Thanks to OpenAI (doge).
Right around the time GPT-5.5 was released, Claude admitted:
The performance degradation is real; all usage quotas have been reset.
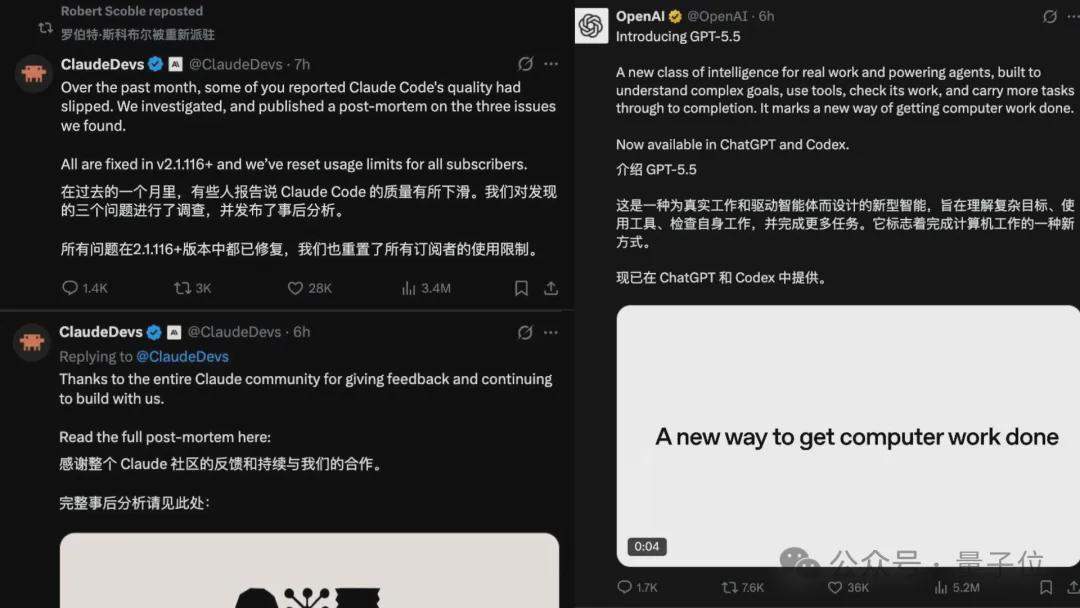
After denying it for over a month, this “intelligence drop” bug finally spilled out from Anthropic itself:
- Reasoning level was secretly downgraded from “High” to “Medium.”
- A caching bug caused thinking records to be cleared every turn.
- A 25-word limit in system prompts degraded output quality.
With these three bugs stacking up, the user experience for Claude plummeted.
Fortunately, competitors applied timely pressure today; educating users is ultimately not a viable strategy.
That said, while updates with bugs are good news in principle, the timing is too coincidental: GPT-5.5 just launched, and Claude immediately started “admitting defeat.”
Could it be that 5.5 helped debug?
Dario, you didn’t intentionally make Claude dumber to look good when GPT-5.5 was released, did you?
The bugs are confirmed: there were three.
First off, this isn’t the first time.
Last August, Anthropic released a similar postmortem on performance degradation affecting Opus 4.0 and 4.1, with official statements claiming, “We never intentionally lowered model quality.”
The title of this new postmortem is “A postmortem of three recent issues.” The word “recent” makes the meaning clear.
Not just now, but recently.

The reason it’s “recent” is that the community has been complaining about Claude’s performance drop for a long time.
More than ten days ago, Stella Laurenzo, Senior Director of AMD AI, published a rigorous audit report on GitHub covering 6,852 session files, 17,871 thinking blocks, and over 230,000 tool calls.
The analysis showed that starting in February, the model’s reasoning depth experienced a cliff-like decline.
More detailed findings revealed that Claude began falling into reasoning loops and showed a clear tendency to choose “the simplest fix” rather than the correct one.
BridgeMind’s BridgeBench tests also exploded during this period; Opus 4.6’s accuracy dropped from 83.3% to 68.3%, causing its ranking to fall from #2 to #10.
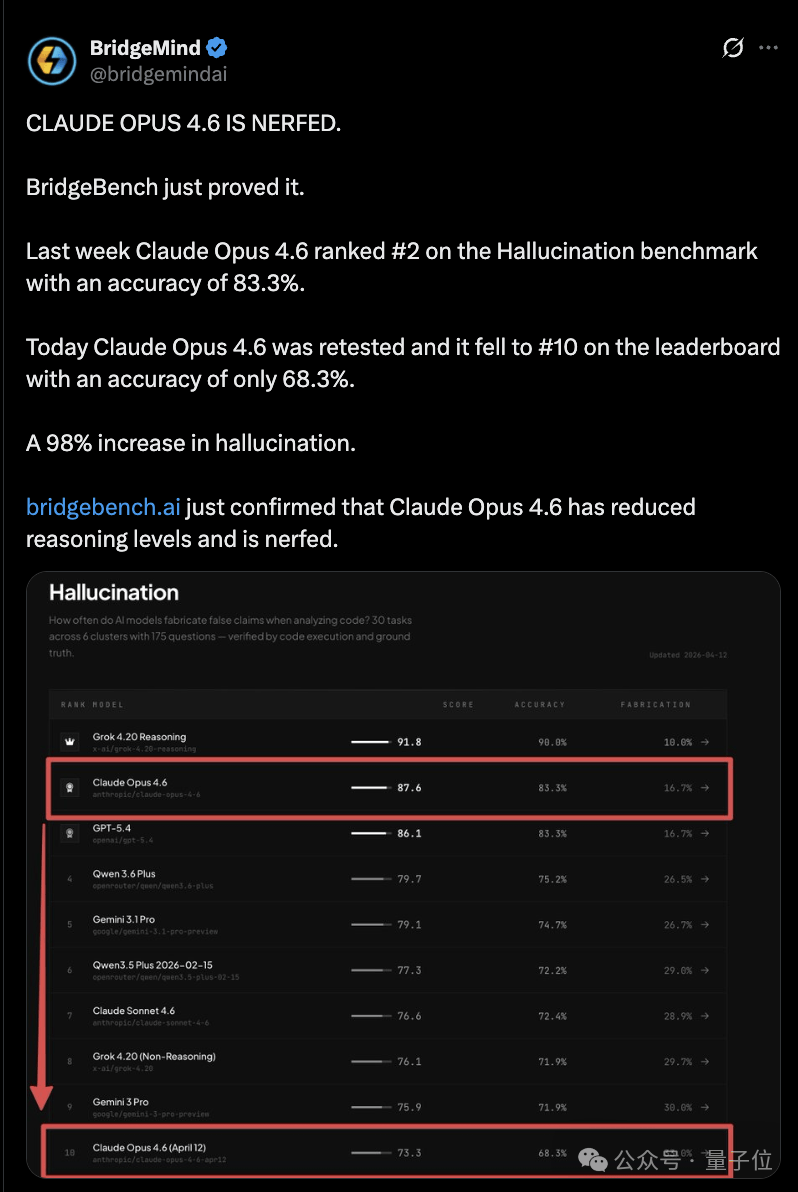
Although researchers later criticized the methodology, noting that the number of tasks in pre- and post-tests was completely different, the narrative that “Claude has become stupid” had already spread.
Netizens even coined a new term: AI shrinkflation. For the same price, you receive a diluted product.
In other words, everyone bought Anthropic’s “children’s meal.”
But there was no way around it; Claude was indeed unbeatable at the time. Many users complained while continuing to use it, with little recourse.
It wasn’t until GPT-5.5 launched that Anthropic could no longer sit still. They published a postmortem on their official blog, breaking down the “intelligence drop” of the past two months into three independent issues:
Secretly downgrading reasoning levels.
On March 4, Claude Code’s default reasoning was changed from High to Medium due to high latency in High mode. However, the interface still displayed “High.” Users thought they were using the full-power version but actually received a downgraded product. It wasn’t rolled back for over a month.
Getting dumber with every chat.
On March 26, a caching optimization was deployed, intended to clear old thinking records after sessions had been idle for more than an hour. However, due to a code bug, the clearing action executed on every turn.
Claude continued working but gradually forgot why it was doing so. Symptoms of this bug included forgetfulness, repetition, and erratic tool calls. Furthermore, because thinking records were repeatedly cleared, cache misses occurred with every request, causing token consumption to skyrocket. It took 15 days to fix.
One prompt line ruined output quality.
On April 16, a system prompt was added: “Text between tool calls must not exceed 25 words; final responses must not exceed 100 words.”
Both Opus 4.6 and 4.6 saw a 3% performance drop, leading to a rollback four days later.
These three issues affected different user groups at different times. The cumulative effect was that Claude Code continuously deteriorated unevenly, but no one could pinpoint exactly what went wrong.
On Twitter, the official account @ClaudeDevs posted a summary, and Boris Cherny, known as the “father of Claude,” personally replied in the comments, previewing that bugs in Opus 4.7 are also being fixed.
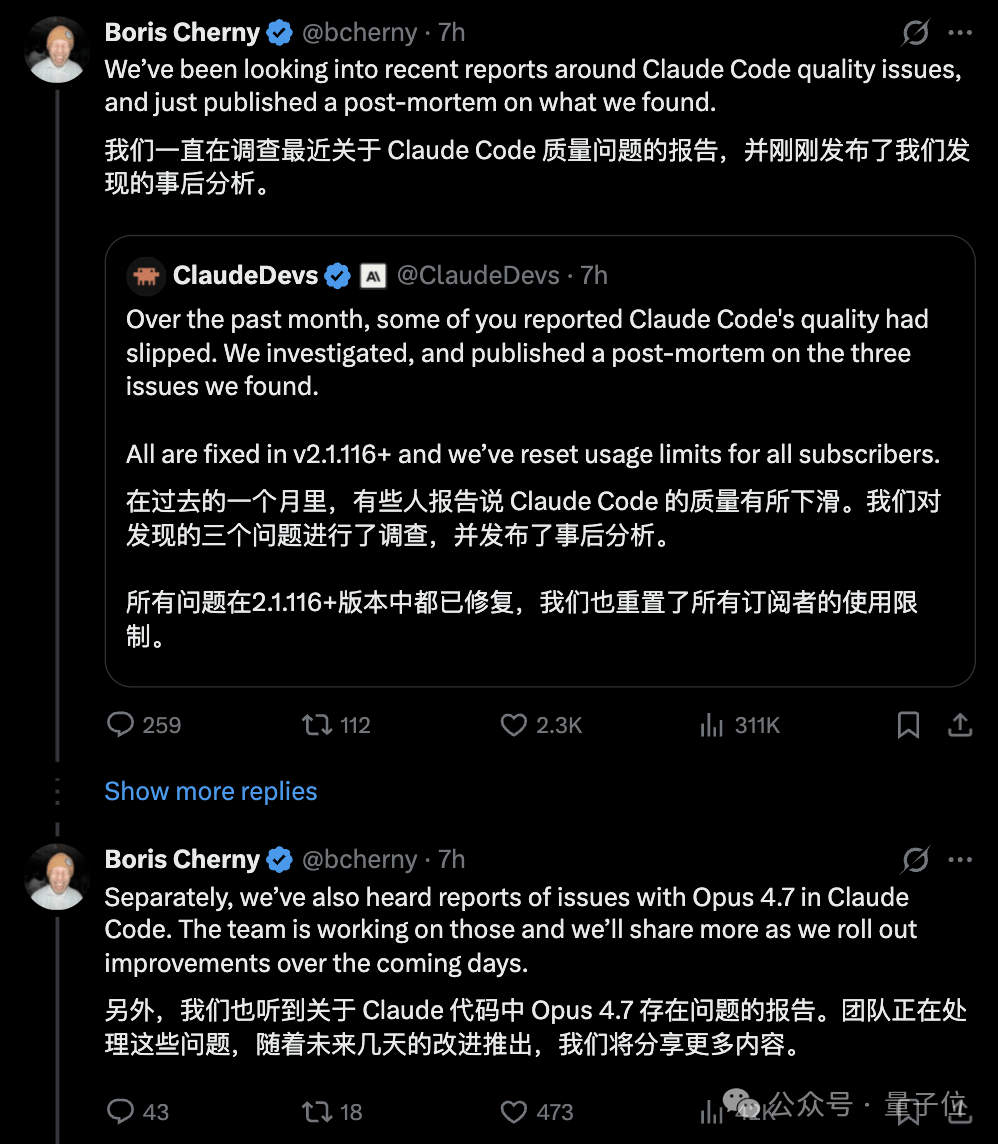
But the problem is that bug fixes alone don’t explain everything that happened over these two months.
April: Anthropic’s series of self-inflicted blows
Looking at the timeline, April was essentially three consecutive punches to Anthropic’s own face.
On April 4, Anthropic banned third-party agentic tools like OpenClaw from running via Pro/Max subscriptions. Want to keep using them? Switch to API pay-per-token pricing.
On April 21, the official pricing page quietly removed Claude Code from the Pro plan, and support documentation changed from “Pro or Max plan” to “Only Max plan.”
After being caught by netizens, Head of Growth Amol Avasare claimed this was merely an A/B test for 2% of new users. However, the public-facing pages were updated site-wide, creating a complete contradiction in messaging. They rolled back hours later, embarrassed.
Doing the math: Pro is $20/month ($240/year). To continue using Claude Code, you must upgrade to Max starting at $5x, or $100/month ($1,200/year)—five times the cost. Max 20x is $2,400—ten times the cost. There are no intermediate tiers.
Note that these figures are in USD.
On April 23, today, the postmortem went live, with compensation being a reset of usage quotas.
Netizens pointed out bluntly that usage quotas had already been reset once when Opus 4.7 was released last week; thus, this “compensation” is essentially just a normal periodic reset.
Linking these three events together, the flavor isn’t just bugs—it’s an explosion of cost anxiety.
Netizens are not buying it
Given all this, reactions to Claude among netizens have begun to diverge.
Some believe that having bugs is understandable and that the postmortem was relatively transparent. Boris replied one-by-one on Hacker News, which is better than what most companies do.

But more people are calculating another bill.
During these two months, all official channels remained silent.
Only a few employees responded sporadically on X (formerly Twitter), and they were criticized for “random replies at random times,” lacking any systematic approach.

Others question the true motive behind the “caching optimization.” The trigger time for clearing thinking records coincided exactly with cache expiration nodes; some suspect this wasn’t to reduce latency, but to cut costs.
Simultaneously, Anthropic conducted A/B tests on a small subset of Pro users, quietly providing different product configurations, dealing another blow to trust.

The compensation measure was resetting usage quotas. Some bluntly pointed out that quotas had already been reset once when Opus 4.7 was released last week.
BridgeMind’s BridgeBench tests also exploded during this period, showing Opus 4.6’s accuracy dropping from 83.3% to 68.3%, with its ranking falling from #2 to #10.
Although researchers later criticized the methodology due to differing task counts in pre- and post-tests, the narrative that “Claude has become stupid” had already spread.
As one netizen said, you can’t put all your eggs in one model company’s basket.

One more thing
An interesting phenomenon in the Hacker News comments section is that many are discussing their “migration experiences.”
Some said they had “subconsciously” switched to Codex back in February, only realizing recently that they were likely forced by Claude’s declining performance.

Others stated that GPT-5.4 is already better than Opus 4.6.

Some are using MiniMax as a supplement: $40 for 4,500 messages in a 5-hour cycle, with the ability to view the full thinking process.

Half a year ago, “use Claude for coding” was almost consensus.
Now, Codex has 4 million active users. GPT-5.5 focuses heavily on coding and computer operation capabilities; even OpenAI staff directly stated that this model can be used as a “Chief of Staff.”
Claude hasn’t necessarily gotten worse. Others have gotten better, while Claude failed at the worst possible time.
The window for Anthropic to fix bugs and rebuild trust has narrowed significantly compared to two months ago.
GPT-5.5 is already released; DeepSeek V4 is firmly in place.
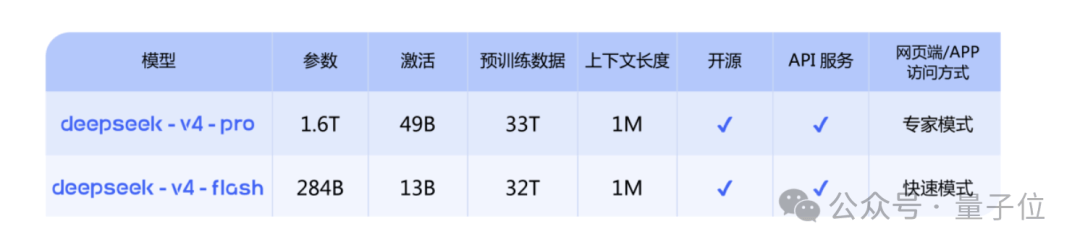
Gemini, come on! We’re just waiting for you.
References
- An update on recent Claude Code quality reports — Anthropic is an AI safety and research company that’s working to build reliable, interpretable, and steerable AI systems.
- An update on recent Claude Code quality reports | Hacker News — news.ycombinator.com/item