ByteDance’s Latest Deep Thinking Model: Does It Surpass DeepSeek-R1 in Math, Code, and Other Reasoning Tasks with Fewer Parameters?
Adopting the same Mixture of Experts (MoE) architecture as its competitor, ByteDance’s new model, Seed-Thinking-v1.5, features 200 billion total parameters and 20 billion activated parameters.
In comparison to DeepSeek-R1’s 671 billion total parameters and 37 billion activated parameters, this represents a significantly more lightweight design.
The complete technical report has been publicly released, revealing many of the secrets behind its performance.
The ByteDance Seed team focused on large-scale reinforcement learning (RL), improving reasoning capabilities from three key angles: data, RL algorithms, and RL infrastructure.

Verifiable vs. Unverifiable Problems
Starting with data, the ByteDance team divided RL training data into two categories: verifiable problems, which have clear-cut answers, and unverifiable problems, which do not. Different reward modeling methods were applied to each.
Notably, the model’s reasoning capabilities primarily stem from verifiable problems but can be generalized to unverifiable ones.
Verifiable problems include STEM questions with paired question-answer sets, coding problems accompanied by unit tests, and logical reasoning tasks suitable for automated verification (such as the 24-point game, mazes, and Sudoku).
Unverifiable problems mainly consist of non-reasoning tasks evaluated based on human preference, such as creative writing, translation, knowledge-based QA, and role-playing.
For unverifiable problems, the ByteDance team discarded data with low sample score variance and low difficulty. Such data may be too simple or already heavily represented in the dataset. Offline experiments indicated that over-optimizing for these samples could cause the model’s exploration space to collapse prematurely, thereby reducing performance.
Additionally, the team developed a new mathematical reasoning benchmark called BeyondAIME.
Current reasoning models typically use AIME as their primary benchmark for evaluating mathematical reasoning capabilities. However, since only 30 problems are released annually, its limited scale can lead to high-variance evaluation results, making it difficult to effectively distinguish between state-of-the-art reasoning models.
ByteDance collaborated with math experts to develop original questions based on established competition formats. Existing competition problems were systematically adjusted through structural modifications and scenario reconfiguration to ensure no direct duplication occurred. Furthermore, the team ensured that answers were not easily guessable numerical values (e.g., numbers explicitly mentioned in the problem statement) to reduce the likelihood of models guessing correctly without proper reasoning.
RL Algorithms
While reinforcement learning is powerful, it is also unstable during training and prone to collapse.
The technical report notes, “Sometimes, score differences between two runs can be as high as 10 points.”
To address this issue, the team proposed two RL frameworks: VAPO and DAPO, which stabilize training from value-based and value-free RL paradigms, respectively.
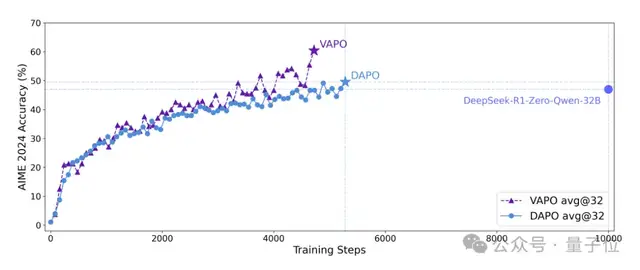
Papers detailing VAPO and DAPO have been published separately.


Furthermore, Seed-Thinking-v1.5 incorporates several key technologies from previous academic research:
- Value Pre-training: Ensures consistency between the value network and the policy network.
- Decoupled GAE (Generalized Advantage Estimation): Makes the two networks more independent and efficient.
- Length-adaptive GAE: Better handles sequences of varying lengths.
- Decoupled PPO Loss (Clip-Higher): Creates more room for low-probability tokens to grow, encouraging the model to explore new solutions.
- Token-level Loss: Balances the impact of each token on the training process.
- Positive Example LM Loss: Improves the utilization efficiency of positive samples during RL training, thereby enhancing overall model performance.

RL Infrastructure
During the Long Chain-of-Thought (Long-CoT) generation process, the ByteDance team observed significant variations in response lengths across different prompts, leading to substantial GPU idle time during generation.
To mitigate latency issues associated with generating long-tail responses, they proposed SRS (Streaming Rollout System), a resource-aware scheduling framework that strategically deploys independent streaming computing units, shifting system constraints from memory-bound to compute-bound.
For effective large-scale training, the team also designed a hybrid distributed training framework integrating advanced parallel strategies, dynamic workload balancing, and memory optimization:
- Parallel Mechanisms: Combines Tensor Parallelism (TP), Expert Parallelism (EP), and Context Parallelism (CP) with Fully Sharded Data Parallelism (FSDP). Specifically, TP/CP is applied to attention layers, while EP is applied to MoE layers.
- Sequence Length Balancing: Effective sequence lengths may be unbalanced across Data Parallel (DP) ranks, leading to uneven computational workloads and reduced training efficiency. The KARP algorithm was utilized to rearrange input sequences within a mini-batch, ensuring balance across micro-batches.
- Memory Optimization: Employs layer-wise recomputation, activation offloading, and optimizer offloading to support larger micro-batch sizes, thereby offsetting communication overhead caused by FSDP.
- Automatic Parallelism: To achieve optimal system performance, an AutoTuner system was developed that models memory usage based on profiled solutions. It then estimates the performance and memory consumption of various configurations to identify the optimal setup.
- Checkpoints: Utilizes ByteCheckpoint to support checkpoint recovery from different distributed configurations with minimal overhead, enabling resilient training to improve cluster efficiency.

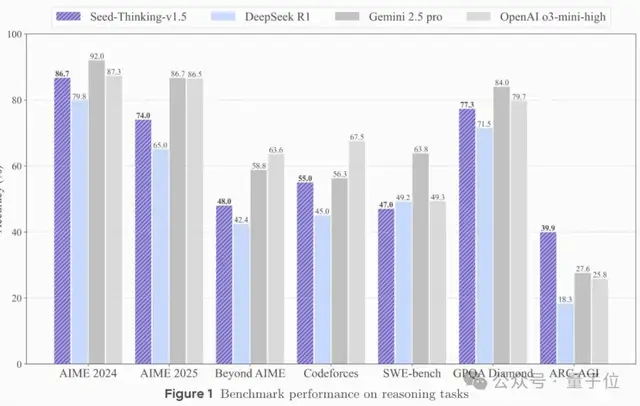
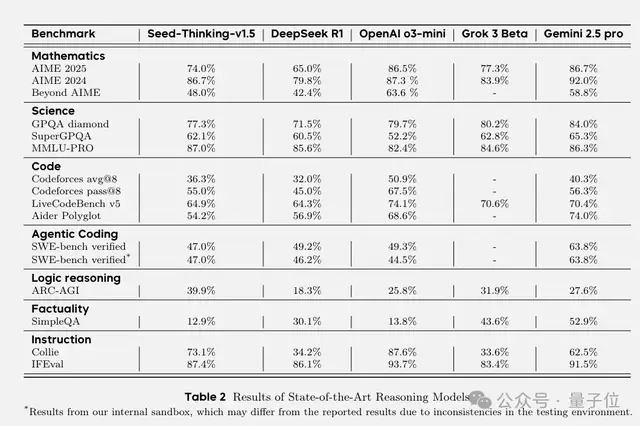
Ultimately, in multiple automated evaluations, Seed-Thinking-v1.5 achieved a score of 86.7 on the AIME 2024 benchmark, performing comparably to OpenAI’s o3-mini-high model. However, on recent benchmarks such as AIME 2025 and BeyondAIME, Seed-Thinking-v1.5 still trails behind o3-level performance.
For the GPQA task, Seed-Thinking-v1.5 achieved an accuracy of 77.3%, approaching the performance of o3-mini-high.
In code generation scenarios such as Codeforces, Seed-Thinking-v1.5 performed comparably to Gemini 2.5 Pro but still lagged behind o3-mini-high.
Seed-Thinking-v1.5’s performance on SimpleQA was less impressive. However, the team believes this benchmark correlates more strongly with pre-training model scale rather than testing reasoning capabilities specifically.
Many readers interested in this technical report have searched extensively but failed to locate where the model is available for release.
According to the technical report, this model is distinct from Doubao-1.5 Pro currently available in the Doubao app.
However, judging by the author list, it is a major project led by Wu Yonghui, head of ByteDance’s Seed team, with participation from key members.
Therefore, there is anticipation that it may be deployed to the Doubao App in the future.

References
Paper Address:
https://github.com/ByteDance-Seed/Seed-Thinking-v1.5/