DeepSeek’s explosive rise continues with the overnight release of a new model—
Janus-Pro-7B, a multimodal architecture that is open-source upon launch.
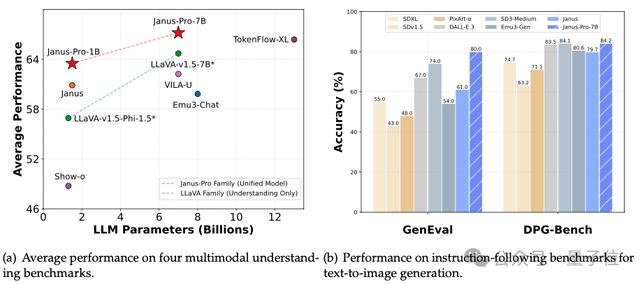
It outperformed DALL-E 3 and Stable Diffusion in GenEval and DPG-Bench benchmark tests.
You’ve likely been flooded with news about DeepSeek these past few days.
It has dominated the top spot on trending searches for an extended period, even causing a significant drop in Nvidia, the world’s first AI stock—plummeting nearly 17% and wiping out $589 billion (approximately RMB 4.24 trillion) in market value overnight, setting a record for the largest single-day decline in U.S. stocks.
The DeepSeek phenomenon continues to grow. During the Spring Festival holiday, users across China began experiencing its capabilities, causing DeepSeek’s servers to occasionally crash due to overwhelming traffic.



Notably, on the same night, Alibaba’s large language model family, Tongyi Qianwen (Qwen), also updated its open-source lineup:
The vision-language model Qwen2.5-VL, available in three sizes: 3B, 7B, and 72B.
Indeed, Hangzhou didn’t sleep last night as models raced to compete.
DeepSeek Releases New Model Overnight
Let’s look at DeepSeek’s new model, which is essentially an advanced iteration and continuation of its previous Janus and JanusFlow models.

Chen Xiaokang, a Ph.D. graduate from Peking University, leads the team.
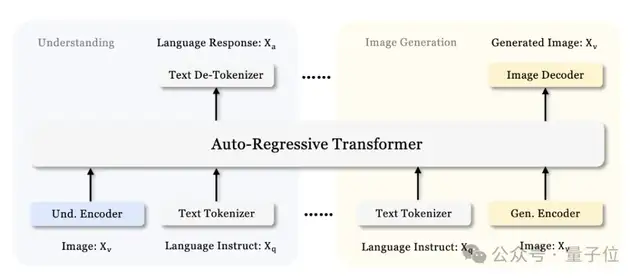
Specifically, it is built upon DeepSeek-LLM-1.5b-base/DeepSeek-LLM-7b-base and serves as a unified multimodal large model for both understanding and generation. The entire model adopts an autoregressive framework.
It addresses the limitations of previous methods by decoupling visual encoding into separate pathways while still utilizing a single, unified transformer architecture for processing.
This decoupling not only alleviates role conflicts between the visual encoder in understanding versus generation tasks but also enhances the flexibility of the framework.
For multimodal understanding, it employs SigLIP-L as the visual encoder, supporting 384 x 384 image inputs. For image generation, Janus-Pro uses the VQ tokenizer from LIamaGen to convert images into discrete IDs with a downsampling rate of 16.
After flattening the ID sequence into one dimension, they use a generative adapter to map the codebook embeddings corresponding to each ID into the LLM’s input space. These feature sequences are then concatenated to form a multimodal feature sequence, which is subsequently fed into the LLM for processing.
In addition to the prediction heads built into the LLM, randomly initialized prediction heads are used for image prediction in visual generation tasks.
Compared to the previous version of Janus, which involved three training stages, the team found this strategy suboptimal and significantly reduced computational efficiency.
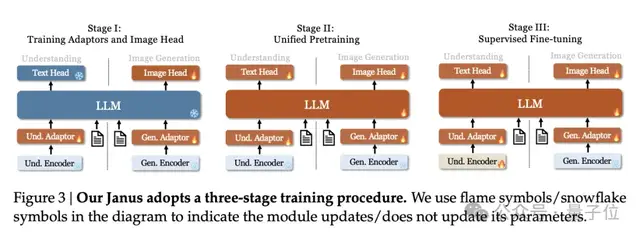
To address this, they made two major modifications.
- Stage I: Extended Training Duration: The number of training steps in the first stage was increased to allow for thorough training on the ImageNet dataset. Research indicates that even with fixed LLM parameters, the model can effectively simulate pixel dependencies and generate reasonable images based on category names.
- Stage II: Focused Training: In the second stage, the team abandoned the ImageNet dataset and directly utilized standard text-to-image data to train the model for generating images based on dense descriptions.
Additionally, during the supervised fine-tuning in Stage III, the proportion of different types of datasets was adjusted. The ratio of multimodal data, pure text data, and text-image data was changed from 7:3:10 to 5:1:4.
By slightly reducing the proportion of text-to-image data, this adjustment allows the model to maintain strong visual generation capabilities while improving multimodal understanding performance.
The final results show that it achieves parity with existing state-of-the-art (SOTA) vision understanding and generation models.
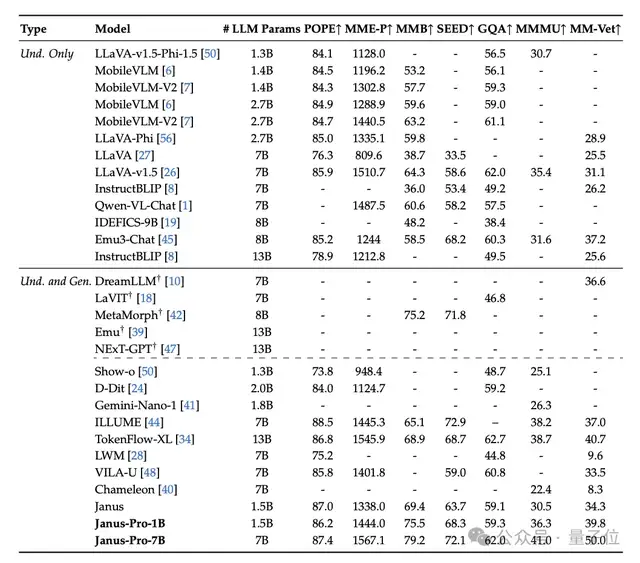
Compared to the previous Janus version, it provides more stable outputs for short prompts, offers better visual quality and richer details, and possesses the ability to generate simple text.

Qualitative results demonstrating further improvements in multimodal understanding and visual generation capabilities.
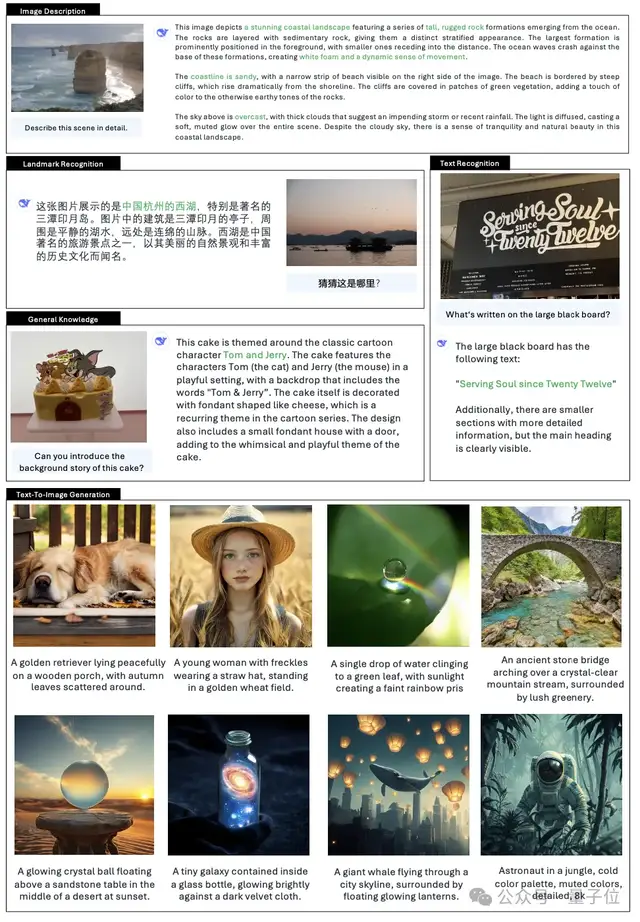
DeepSeek Conquers Global Users
You’ve undoubtedly been inundated with news about DeepSeek these past few days—
It has become a topic of discussion across both tech and non-tech circles, even among relatives.
For instance, Game Science, another prominent Hangzhou-based company (part of the “Hangzhou Six Little Dragons”), saw its founder and CEO, also the producer of Black Myth: Wukong, post on Weibo to express support: “Top-tier technological achievement, six major breakthroughs.”
Even Guo Fan, the director of The Wandering Earth, who previously referred to his AI assistant as MOSS, took notice of DeepSeek.
Well then, is DeepSeek directly booking a role in the next sequel? (Doge).
The story began a few days ago with the open-sourcing of its reasoning model R1. With its low cost, free usage, and performance that does not lag behind OpenAI’s o1, it has conquered global users, triggering an earthquake in the industry.
R1 was trained for just $5.6 million—a sum equivalent to the salary of any executive at Meta’s GenAI team—yet it has reached or surpassed OpenAI’s o1 model in many AI benchmarks.
Moreover, DeepSeek is genuinely free. While ChatGPT appears on free lists, unlocking its full capabilities requires a subscription fee of $200.
Consequently, users have flocked to DeepSeek to “build everything,” rapidly propelling it to the number one spot on the Apple App Store’s Free Apps chart in the U.S., surpassing popular apps like ChatGPT and Meta’s Threads.

The surge in user volume caused DeepSeek’s servers to crash multiple times, forcing the official team to perform emergency maintenance.
Within the industry, attention has focused on how to achieve parity with OpenAI while managing limited resource costs.
Unlike the capital-intensive, large-scale models prevalent abroad, which involve tens of billions or even hundreds of billions in costs and require hundreds of thousands of GPUs, DeepSeek’s technical details focus heavily on reducing overhead.
For example, distillation. R1 open-sourced six distilled smaller models trained on R1 data; the distilled Qwen-1.5B model outperformed GPT-4o in certain tasks.
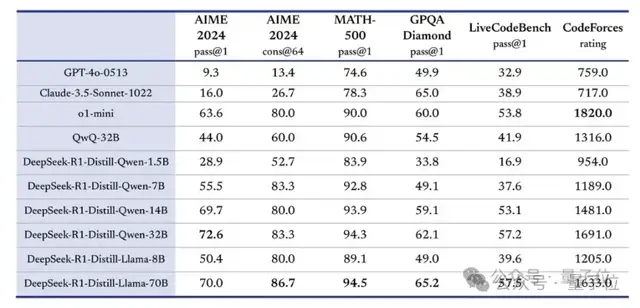
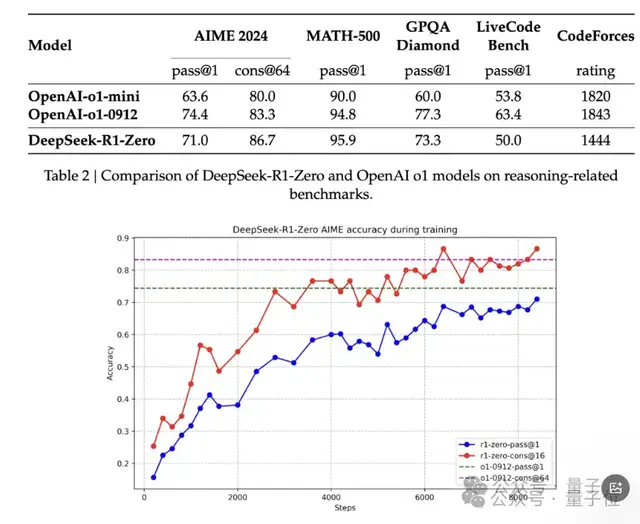
Another key factor is pure reinforcement learning. By abandoning the Supervised Fine-Tuning (SFT) phase and enhancing reasoning capabilities through thousands of iterations of reinforcement learning, it achieved scores on AIME 2024 comparable to OpenAI’s o1-0912.
This has led many to question OpenAI’s recent announcement of investing $500 billion in data centers and Nvidia’s long-standing monopoly on high-end GPUs.
Is it necessary to spend $500 billion building data centers?
Are massive investments in AI computing power justified?
These discussions resonated in the capital markets. After U.S. stock market opening, Nvidia’s shares plummeted 17%, marking its largest decline since March 2020, wiping out nearly $600 billion in market value. Jensen Huang’s personal wealth also shrank by over $13 billion overnight.
Chip giants such as Broadcom and AMD also saw significant declines.
In response, Nvidia publicly stated that DeepSeek represents an exceptional AI advancement and a prime example of test-time scaling. DeepSeek’s research demonstrates how to leverage this technology using widely available models and computing power fully compliant with export controls. The inference process requires substantial Nvidia GPUs and high-performance networking. Today, we have three scaling laws: the continuously applicable pre-training and post-training laws, and the new test-time scaling law.
Meta and OpenAI were similarly shaken.
Internally, Meta established a dedicated research group to dissect DeepSeek’s technical details in order to improve its Llama series models. Its New Year plan includes an AI budget starting at $40 billion, aiming for 1.3 million GPU cards by year-end.
Sam Altman also urgently announced that the new o3-mini model would be launched for free on ChatGPT, attempting to regain some market momentum.
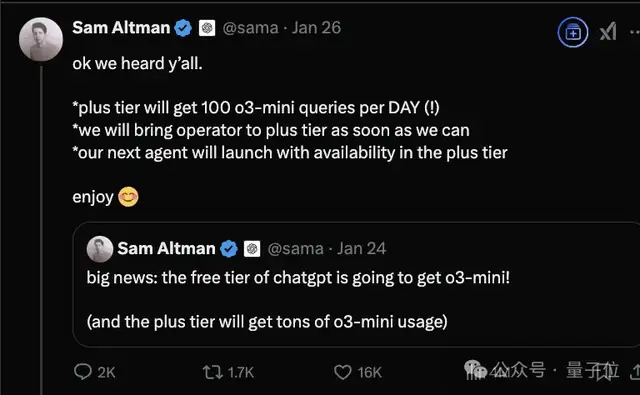
With the release of this new model, discussions about DeepSeek continue.
Rumors suggest a new version from DeepSeek may be released soon, potentially on February 25, 2025.

Hangzhou Sleepless Last Night
On the same night, in the same city of Hangzhou.
Shortly after DeepSeek released its new model, Qwen also updated its open-source family:
Qwen2.5-VL.

b88d/images/img-020.webp)
This title really gives off Three-Body vibes.
It comes in three sizes: 3B, 7B, and 72B. It supports visual understanding of objects, Agent capabilities, long-video comprehension with event capture, structured output, and more.
(For details, please refer to the next tweet.)
P.S. Finally, following Hangzhou’s “Six Little Dragons,” Guangdong’s “Three AI Heroes” have emerged.
(Hangzhou’s Six Little Dragons are Game Science, DeepSeek, Unitree Robotics, Cloudwalk Technology, BrainCo, and Qunhe Technology.)
They are Liang Wenfeng from Zhanjiang (founder of DeepSeek), Yang Zhilin from Shantou (founder of Moonshot AI/Kimi), and AI academic heavyweight He Kaiming from Guangzhou.

Hugging Face Link:
https://huggingface.co/deepseek-ai/Janus-Pro-7B
GitHub Link:
https://github.com/deepseek-ai/Janus