AI doesn’t take weekends off, and neither does Silicon Valley.
On a grand Sunday, the Llama family welcomed new members: a group of Llama 4 models was released unexpectedly.
This marks Meta’s first model series based on the Mixture of Experts (MoE) architecture, currently comprising three variants:
Llama 4 Scout, Llama 4 Maverick, and Llama 4 Behemoth.
The last one has not yet been launched; it is merely teased. However, Meta has openly described the first two as “our most advanced models to date and the best multimodal models in their class.”
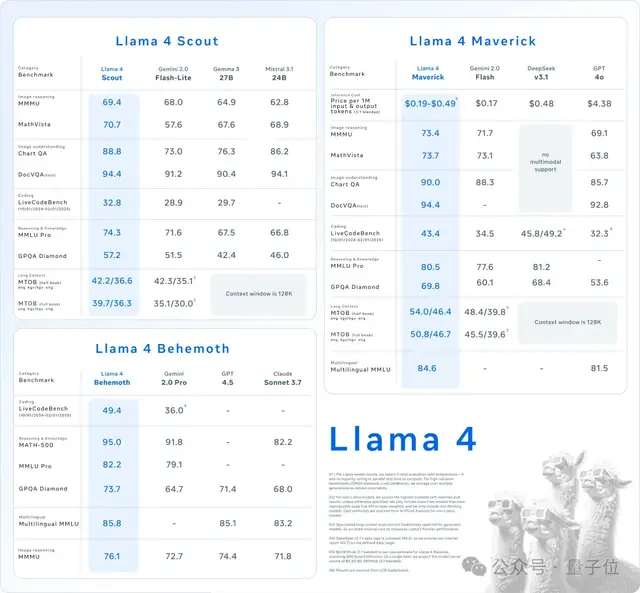
Here are some key details:
- Llama 4 Scout: A multimodal model with 17 billion activated parameters across 16 experts. It can run on a single H100 GPU, achieves state-of-the-art (SOTA) performance in its category, and features a 10M context window.
- Llama 4 Maverick: A multimodal model with 17 billion activated parameters across 128 experts. It outperforms GPT-4o and Gemini 2.0 Flash, matches DeepSeek-V3’s coding capabilities while requiring half the parameters, and emphasizes cost-effectiveness similar to DeepSeek. It can run on a single H100 host.
- Llama 4 Behemoth: A massive model with 2 trillion parameters. The previous two models were distilled from this one; it is currently in training and has surpassed GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on multiple benchmarks.
Meta’s official Twitter account enthusiastically stated that these Llama 4 models mark a new era for the Llama ecosystem—the beginning of native multimodal AI innovation.

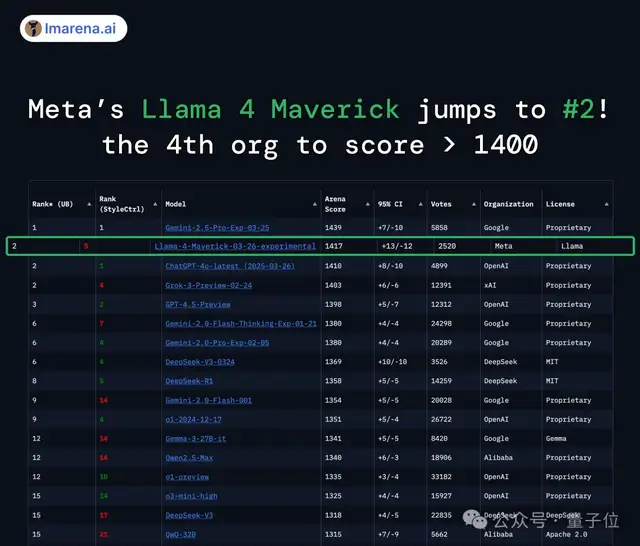
Meanwhile, rankings in large model arenas have seen an update.
The newly released Llama 4 Maverick ranks first in difficult prompting, coding, mathematics, and creative writing, scoring 1,417. This significantly surpasses Meta’s previous Llama-3-405B (an increase of 149 points) and makes it the fourth model in history to break the 1,400-point threshold.
The benchmark results are clear: it exceeds DeepSeek-V3, achieving the top spot upon release and directly becoming the number one open-source model.
Google CEO Sundar Pichai sent congratulations immediately:
The AI world is never dull!
Congratulations! Keep moving forward, Llama 4 team!
Small and Large Sizes Debuted First
After introducing all members of the Llama 4 family, let’s first look at the two models released in this initial batch:
- Small Size: Llama 4 Scout.
- Large Size: Llama 4 Maverick.
Both are now available for download on the Llama official website and Hugging Face.

We have extracted and summarized some key features of these two models:
Meta’s First MoE Architecture Models
This is the first time in the Llama series that models are built using the Mixture of Experts (MoE) architecture.
The small-sized Llama 4 Scout has 17 billion activated parameters with 16 expert models.
The large-sized Llama 4 Maverick has 17 billion activated parameters with 128 expert models.
As for the yet-to-be-released giant-sized Llama 4 Behemoth, it has 288 billion activated parameters and 16 expert models.
Extremely Long Context Windows
The entire Llama 4 series features exceptionally long context windows.
This is primarily reflected in the detailed data Meta released for the small-sized Llama 4 Scout:
Llama 4 Scout offers an industry-leading 1 million-token context window.
After pre-training and post-training, Llama 4 Scout has a base length of 256K tokens, giving the base model advanced length generalization capabilities.
This configuration allows it to outperform Gemma 3, Gemini 2.0 Flash-Lite, and Mistral 3.1 across a wide range of evaluation sets.

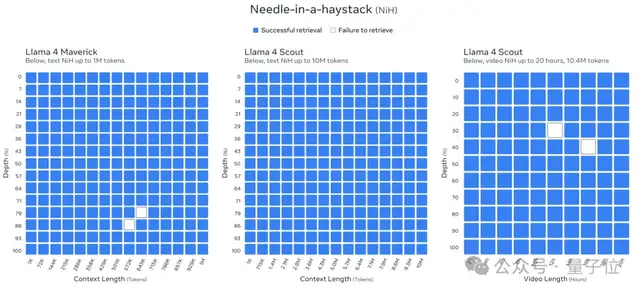
Its performance in “needle-in-a-haystack” tests is as follows:

The results are:
So, what were the context window sizes of previous Llama series models?
- Llama 1: Context window of 2k;
- Llama 2: Default context window of 4k, but expandable to 32k via fine-tuning;
- Llama 3: Context window of 8k, later expanded to 128k with Llama 3.1’s long-text capabilities.
Meta’s official blog states:
(Llama 4’s long context) opens up a world full of possibilities, including multi-document summarization, parsing extensive user activity to perform personalized tasks, and reasoning over massive codebases.
Native Multimodal Design
The Llama 4 series marks the beginning of native multimodality for Llama.
The small and large sizes, already publicly available, are officially referred to as “lightweight native multimodal models.”
The user experience is straightforward: upload an image and ask various questions about it directly in the chat box.
I have to say, Llama finally has eyes!!!

The GIF above shows only basic capabilities; it won’t be intimidated by more complex tasks.
For example, feed it an image filled with tools and ask which ones are suitable for a specific job.
It quickly circles the applicable tools:

Identifying colors and recognizing birds? No problem:

Both the small and large sizes have been tagged in their official introductions as “the best multimodal models in their class worldwide.”
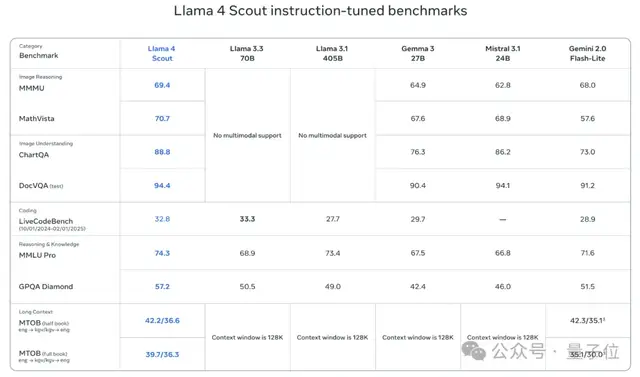
Let’s look at the comparison results with previous Llama series models, Gemma 3, Mistral 3.1, and Gemini 2.0 Flash-Lite:
As seen, Llama 4 Scout achieves new SOTA performance across all evaluation sets.
Maximum Language Talent
After pre-training and fine-tuning, Llama 4 masters 12 global languages to “facilitate deployment for developers worldwide.”

The “AI Pinduoduo” Even More Aggressive Than DeepSeek
A detail that must be shared: Meta went all-in on model API pricing this time!
The result first:
The giant-sized Llama 4 Maverick not only surpasses other models in its category but also comes at a very attractive price.
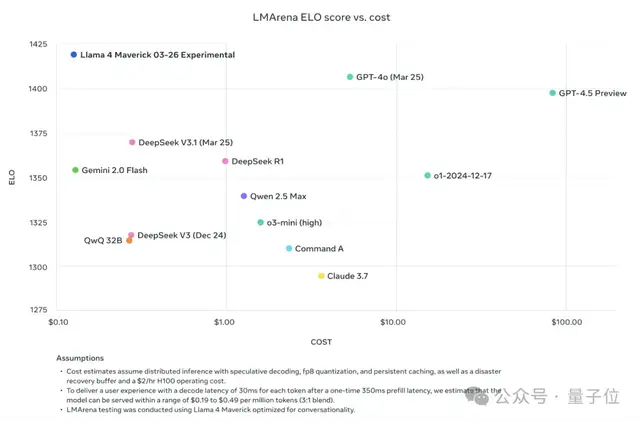
Looking at this table more intuitively, it is indeed more aggressive than DeepSeek—across both performance and price dimensions.

It is worth noting that the giant-sized Llama 4 Behemoth serves as the teacher model for the Llama 4 series.
If the small and large sizes are lightweight contenders, this one is an absolute heavyweight player.
With 288 billion activated parameters and 16 expert models, its total parameter count reaches a staggering 2 trillion!
In mathematics, multilingual, and image benchmarks, it provides state-of-the-art performance for non-reasoning models.
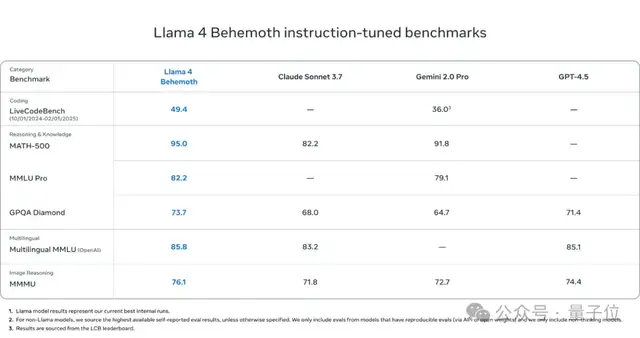
When “the best” and “the cheapest” are placed side by side, which developer wouldn’t be tempted? (doge emoji)
Training Details
In their own words, the Llama series has been thoroughly redesigned. For this first batch of Llama 4 models, they have also released specific training details.
Pre-training
They used a Mixture of Experts (MoE) architecture for the first time. In MoE architectures, only a small fraction of total parameters are activated per token. This architecture offers higher computational efficiency in both training and inference, delivering better quality under fixed FLOP costs.
DeepSeek-Equivalent Coding Capabilities with Half the Parameters, Running on a Single H100, Plus a Two-Trillion-Parameter “Super Cup”](/news-archive/2025-04-18c44c9a00/images/img-018.webp)
For instance, the Llama 4 Maverick model features 17 billion activated parameters and 400 billion total parameters. They employ alternating dense layers and Mixture of Experts (MoE) layers to enhance inference efficiency.
The MoE layer utilizes 128 routed experts and one shared expert. Each token is sent to the shared expert as well as one of the 128 routed experts.
Consequently, while all parameters are stored in memory, only a subset of the total parameters is activated when serving these models.
This approach improves inference efficiency by reducing model serving costs and latency—Llama 4 Maverick can run on a single H100 DGX host for ease of deployment, or achieve maximum efficiency through distributed inference.
They employ early fusion to seamlessly integrate text and visual tokens into a unified model.
They developed a new training technique called MetaP, which allows for the setting of key model hyperparameters, such as per-layer learning rates and initialization scales.
It was found that the selected hyperparameters scale and generalize well across different values for batch size, model width, depth, and training tokens:
Llama 4 achieved open-source fine-tuning capabilities by pre-training on 200 languages (including over 100 languages with more than one billion words each), resulting in a multilingual vocabulary total that is ten times larger than Llama 3’s.
Additionally, they used FP8 precision for efficient model training without sacrificing quality and ensuring high utilization of model FLOPs—when pre-training the Llama 4 Behemoth model using FP8 and 32K GPUs, they achieved 390 TFLOPs per GPU.
The overall mixed data used for training included over 30 trillion tokens, more than double that of Llama 3’s pre-training mixture, encompassing various text, image, and video datasets.
During the so-called “mid-term training,” the model was further trained using new methods (including specialized datasets for long-context expansion) to enhance core functionalities.
Post-Training
In the post-training phase, they proposed a curriculum strategy that does not sacrifice performance compared to single-mode expert models.
Llama 4 adopted a different approach to reshape their post-training pipeline:
Lightweight Supervised Fine-Tuning (SFT) > Online Reinforcement Learning (RL) > Lightweight Direct Preference Optimization (DPO).
A key lesson learned was that SFT and DPO can overly constrain the model, limiting exploration during the online reinforcement learning phase and leading to reduced accuracy, particularly in reasoning, coding, and mathematics.
To address this, they used Llama models as evaluators to remove more than 50% of data labeled as simple, performing lightweight SFT on the remaining harder dataset.
In the subsequent online reinforcement learning stage, by carefully selecting harder prompts, they achieved a significant performance leap.
Furthermore, they implemented a continuous online RL strategy involving alternating model training, followed by using the model to continuously filter and retain only medium-to-high difficulty prompts. This strategy proved highly favorable in balancing computational cost and accuracy.
Then, they adopted lightweight DPO to handle corner cases related to response quality, effectively achieving a good balance between the model’s intelligence and conversational abilities. The pipeline architecture, combined with continuous online RL strategies featuring adaptive data filtering, ultimately resulted in Llama 4.
In summary, a key innovation in the Llama 4 architecture is the use of interleaved attention layers without positional embeddings. Additionally, they adopted attention inference-time temperature scaling to enhance length generalization.
They refer to this as the iRoPE architecture, where “i” stands for “interleaved” attention layers, highlighting the long-term goal of supporting “infinite” context lengths, while “RoPE” refers to the Rotary Position Embeddings adopted in most layers.
Llama 4 Behemoth
Finally, they also revealed some distillation and training details regarding the super-large model, Llama 4 Behemoth.
They developed a novel distillation loss function that dynamically weights soft targets and hard targets during training.
During the pre-training phase, Llama 4 Behemoth’s code distillation capabilities amortized the resource-intensive forward passes required to compute distillation targets for most of the student training data. For other new data incorporated into student training, they ran forward passes on the Behemoth model to create distillation targets.
In the post-training phase, to maximize performance, they pruned 95% of the SFT data (compared to only 50% for smaller models) to ensure necessary focus on quality and efficiency.
They found that performing lightweight SFT followed by large-scale Reinforcement Learning (RL) leads to more significant improvements in reasoning and coding capabilities.
The reinforcement learning methods focused on extracting high-difficulty prompts through pass@k analysis of the policy model and carefully designing training curricula based on increasing prompt difficulty.
Additionally, they discovered that dynamically filtering out prompts with zero advantage during training and constructing training batches containing mixed-prompt samples across various abilities helped improve performance in mathematics, reasoning, and coding. Finally, sampling from various system instructions was crucial for ensuring the model maintained instruction-following capabilities in reasoning and coding while excelling across diverse tasks.
Due to its unprecedented scale, scaling RL for a two-trillion-parameter model required overhauling the underlying RL infrastructure.
They optimized the design of MoE parallelization to accelerate iteration speeds and developed a fully asynchronous online RL training framework to improve flexibility.
Existing distributed training frameworks sacrifice computational memory by stacking all models in memory; in contrast, their new infrastructure can flexibly allocate different models to different GPUs and balance resources across multiple models based on computing speed.
Compared to previous generations, this innovation increased training efficiency by approximately 10 times.
One More Thing
It is worth noting that due to DeepSeek releasing a new paper yesterday, Sam Altman reportedly grew restless and quickly issued a statement:
Plan Change: We might release o3 and o4-mini first in a few weeks.
GPT-5 is just a few months away~
But who knew Llama 4 would suddenly appear from nowhere?!
With fierce tigers ahead and jackals behind, OpenAI really needs to step up its game…
Netizens joked that when Sam Altman opened his eyes and saw Llama 4 had arrived—and with costs three orders of magnitude lower than GPT-4.5—his reaction would look something like this:

And compared to Llama, the currently mysterious and low-profile DeepSeek might suddenly release DeepSeek R2 and V4 at any moment… Tongyi Qianwen, also based in Hangzhou, is equally motivated. Whether it’s Llama or GPT, they have essentially become parallel reference points.
On this side of the Pacific, deployed applications and agents are already underway.
References
- Industry Leading, Open-Source AI | Llama — Discover Llama 4’s class-leading AI models, Scout and Maverick. Experience top performance, multimodality, low costs, and unparalleled efficiency.
- The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation — We’re introducing Llama 4 Scout and Llama 4 Maverick, the first open-weight natively multimodal models with unprecedented context support and our first…
- 1908598456144531660 — x.com/AIatMeta/status/1908598456144531660
- lmarena — x.com/lmarena/
- IOHK — x.com/IOHK/