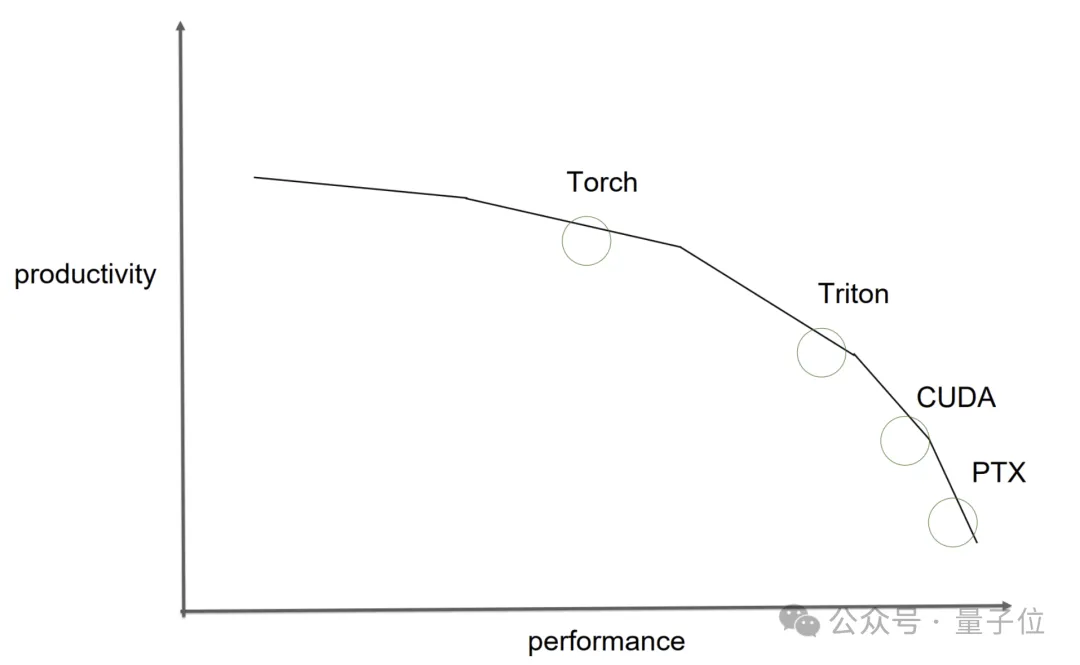
I really like Phil Tillet’s perspective on the trade-offs between productivity and performance across different tools, such as torch compile, triton, CUDA, and PTX.
However, CuTe-DSL and similar Python-based DSLs might change this landscape, although they are still in their early stages. Moreover, perhaps soon we will be able to have large language models generate these kernels!
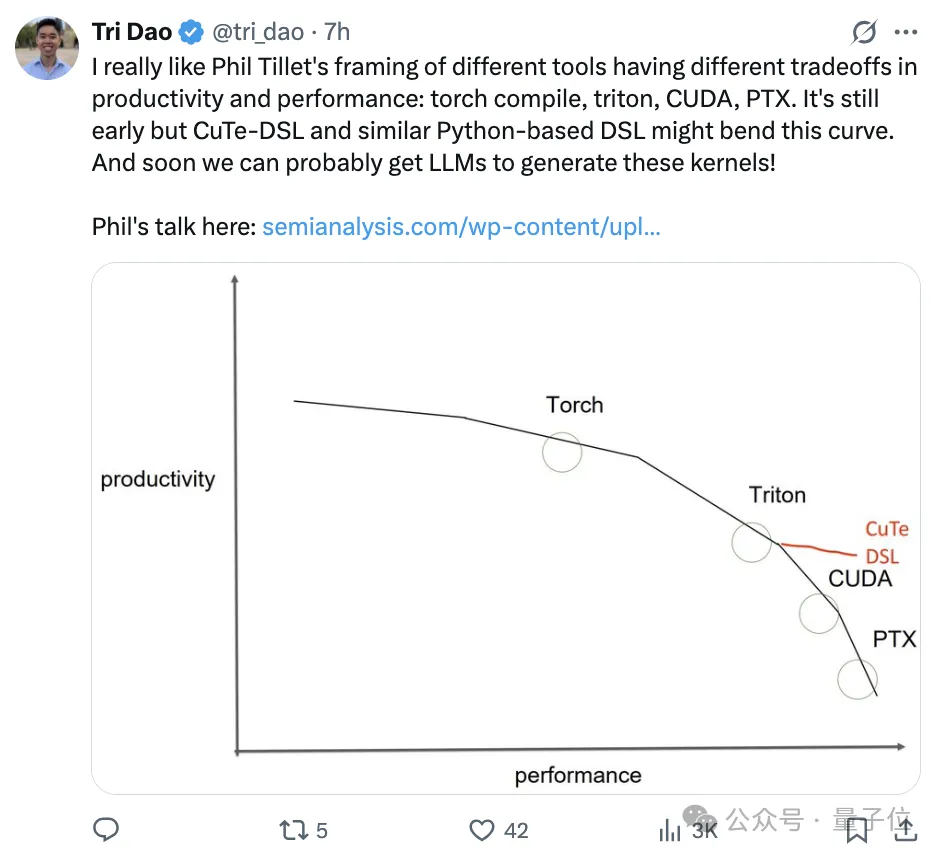
The new work attracted significant attention from industry leaders upon release.
Vijay, a Senior Architect on the NVIDIA CUTLASS team, shared it and praised his team’s CuTe-DSL for refining various details to such an extent that experts like Tri Dao can make GPUs run at lightning speed.
He also teased more related content coming later this year.
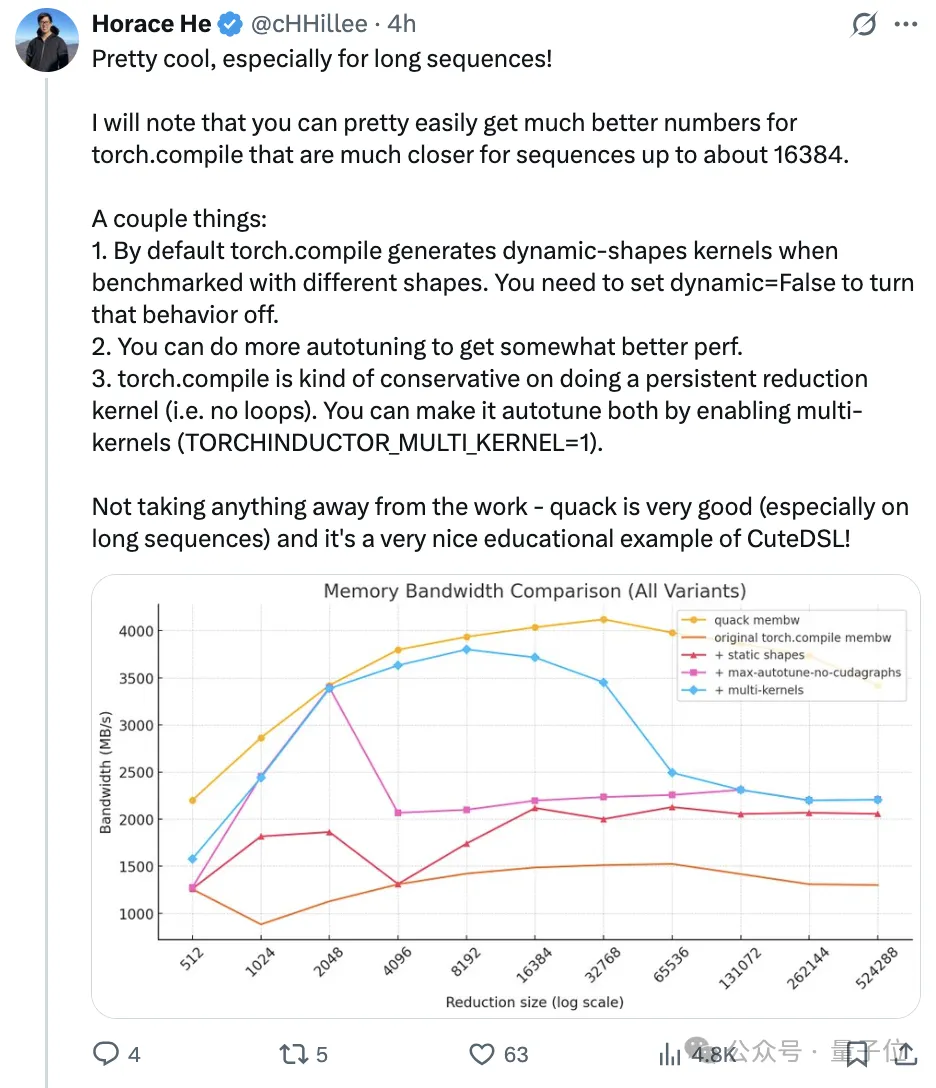
Horace He, a member of the PyTorch team, was also drawn in and immediately praised it as “too cool, especially for long sequences.”
However, he pointed out that when processing sequences with lengths up to approximately 16384, PyTorch’s torch.compile performance data can be optimized relatively easily to approach ideal states.
He then provided several suggestions for optimizing torch.compile performance:
By default, if tested with different shapes,
torch.compilegenerates dynamic shape kernels; this behavior can be disabled by settingdynamic=False.
Performing more auto-tuning operations can further improve performance.
torch.compileis conservative in generating loop-free persistent reduction kernels; you can enable multi-kernel (by setting(TORCHINDUCTOR_MULTI_KERNEL=1)) to allow it to auto-tune.
Finally, he acknowledged that QuACK is undoubtedly an excellent piece of work and serves as a great teaching example for CuTe-DSL.
Tri Dao responded, “Awesome, this is exactly what we wanted. We will try these methods and update the charts.”

User Guide
The QuACK authors wrote a tutorial explaining the specific implementation, with code that can be used directly.
Achieving “Light Speed” for Memory-Intensive Kernels
To keep GPUs running at high speeds during both model training and inference, two types of kernels must be optimized simultaneously: compute-intensive ones (such as matrix multiplication and attention mechanisms) and memory-intensive ones (such as element-wise operations, normalization, and loss function calculations).
Matrix multiplication and attention mechanisms are already well-optimized. Therefore, the authors focused this time on memory-intensive kernels—these kernels spend most of their time on memory access (input/output), with relatively little time spent on actual computation.
By understanding and leveraging the thread and memory hierarchy structures of modern accelerators, these kernels can approach their “theoretical limits.” Thanks to the latest CuTe-DSL, this can be achieved in a familiar Python environment without writing CUDA C or C++ code.
Memory-intensive kernels have a characteristic: low arithmetic intensity (i.e., a small ratio of floating-point operations (FLOPs) to bytes transferred). Once a kernel’s arithmetic intensity falls into the memory-bound category, its throughput is no longer determined by how many FLOPs it can complete per second, but rather by how many bytes it can transfer per second.

Among these memory-intensive kernels, element-wise activation operations are relatively simple to handle. Since the computation for each element is independent, they are naturally suited for fully parallel processing.
However, reduction operations, which require aggregating all values, are frequently used in deep learning operators like softmax and RMSNorm.
Parallel associative reduction algorithms perform O(log(reduction dimension)) rounds of partial reductions across threads in different spaces, where the authors’ understanding of GPU memory hierarchy plays a crucial role.
Parallel Maximum Reduction:
Next, the authors will introduce how to utilize the GPU’s memory hierarchy to implement efficient reduction kernels.
As examples, they implemented three commonly used kernels in large language models using CuTe DSL: RMSNorm, softmax, and cross-entropy loss.
The goal is to achieve maximum hardware throughput, i.e., “GPU light-speed throughput,” which requires two key elements: 1) coalesced loading/storing of global memory; and 2) hardware-aware reduction strategies.
Additionally, the authors will explain cluster reductions and how they assist with ultra-large-scale reduction tasks, a newer feature introduced in NVIDIA GPUs starting from the Hopper architecture (H100).
Then, they will detail these key elements and explain how they help write “light-speed” kernels.

GPU Memory Hierarchy Structure
Before writing kernel code, one must first understand the memory hierarchy of modern GPUs. Here, we use a Hopper architecture GPU (such as the H100) as an example.
In Hopper architecture GPUs, CUDA execution is divided into four levels: threads, thread blocks, the newly introduced thread block clusters, and the full grid.
A single thread runs within a Streaming Multiprocessor (SM) in groups of 32 threads called “warps”. Each thread block has a piece of 192-256 KB unified shared memory (SMEM), which all warps within the same thread block can access.
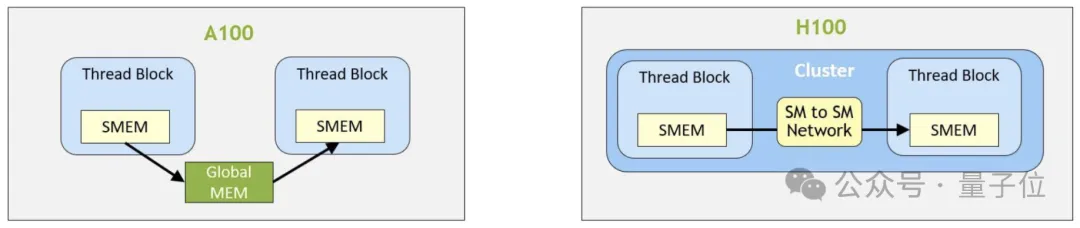
H100’s thread clusters allow up to 16 thread blocks running on adjacent SMs to read from and write to each other’s shared memory via distributed shared memory (DSMEM) structures and perform atomic operations. This process is coordinated through low-latency cluster barriers, avoiding costly global memory round-trips.
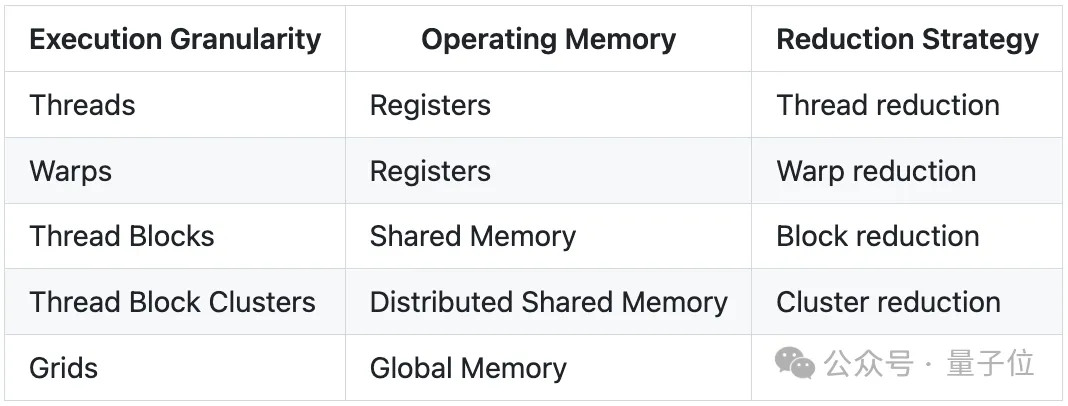
Each level of memory has read/write primitives for local reductions. Therefore, the authors will develop a generic reduction template in CuTe DSL to ensure that H100 achieves “light-speed” throughput across reduction dimensions ranging from 256 to 2^62k.
Memory Hierarchy Structure in H100:
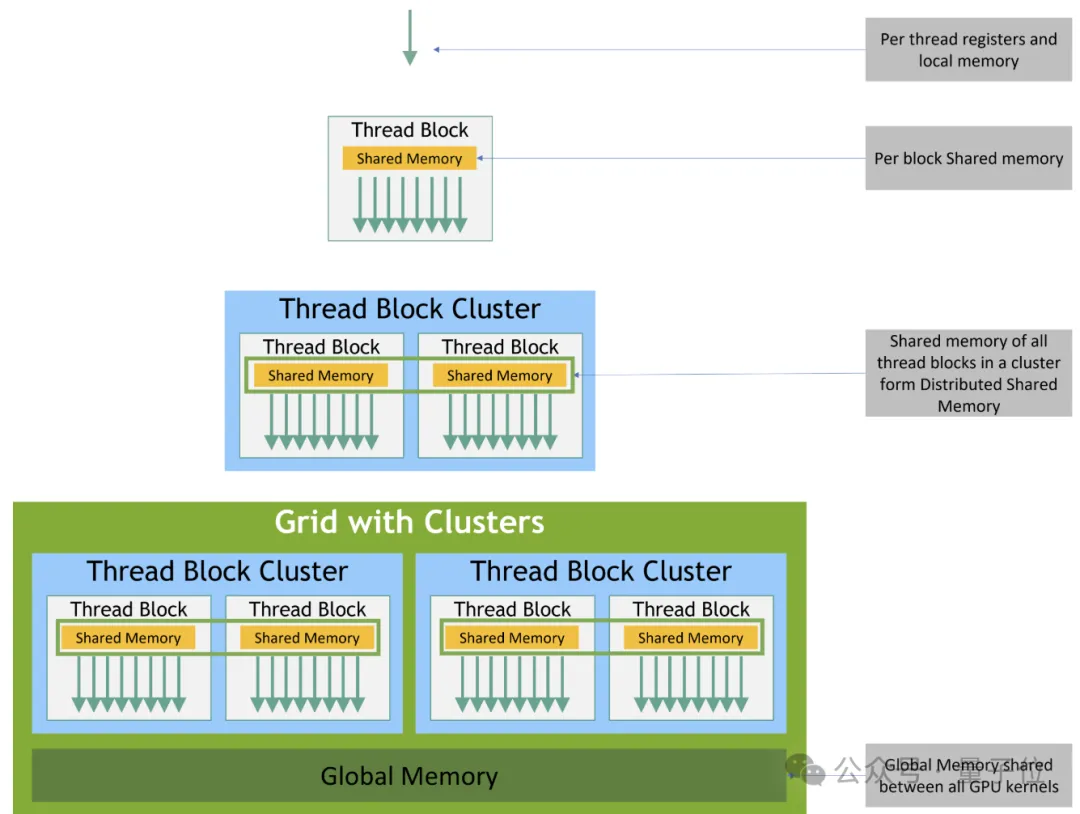
Correspondence between execution granularity and memory hierarchy in Hopper GPUs:
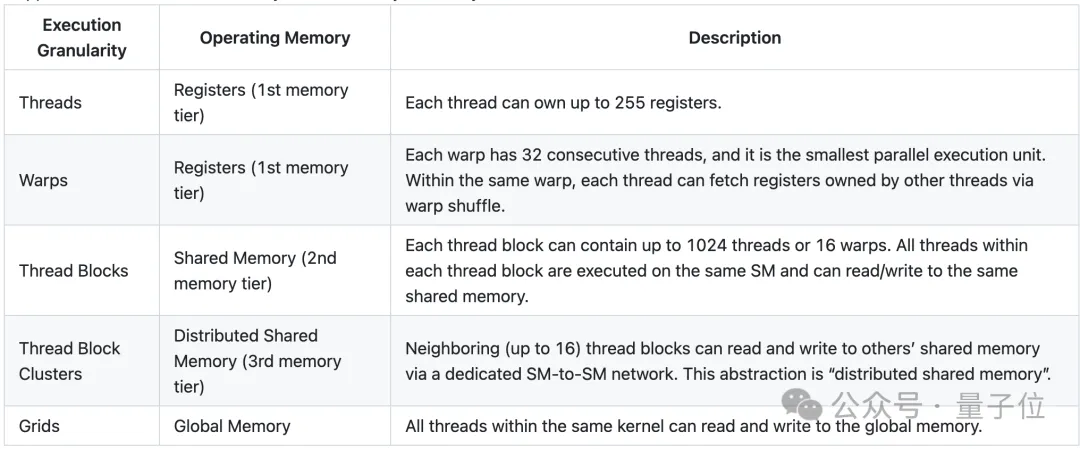
Access latency and bandwidth vary for each memory level.
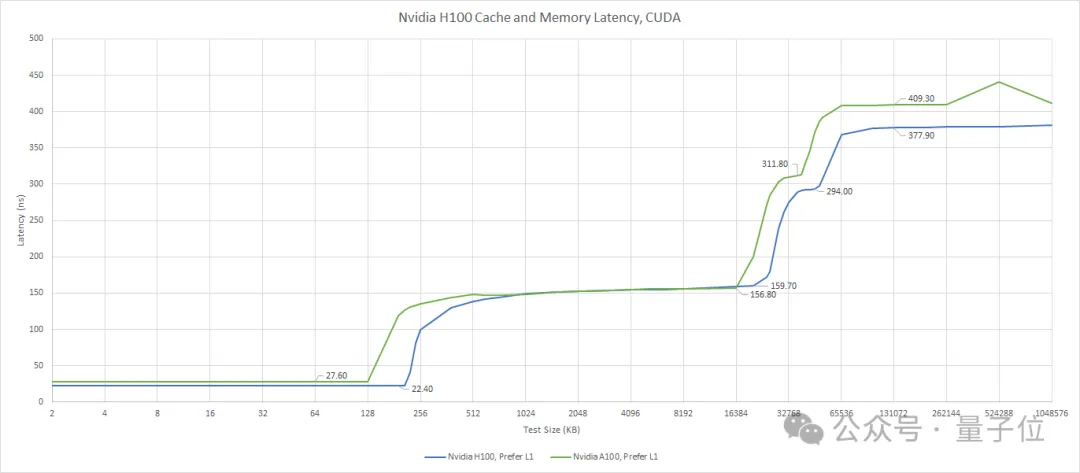
For instance, accessing a thread’s own registers takes only a few nanoseconds, while accessing shared memory takes about 10-20 nanoseconds. Moving up, accessing the L2 cache spikes in latency to 150-200 nanoseconds, and finally, accessing DRAM (main memory) takes approximately 400 nanoseconds.
Regarding bandwidth, accessing registers can reach 100 TB/s, shared memory (SMEM) is about 20-30 TB/s, and L2 cache is 5-10 TB/s. For memory-bound kernels, the HBM3 VRAM bandwidth of the H100 (3.35TB/s) is often the performance bottleneck.
Therefore, to fully exploit hardware performance, when designing memory-intensive kernels, one must follow the memory hierarchy:
It is best to assign most local reduction operations to higher memory levels, passing only a small amount of locally reduced values to the next memory level. Chris Fleetwood provided a similar explanation for A100 (without thread block clusters) memory access latency in his blog, while H100 adds an extra memory level abstraction between shared memory (SMEM) and global memory (GMEM).
Memory Access Latency in H100:
Hardware-Aware Loading and Storage Strategies
When writing kernel code, the first problem to solve is “how to load input data and store results.” For memory-bound kernels, HBM’s 3.35 TB/s is usually the bottleneck, meaning extreme optimization of loading and storage strategies is required.
Before launching the kernel, input data is partitioned using a specific thread-value layout (TV-layout). This determines how each thread loads and processes values along the reduction dimension.
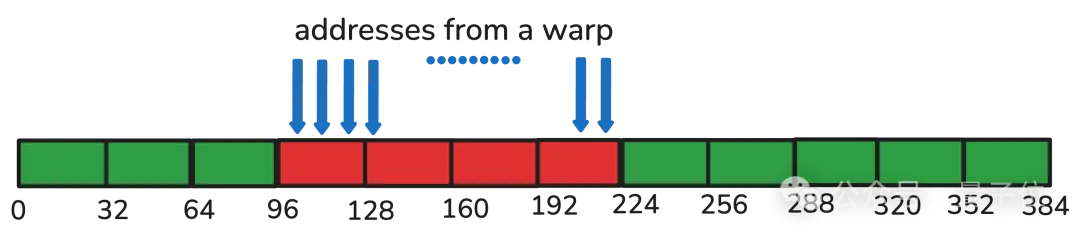
Since every thread must load data from global memory (GMEM), it is necessary to ensure that each load operation transfers the maximum number of bits continuously on the hardware. This technique is commonly known as memory coalescing or coalesced access to global memory, which is explained in more detail in the CUDA Best Practices Guide.
Coalesced Memory Access:
{kind=link}
In the H100, this means that each thread must process data in multiples of 128 bits, specifically 4x FP32 or 8x BF16. Consequently, for FP32, four load and store operations are combined (or “vectorized”) into a single memory transaction, thereby maximizing throughput.
In practice, the author asynchronously loads data from global memory (GMEM) to shared memory (SMEM), then vectorizes these loads into registers. Once the reduction yields the final result, it is stored directly back into global memory.
At times, input data can be reloaded from global or shared memory into registers to reduce register pressure and prevent data “overflow.”
Below is a code snippet for the load operation written in Python using the CuTe DSL. To keep things simple, type conversion and mask predicate-related code have been omitted here.

Hardware-Aware Reduction Strategies
Once each thread holds a small input vector, reduction can begin. Each reduction step requires one or more full row scans.
Recall that as you move from the top to the bottom of the memory hierarchy, access latency increases while bandwidth decreases.
Therefore, reduction strategies should follow this hardware memory hierarchy:
Partial results stored in higher levels of the memory pyramid should be aggregated immediately, passing only locally reduced values to the next memory level.
The author performs reductions from the top down according to the table below, ensuring that load and store operations occur exclusively within their corresponding memory levels at each step.
Reduction strategies across different memory levels:
1. Thread-Level Reduction (Register Read/Write)
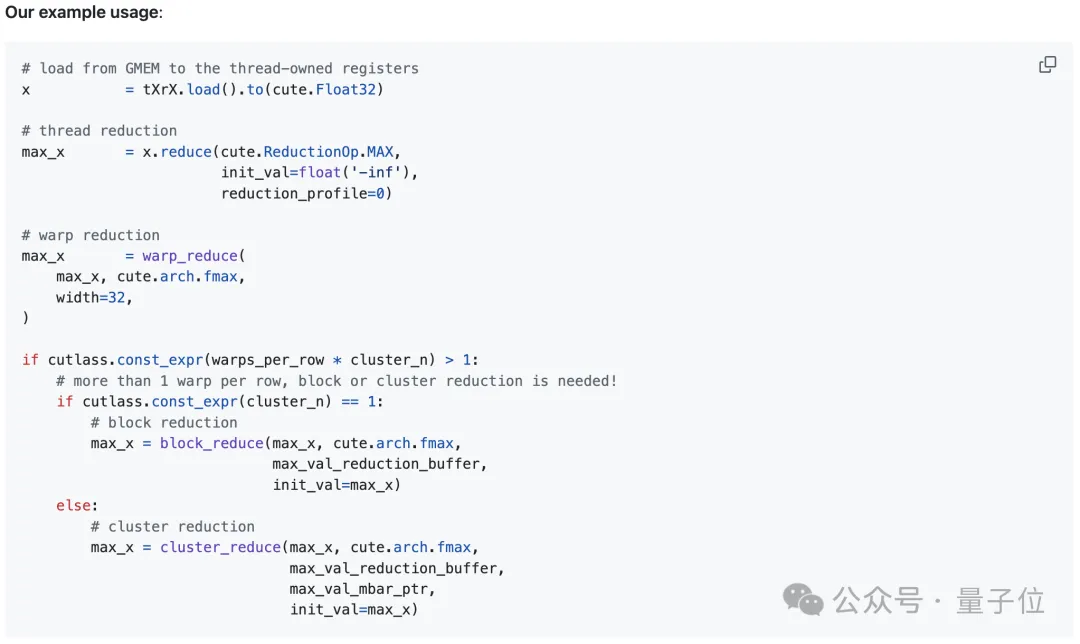
Each thread locally reduces multiple vectorized loaded values. The author uses the TensorSSA.reduce function, which requires a combinable reduction operator (op), an initial value before reduction (init_val), and a reduction dimension profile (reduction_profile).

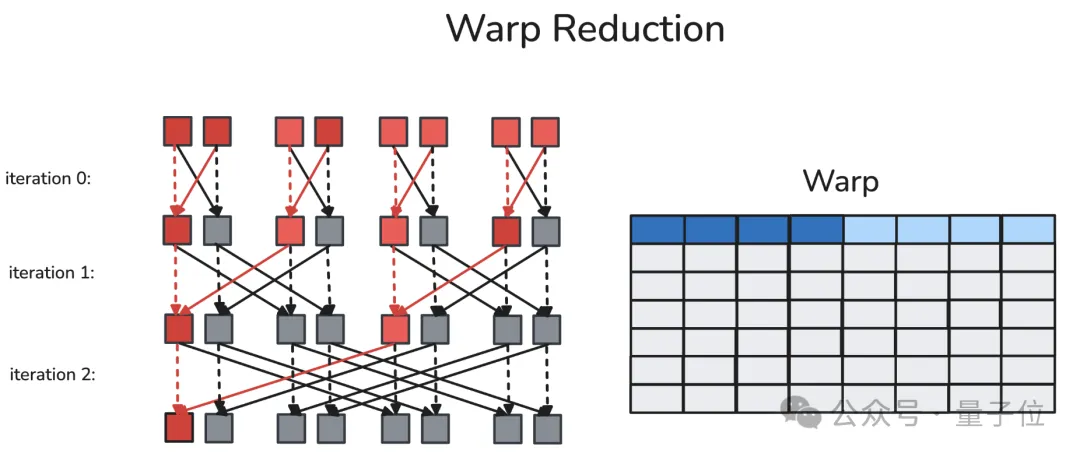
2. Warp-Level Reduction (Register Read/Write)
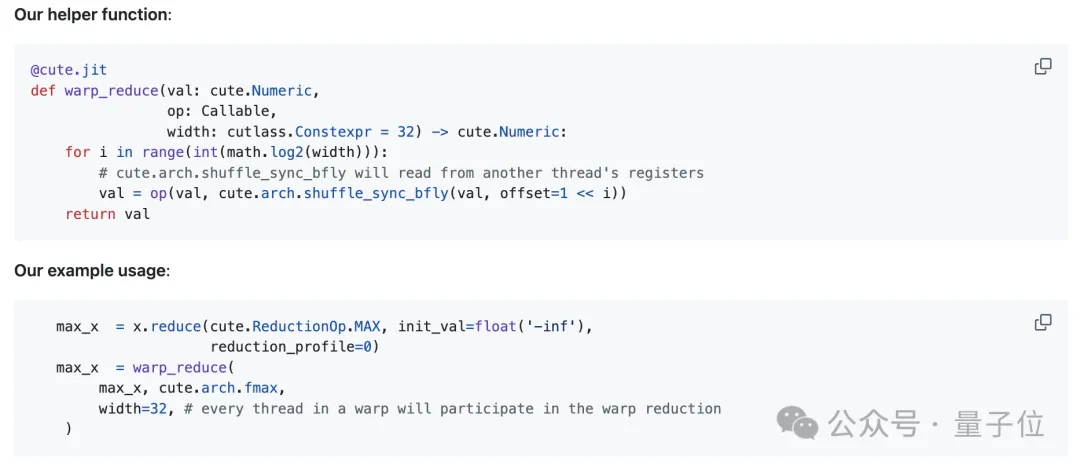
A warp is a fixed group of 32 contiguous threads that execute the same instructions per cycle. Synchronous warp reduction allows each thread within the same warp to read another thread’s register via a dedicated shuffle network in a single cycle. After butterfly warp reduction, every thread in the same warp obtains the reduced value.
The author defines an auxiliary function warp_reduce to execute warp reductions in a “butterfly” order. For detailed explanations of warp-level primitives, readers are referred to Yuan and Vinod’s CUDA blog post, “Using CUDA Warp-Level Primitives.”
Butterfly warp reduction, also known as “xor warp shuffle”:
3. Thread Block-Level Reduction (Shared Memory Read/Write)
A thread block typically contains multiple warps (up to 32 in the H100). In thread block reduction, the first thread of each participating warp writes that warp’s reduction result into a pre-allocated reduction buffer in shared memory.
After a thread block-level synchronization barrier ensures all participating warps have finished writing, the first thread of each warp reads data from the reduction buffer and locally calculates the thread block’s final reduction result.

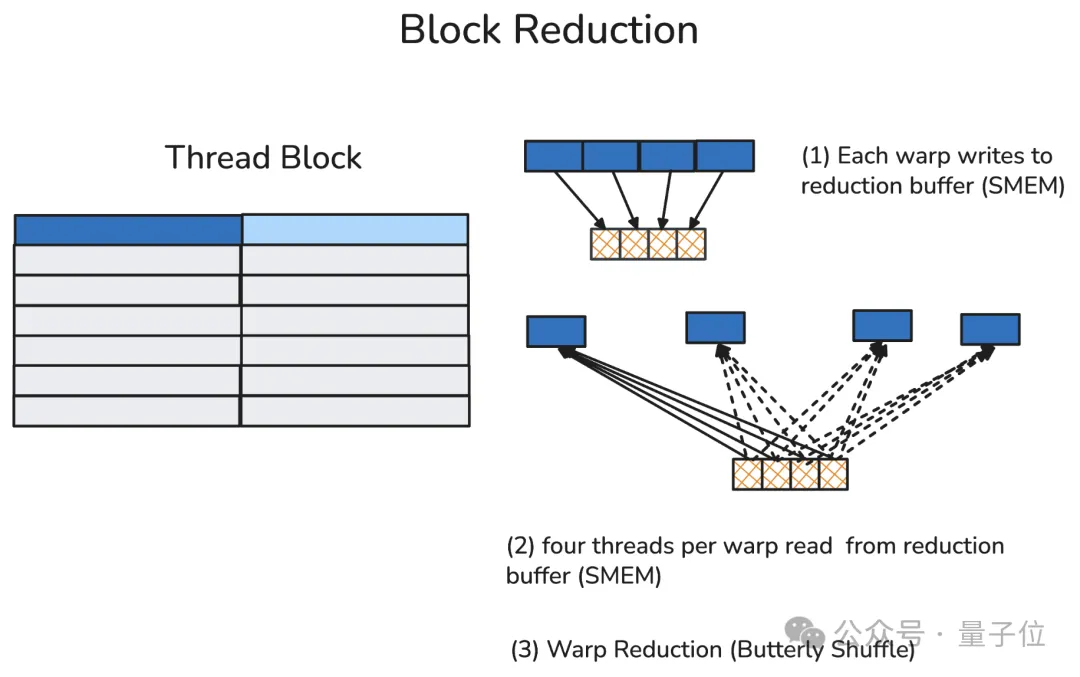
4. Cluster-Level Reduction (Distributed Shared Memory Read/Write)
Thread block clusters are a new execution level introduced in the Hopper architecture, consisting of a group of adjacent thread blocks (up to 16). Thread blocks within the same cluster communicate via Distributed Shared Memory (DSMEM), supported by a dedicated high-speed inter-SM network.
Within the same cluster, all threads can access shared memory from other SMs via DSMEM, where the virtual address space of shared memory is logically distributed across all thread blocks in the cluster. DSMEM can be accessed directly via simple pointers.
Distributed Shared Memory:
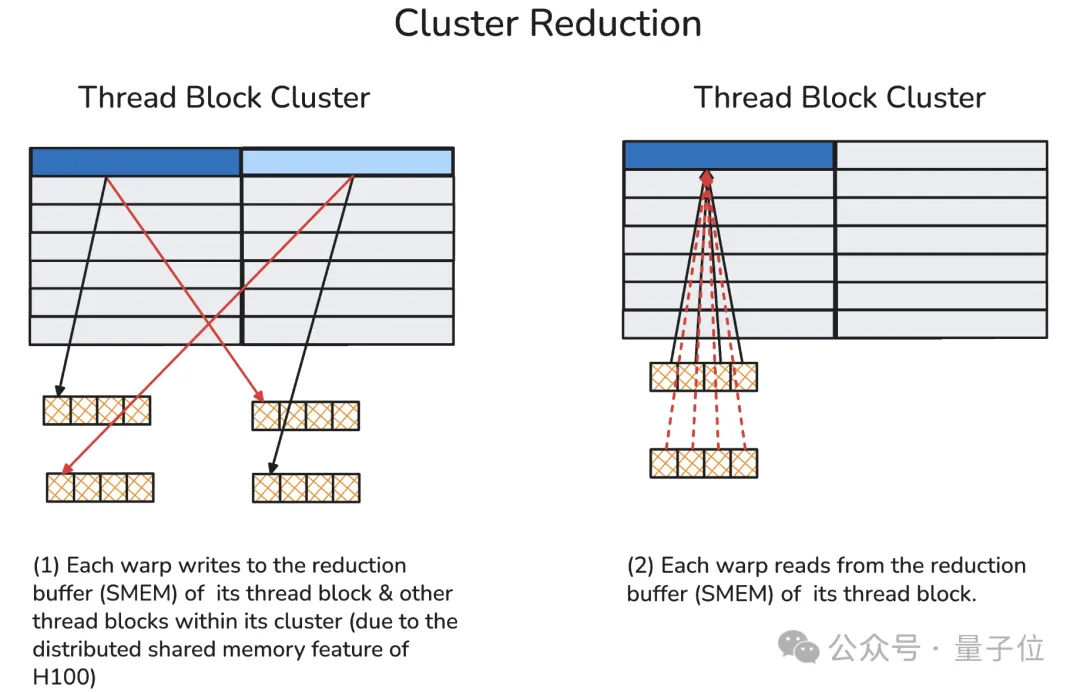
In cluster reduction, the author first sends the current warp’s reduction results to the shared memory buffers of peer thread blocks via the dedicated inter-SM network (i.e., DSMEM).
Subsequently, each warp retrieves values from all warps in its local reduction buffer and performs reduction on these values.
A memory barrier is also required here to count the number of data arrivals, preventing premature access to local shared memory (which would otherwise cause illegal memory access errors).


Viewing the entire reduction process as a whole: first, thread-level reduction is performed; then, results are aggregated within the same warp (i.e., warp-level reduction); finally, based on the number of reduction dimensions, reduced values are further propagated across each thread block or thread block cluster.
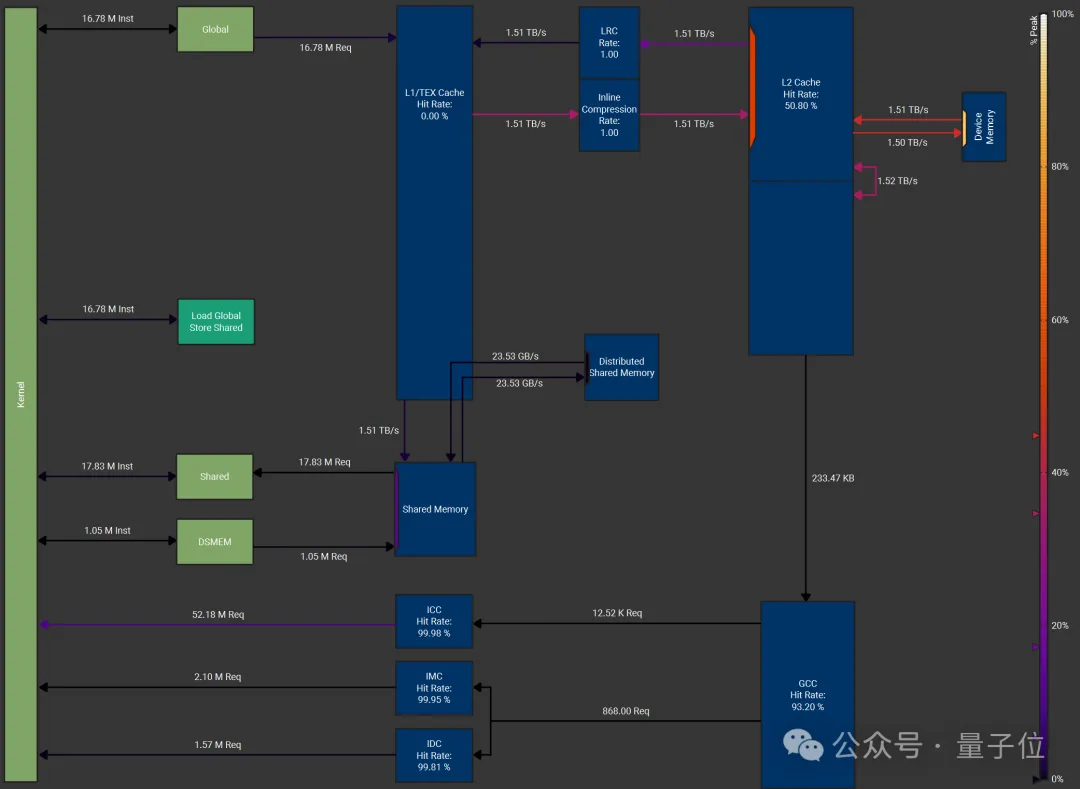
NCU Performance Analysis (Softmax Kernel)
The author conducted performance tests on a softmax kernel with a batch dimension of 16K and a reduction dimension of 131K on an NVIDIA H100 equipped with HBM3 memory (peak DRAM throughput = 3.35 TB/s). The memory workload graph was generated by Nsight Compute.
The configuration used was: thread block cluster size of 4, 256 threads per thread block, and FP32 input data type. Both load and store operations were vectorized, moving 128 bits of data (i.e., 4 FP32 values) per instruction.
The measured DRAM throughput, or memory bandwidth utilization, reached 3.01 TB/s, which is 89.7% of the peak DRAM throughput. In addition to shared memory (SMEM), Distributed Shared Memory (DSMEM) was also utilized efficiently.
The memory workload graph for this solution:
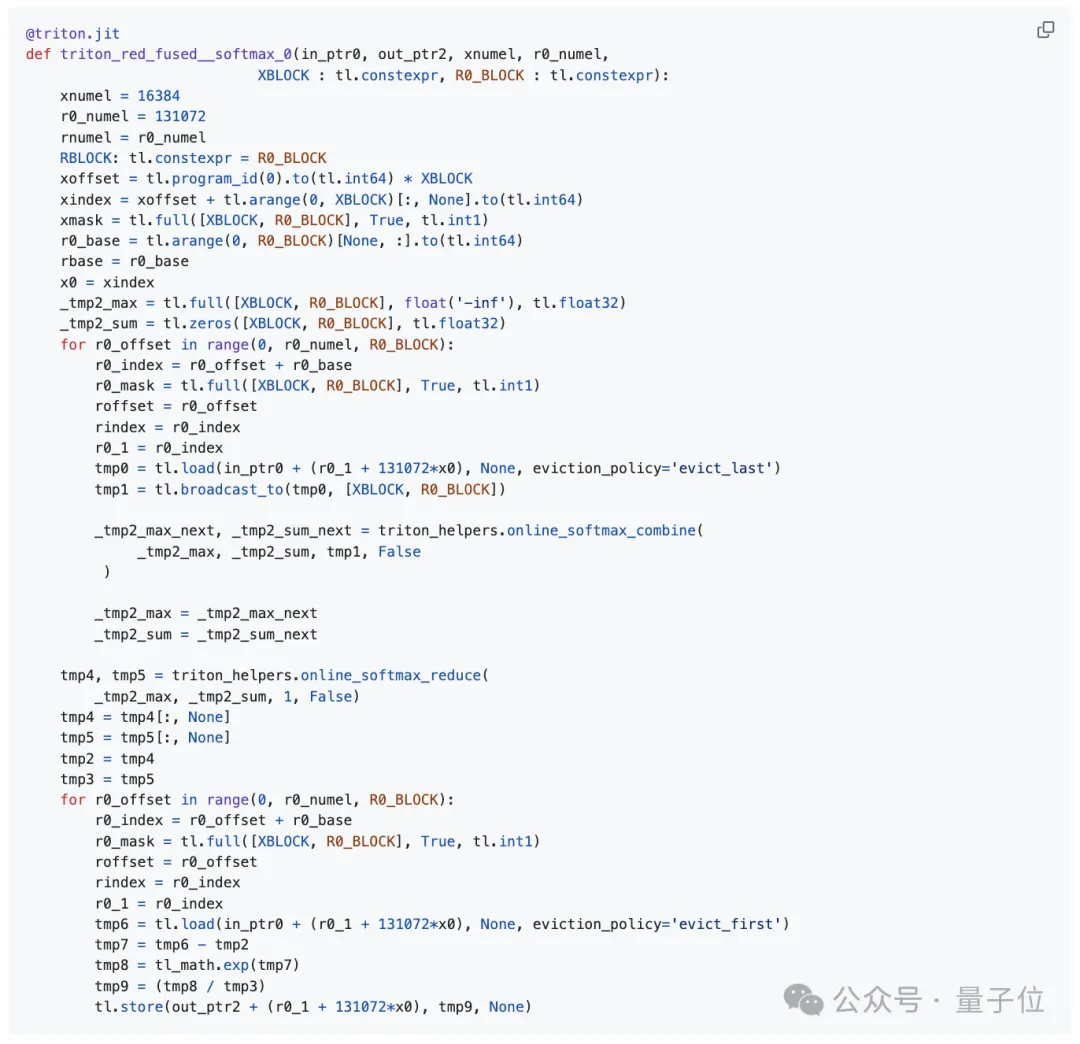
The author also compared their implementation with torch.compile (PyTorch version 2.7.1).
First, they obtained the Triton kernel code generated by torch.compile.
This kernel implementation of softmax includes two global memory loads (one each for calculating row maximums and partial exponential sums, plus one for the final softmax values) and one store operation.
In this scenario, although the Triton kernel still saturates the hardware’s DRAM throughput, the extra unnecessary load results in an effective model memory throughput for the Triton kernel (approximately 2.0 TB/s) being only two-thirds of that achieved by the author’s implementation (approximately 3.0 TB/s).
Triton kernel generated by torch.compile (tuning configuration section omitted):
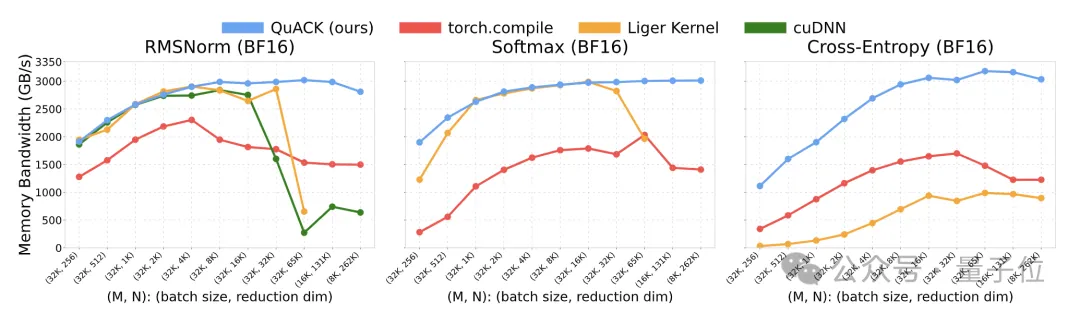
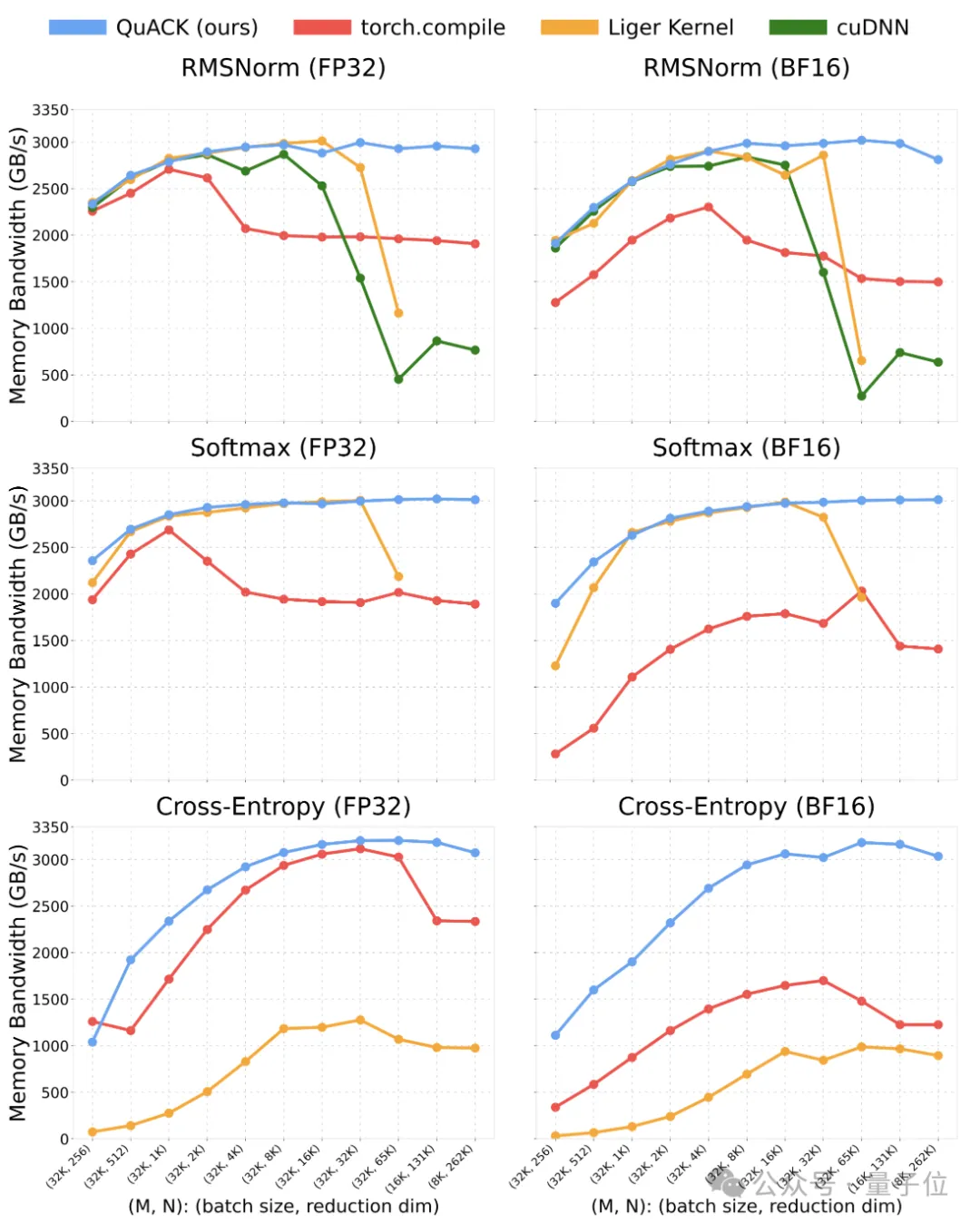
Memory Throughput
The author benchmarked several kernels, including RMSNorm, softmax, and cross-entropy loss. Tests were conducted on a single NVIDIA H100 80GB GPU with HBM3 memory and an Intel Xeon Platinum 8468 CPU.
The tested batch sizes ranged from 8k to 32k, reduction dimensions from 256 to 262k (256×1024), and input data types were FP32 and BF16.
The baseline comparison schemes were as follows:
- Torch.compile (PyTorch version 2.7.1): Used default compilation mode.
- Liger Kernels v0.5.10: Only RMSNorm and softmax were tested, with reduction dimensions capped at 65k (as it currently does not support larger dimensions).
- cuDNN v9.10.1: Only the RMSNorm kernel was tested.
The author’s implementation based on CuTe DSL generally maintained a stable memory throughput of around 3 TB/s (approximately 90% of peak) when reduction dimensions exceeded 4k.
At a reduction dimension of 262k, FP32 softmax throughput reached 3.01 TB/s, whereas torch.compile achieved only 1.89 TB/s, making the author’s approach nearly 50% faster. For these three kernels, when reduction dimensions are ≥65k, this implementation significantly outperforms all baseline schemes.
Model memory throughput for multiple kernels:
The author attributes the excellent performance at input sizes ≥65k to successful
leveraging cluster reduction in H100**.
When the input data volume is large enough to saturate a Streaming Multiprocessor’s (SM) registers and shared memory, failing to use cluster reduction forces a switch to online algorithms (such as online softmax). Otherwise, significant register spillover occurs, leading to a substantial drop in throughput.
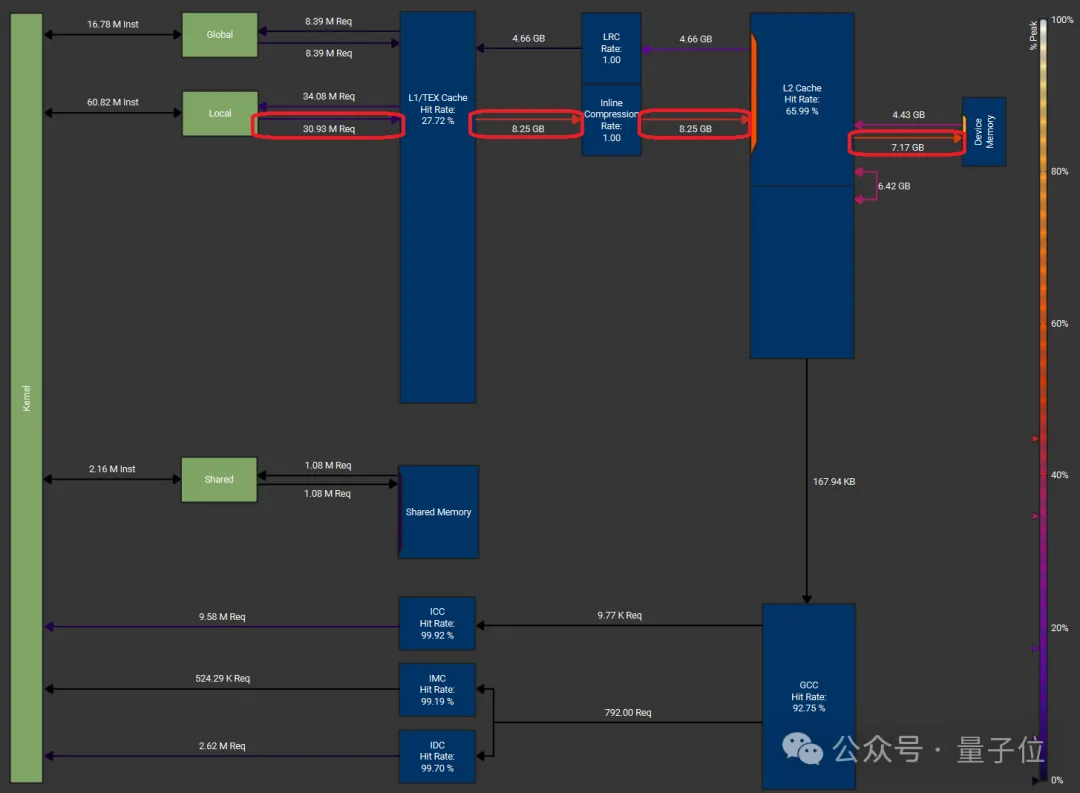
For example, the authors observed that when using the Liger softmax kernel, increasing the input size from 32k to 65k caused throughput to plummet from approximately 3.0 TB/s to around 2.0 TB/s.
Using NCU (Nsight Compute) tools to analyze its memory load profile and SASS code, the authors found that when each SM had to load 65k data points, the SM’s resources were exhausted. This resulted in massive register spillover and frequent writes back to HBM, which slowed down performance.
Memory workload of the Liger softmax kernel with a batch dimension of 16k, reduction dimension of 65k, and FP32 data type:
Register spillover (LDL instruction) in the Liger softmax kernel assembly code:

However, cluster reduction allows multiple SMs to collaborate and share resources, effectively forming a “super” SM (enabled by DSMEM).
Assuming a single SM can only handle 32k inputs, a cluster of size 16 would allow processing 500k (0.5M) inputs without reloading data from global memory (GMEM).
Thanks to the authors’ clear understanding of hardware architecture, even using a standard three-pass softmax algorithm, they were able to fully utilize every byte across all memory hierarchy levels, achieving “light-speed” throughput.
Summary
The authors demonstrated through practice that by carefully hand-writing CuTe kernels, it is possible to extract the full potential of all memory hierarchy levels in hardware, achieving “light-speed” memory throughput.
However, this efficiency comes at the cost of tuning for each operator and even each input shape, creating a natural trade-off between performance and development costs.
Phil Tillet (author of Triton) illustrated this point well with an image in his presentation.
Based on the authors’ experience using CuTe-DSL, it combines the development efficiency of Python with the control capabilities and performance of CUDA C++.
The authors believe that efficient GPU kernel development workflows can be automated.
For instance, the input tensor TV layout, load/store policies, and reduction helper functions used in RMSNorm can be directly applied to softmax kernels while still achieving comparable throughput.
Furthermore, CuTe DSL provides developers or other code running on top of CuTe DSL with flexible GPU kernel development capabilities.
Currently, applying large language models to automatically generate GPU kernels is an active area of research. In the future, it may be possible to simply call “LLM.compile” to generate highly optimized GPU kernels.
About the Authors
This work has three authors.
Wentao Guo
Wentao Guo is currently a Ph.D. student in Computer Science at Princeton University, advised by Tri Dao.
Prior to this, he earned his undergraduate and master’s degrees in Computer Science from Cornell University.
Ted Zadouri
Ted Zadouri is also a Ph.D. student in Computer Science at Princeton University, having received his bachelor’s and master’s degrees from the University of California, Irvine, and the University of California, Los Angeles, respectively.
Previously, Ted interned at Intel and conducted research on parameter-efficient fine-tuning for large language models at Cohere.

Tri Dao
Tri Dao is currently an Assistant Professor of Computer Science at Princeton University and Chief Scientist at the generative AI startup Together AI.
He is renowned in academia for a series of works optimizing the attention mechanism in Transformer models.
Most notably, as one of the authors, he proposed the Mamba architecture, which has achieved state-of-the-art (SOTA) performance across various modalities including language, audio, and genomics.
In particular, regarding language modeling, the Mamba-3B model outperforms Transformers of similar scale in both pre-training and downstream evaluations, rivaling Transformers twice its size.
Additionally, he co-authored FlashAttention versions 1 through 3. FlashAttention is widely used to accelerate Transformers, improving attention speed by 4 to 8 times.
GitHub link: https://github.com/Dao-AILab/quack/blob/main/media/2025-07-10-membound-sol.md