At the ACL 2025 awards ceremony, a paper co-authored by Liang Wenfeng of DeepSeek as the corresponding author and jointly published with Peking University and other institutions was awarded Best Paper.
ACL 2025 saw unprecedented scale, with total submissions reaching 8,360—nearly double last year’s 4,407—resulting in exceptionally fierce competition.

In simple terms, their proposed Native Sparse Attention (NSA) mechanism boosts long-text processing speed by 11 times through synergistic optimization of algorithms and hardware. Remarkably, performance not only remained stable but surpassed that of traditional full attention models.
First author Yuan Jingyang presented the work at the conference, revealing that this technology can extend context length to one million tokens and will be applied to the next frontier model.
Given that the paper was published after the release of DeepSeek-R1, the experimental setup also noted that new models were fine-tuned using distillation data from DeepSeek-R1.
This has led to widespread speculation that the technology will be integrated into the next-generation DeepSeek-V4 and DeepSeek-R2.
Slimming Down Attention Mechanisms, Speed Surges by 11x
For a long time, processing long texts with large language models has been like dancing in shackles. The computational complexity of traditional full attention mechanisms grows quadratically with sequence length; when handling text of 64k length, attention calculations account for 70-80% of total latency.
The solution proposed in this paper is ingenious: since not all word relationships are equally important, why not teach the model to “focus on the key points”?
NSA employs a dynamic hierarchical sparse strategy, operating through three parallel attention branches working in synergy:
- Compressed Attention, responsible for capturing coarse-grained global information patterns, akin to quickly scanning the entire text to grasp the main idea;
- Selective Attention, which focuses on the most important word blocks within the sequence, equivalent to carefully reading key paragraphs;
- Sliding Attention, tasked with acquiring local contextual information to ensure no details are lost.
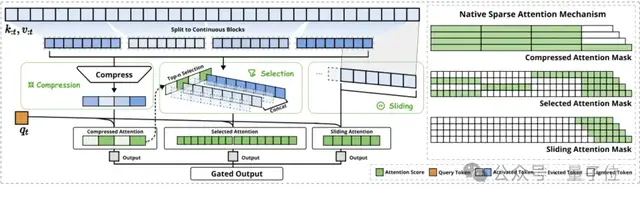
The most ingenious aspect of this design is that it does not simply discard information but balances computational density through carefully designed algorithms.
More importantly, the entire architecture has been deeply optimized for modern GPU hardware, achieving an end-to-end natively trainable mode.
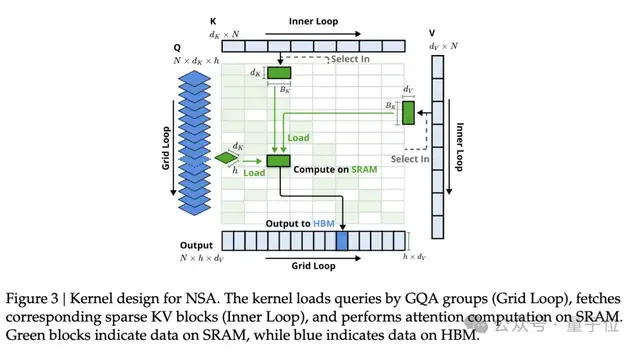
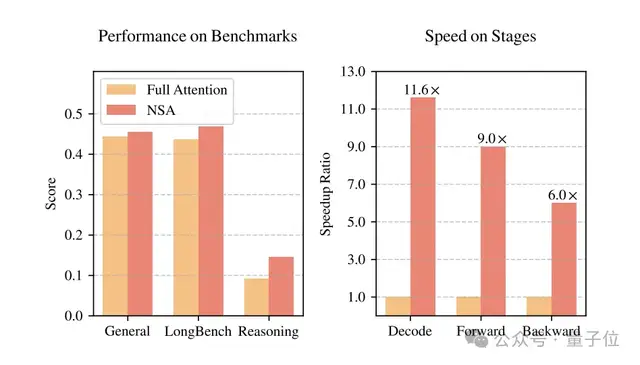
In practical tests, when processing sequences of 64k length, NSA demonstrated astonishing speed advantages throughout the entire lifecycle of decoding, forward propagation, and backward propagation.
Decoding speed increased by 11.6 times, forward propagation by 9 times, and backward propagation saw a 6x acceleration, delivering tangible efficiency gains for both model inference and training.
Faster and More Accurate: A New Breakthrough in Long-Text Processing
Speed is only one side of NSA; what is even more surprising is its performance across various benchmark tests.
In general benchmarks, a 27B parameter model pre-trained with NSA outperformed the full attention baseline in 7 out of 9 evaluation metrics. Particularly in reasoning-related benchmarks, DROP improved by 0.042 and GSM8K by 0.034, highlighting the unique advantage of sparse attention in forcing models to focus on key information.
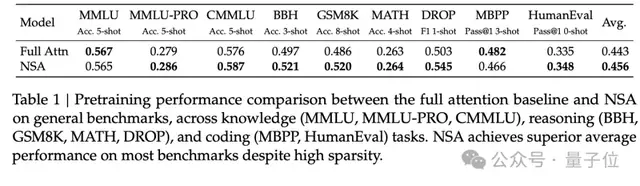
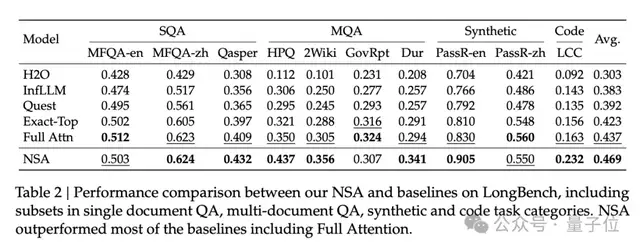
Results for long-text processing capabilities were particularly bright. In the “needle in a haystack” test with 64k context, NSA achieved perfect retrieval accuracy at all positions. On the LongBench benchmark, NSA scored an average of 0.469, surpassing the full attention baseline (+0.032) and significantly leading other sparse attention methods.

Notably, in multi-hop question answering tasks requiring complex reasoning, NSA improved by 0.087 (HPQ) and 0.051 (2Wiki) compared to full attention; it increased by 0.069 in code understanding tasks (LCC); and by 0.075 in passage retrieval tasks (PassR-en).
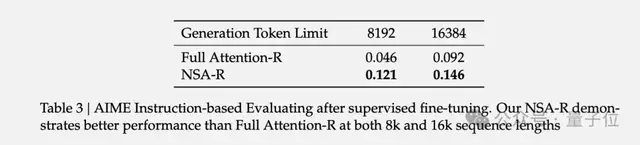
The research team also conducted an interesting experiment:
They fine-tuned the model using mathematical reasoning data from DeepSeek-R1 and then tested it on the American Invitational Mathematics Examination (AIME 24).
The results showed that NSA-R achieved an accuracy of 0.121 under an 8k context setting, whereas the full attention model only reached 0.046; even at 16k context, NSA-R maintained an accuracy of 0.146, far exceeding the full attention model’s 0.092.
These results fully demonstrate that NSA does not sacrifice performance for speed but truly achieves a win-win situation in both efficiency and capability.
Three More Things
A total of four Best Papers were awarded this year. The other three include:
“Language Models Resist Alignment: Evidence From Data Compression” by the Peking University team.
This study investigates the “elasticity” of large language models, referring to how easily models revert to their pre-training states after subsequent fine-tuning, despite having undergone alignment training (to align with human values and reduce harmful outputs), much like a stretched spring snapping back.
This implies that current alignment methods may only superficially alter models without being robust. Future efforts require more effective alignment techniques to ensure models stably meet human needs, particularly in open-source models where malicious fine-tuning could easily compromise safety mechanisms.

“Fairness through Difference Awareness: Measuring Desired Group Discrimination in LLMs” by the Stanford team.
This paper explores a new perspective on “fairness” in large models: “difference awareness.” Simply put, models should make distinctions between different groups in appropriate scenarios rather than treating everything uniformly.
The study found that models performing well in traditional fairness tests did not score high on “difference awareness”; while stronger model capabilities (e.g., higher MMLU scores) correlated with better situational awareness, they did not necessarily improve difference awareness; existing “de-biasing” methods (such as prompting the model to “remain unbiased”) actually caused models to ignore differences more, even misidentifying correct answers.
“A Theory of Response Sampling in LLMs: Part Descriptive and Part Prescriptive” by the Helmholtz Information Security Center team and others.
This paper points out that the sampling mechanism used by large models when generating responses is similar to human decision-making, containing descriptive components (reflecting statistical norms of concepts) and prescriptive components (implying ideal states of concepts).
Experiments verified that whether dealing with novel or existing concepts (covering 500 concepts across 10 domains), samples generated by LLMs deviate from statistical averages toward their perceived “ideal values,” a phenomenon significantly present across 15 different models. Case studies suggest this bias could lead to skewed decisions in fields like healthcare, raising ethical concerns.

Link to the DeepSeek paper:
https://arxiv.org/abs/2502.11089
References
1950572483637067786. 1950572483637067786 — x.com/aclmeeting/status/1950572483637067786 1950649481617342803. 1950649481617342803 — x.com/casper/hansen//status/1950649481617342803