Recently, a group of top-tier general-purpose large language models participated in three special “industrial licensing exams.”
The results were surprising: even formidable contenders like GPT-5.2 Thinking (high) and Gemini-3.1-Pro struggled to perform well when faced with real-world industrial engineering contexts.
Why can’t a general AI that writes poetry and codes handle a production line?
The answer lies in the problem-solving approach provided by Sight Machine (Simou Technology), a low-profile star in industrial AI, and its self-developed, industry-specific large model, IndustryGPT.
It is worth noting that during these three exams, IndustryGPT not only topped the general benchmarks but also defeated GPT-5.2 Thinking (high) and Gemini-3.1-Pro on a benchmark of 10,000 industrial cases and in “licensing-level” engineering tests.

The score of this “exam” may not be the most important factor; rather, it has opened a window for people to see the capability boundaries of general large models in real industrial scenarios.
When models truly enter production lines and participate in engineering decision-making, being “smart” is merely a basic ability. Compliance, rigor, and reliability are the core metrics.
This also means that empowering the real economy with large models is moving from concept verification to rigorous acceptance testing. And industry is undoubtedly the most hardcore exam room in this major test.
The question remains: What kind of AI does China’s manufacturing sector actually need?
Three Exams Reveal the “Industrial Blind Spots” of General Models
IndustryGPT, released by Sight Machine, is the world’s first multimodal large model focused on industrial scenarios.
To answer the question of “what kind of AI manufacturing needs,” Sight Machine did something unique: it brought several mainstream large models into the arena to take three exams alongside IndustryGPT.
The first exam tested “breadth” of industrial knowledge.
To establish an objective and comparable evaluation benchmark, Sight Machine selected a subset of industry-related questions from the authoritative open-source Chinese dataset SuperGPQA, conducting horizontal tests on IndustryGPT against international top-tier general models like GPT-5.2 Thinking (high) and Gemini-3.1-Pro.
SuperGPQA is currently one of the most comprehensive and highest-quality comprehensive knowledge evaluation datasets in the Chinese field. Its industry-related subset covers multiple professional directions, including engineering technology, manufacturing processes, and materials science.
The results showed: IndustryGPT achieved SOTA (State-of-the-Art) among similar models, surpassing top-tier general models like GPT-5.2 Thinking (high) and Gemini-3.1-Pro in both the breadth of industrial professional knowledge and question-answer accuracy.
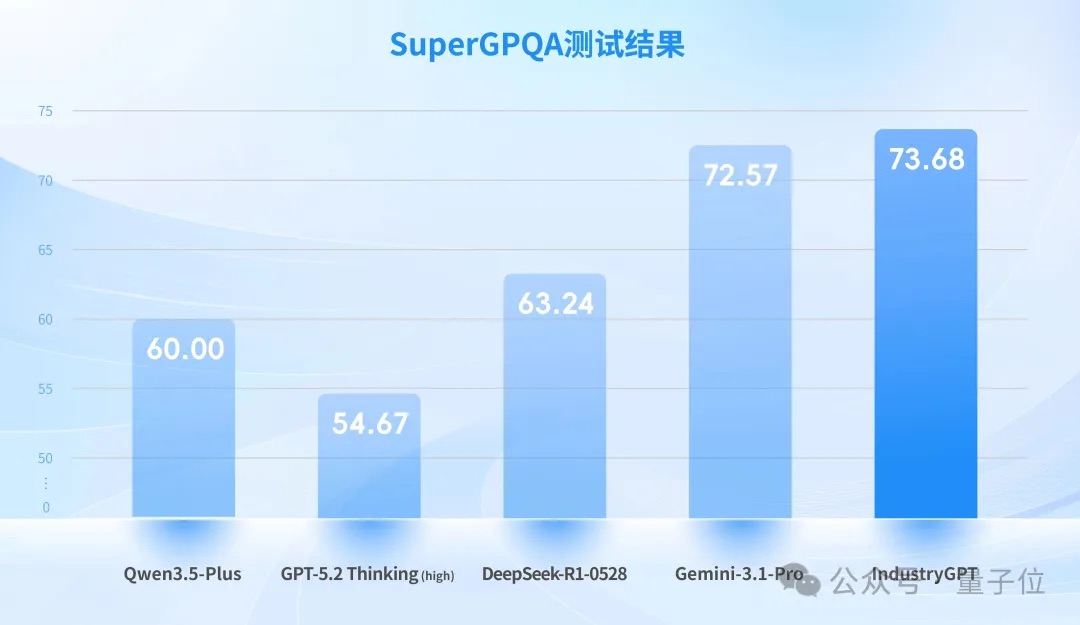
This indicates that it has built a core competitive barrier in industrial professional knowledge, solving the fundamental issue where general large models have shallow industrial knowledge and frequent errors in professional Q&A.
However, open-source benchmarks are only the first hurdle.
Although SuperGPQA covers a wide range, the professional depth and diversity of industrial scenarios far exceed the scope of standard test sets—a set of generic questions cannot effectively measure a model’s “feel” on a real production line. Moreover, there is currently a lack of evaluation datasets specifically designed for industrial scenarios in the industry.
To truly assess a large model’s performance in industrial settings, one must create their own tests!!

Thus came the second exam: testing the “depth” of industrial knowledge.
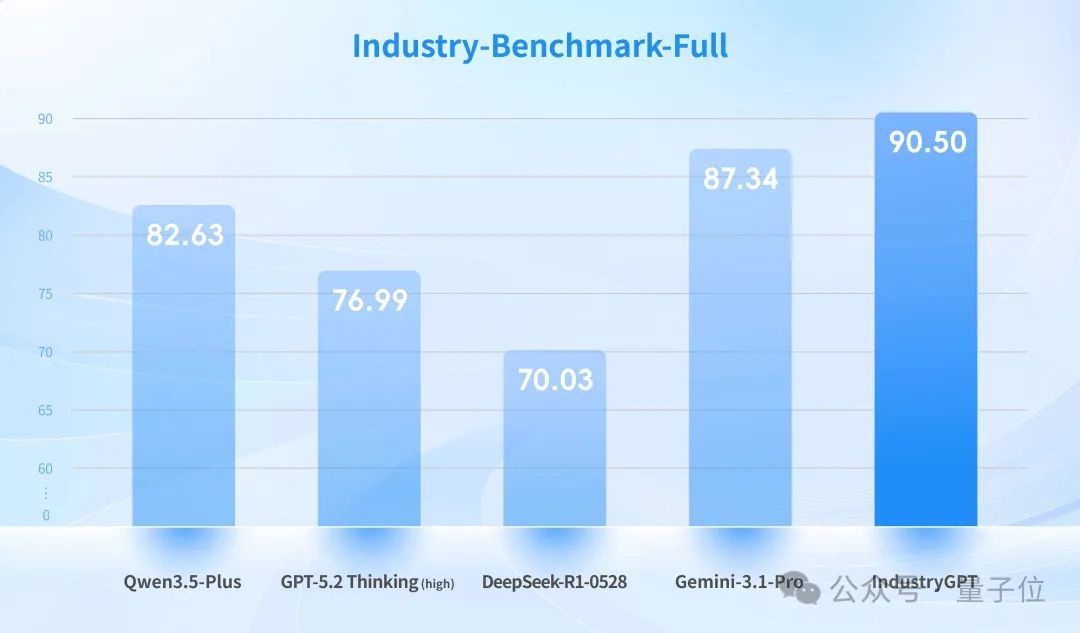
Sight Machine built a systematic industrial knowledge benchmark evaluation dataset, including 12 industry-related sub-domains. It covers core engineering disciplines such as mechanics, optics, and electrical engineering, spanning typical industrial sectors like 3C electronics, construction, mining, and textiles.
This benchmark is no joke: the total number of questions exceeds 10,000, surpassing all current open-source industrial datasets.

Sight Machine specifically designed a batch of high-difficulty “hard questions” to simulate complex decision-making scenarios in real industrial environments.
The results showed IndustryGPT leading by a significant margin: on the “hard question” subset, both GPT-5.2 Thinking (high) and Gemini-3.1-Pro failed completely, while IndustryGPT not only achieved SOTA but also realized a relative performance improvement of over 20%.
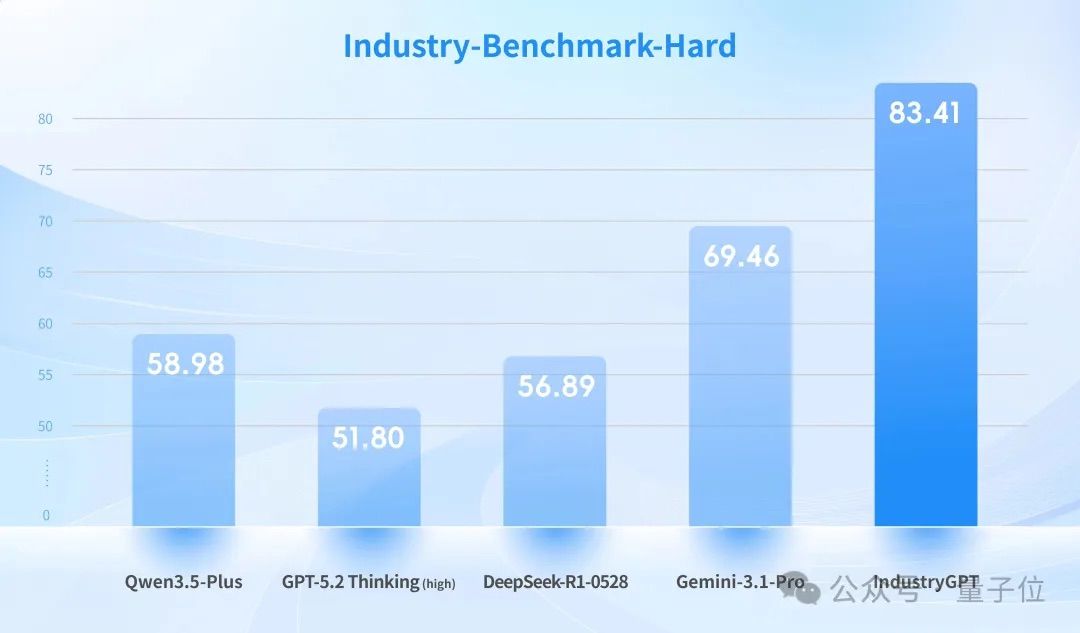
If you think that winning on its own test paper is enough for industrial AI, you are underestimating the “ruthlessness” of the industrial world.
For AI to truly work in industrial settings, it cannot just answer questions; it must possess the ability to participate in real engineering decision-making.
So, Sight Machine turned up the intensity again, organizing a third exam—testing “licensing qualifications.”
They independently constructed the world’s first large model evaluation benchmark that uses licensing qualification difficulty as a ruler, adheres rigidly to mandatory engineering standards, and focuses on core capabilities for implementable engineering decisions. This completely breaks free from the limitations of general academic benchmarks.
Goodness gracious, this jumped directly from knowledge understanding tests to engineering decision-making capability tests.

This evaluation framework aligns with the highest-level official licensing examinations in China and the US, referencing the Chinese National Registered Engineer Licensing Examination and the US NCEES FE/PE examination frameworks.
The dataset covers core engineering disciplines such as electrical, mechanical, chemical, and civil engineering. Questions are based on real-world engineering scenarios, requiring models to accurately match regulatory clauses, perform multi-step numerical derivations under multiple constraints, and make priority judgments and risk control decisions in cases of cross-regulation conflicts.
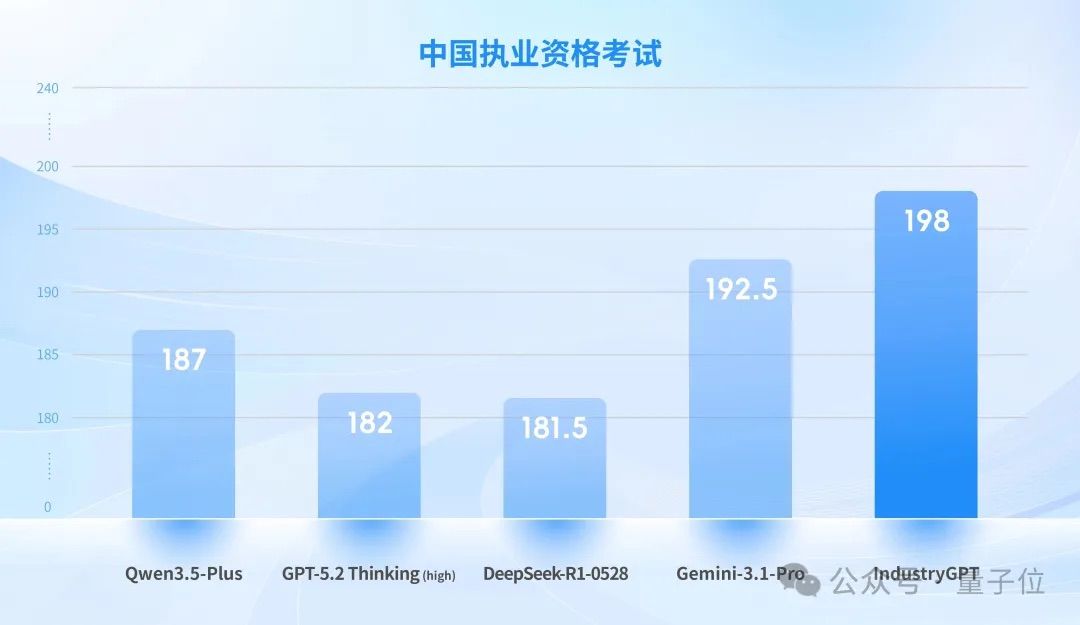
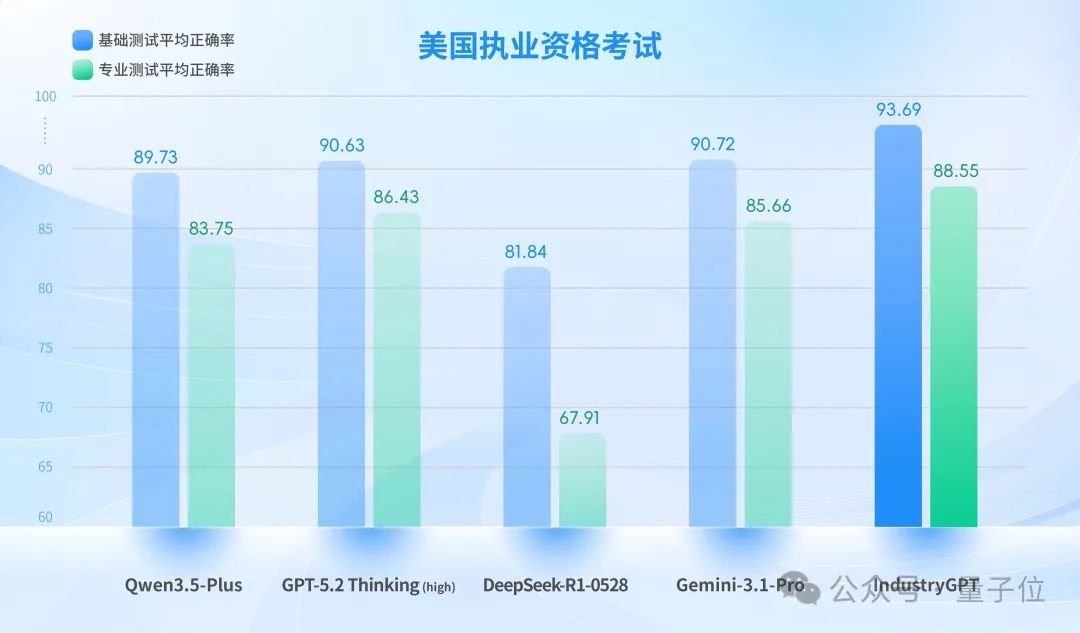
Note: The average accuracy rate is calculated by averaging the scores from disciplines such as electrical, mechanical, chemical, and civil engineering.
Compared to top-tier general models like GPT-5.2 Thinking (high), IndustryGPT achieved SOTA results in both tests.
IndustryGPT demonstrated higher stability in precise citation of regulatory clauses and compliance consistency. It also led in key indicators such as handling cross-regulation conflicts and controlling the rationality of engineering assumptions. Overall, in actual licensing scenarios, its comprehensive reasoning assessment and auxiliary decision-making capabilities for complex engineering solutions were superior.
It was essentially approaching the level of a real licensed engineer.
These three exams point to the same conclusion: the demand for AI in industrial scenarios has structural differences from general scenarios. While general models perform well at the common-sense level, they still fall short in industrial necessities such as regulatory compliance, boundary control, and complex decision-making.
Not Just Good at Testing, But Truly Deployable on Production Lines
Evaluation scores are just a threshold; what truly matters is: can the model be embedded into production systems to become part of the business process?
IndustryGPT’s answer is yes: through deep integration with Agent technology, it achieves a complete closed loop of perception-decision-execution in multiple high-standard scenarios.
SMore ViMo is a typical example of an industry model + Agent implementation. Relying on IndustryGPT’s native Agent capabilities, it compresses the customer’s deployment cycle from project initiation to running models from the industry average of 14 days to within 3 days.
In the industrial quality inspection phase, it can automatically identify and classify defect attributes, correcting accuracy through closed-loop verification, resulting in a 200% surge in efficiency.
Furthermore, IndustryGPT has also navigated deeper waters of manufacturing in more complex sectors such as consumer electronics, precision industry, automobiles, and high-speed rail. Here are two typical examples:
One is the field of complex process manufacturing in rail transit. Manufacturing plans are the core basis for ensuring production standards and quality traceability, serving as a key hub connecting design and manufacturing production.
In traditional modes, compiling manufacturing plans relies heavily on the experience of senior engineers. This not only results in low efficiency but also risks affecting production efficiency and quality due to human oversight.
By leveraging IndustryGPT, complete manufacturing plans containing detailed operational steps, key control points, and process designs can be automatically generated based on historical manufacturing plans and personalized requirements.
Through human-machine collaboration, it achieves intelligent design across the entire process, freeing engineers from tedious documentation work so they can focus on core design implementation.
The results were immediate: efficiency increased by over 15%, and the risk of changes was significantly reduced.
Another example is intelligent management of complex production lines.
In a highly complex manufacturing line with over 29,000 product models, large process differences, and highly fragmented anomaly types, traditional modes rely on veteran employees’ experiential judgment. This leads to slow anomaly response, inconsistent handling standards, and an inability to accumulate knowledge.
In this situation, the key is how to quickly match corresponding solution paths among massive numbers of models and historical cases while ensuring the handling process complies with established SOPs (Standard Operating Procedures).
Based on IndustryGPT, Sight Machine built a closed-loop intelligent process in an intranet environment: after scanning for anomalies, work orders are automatically created, the system matches SOPs, calls upon historical cases, and generates diagnostic suggestions. The entire process takes only 5 seconds.
The results were also outstanding: over 90% of common anomalies are resolved autonomously by the system, and core expertise has shifted from individual knowledge to organizational assets.
These scenarios illustrate a clear point: general models “can talk” but are not trusted for use, whereas industry models “can do” and take responsibility.
The “Acceptance Criteria” for Large Models Are Being Reconstructed
Behind the three exams and implementation cases lies a more fundamental question: the “acceptance criteria” that industrial scenarios apply to large models are undergoing a fundamental reconstruction.
In recent years, large models have primarily been evaluated based on their “intelligence level”: parameter scale, rankings on general benchmarks, multi-turn dialogue capabilities, code generation abilities, and so on. While these metrics hold true in internet-centric contexts, they are far from sufficient for industrial applications.
Industrial AI requires three core competencies—capabilities that current general-purpose models struggle to achieve through post-training fine-tuning alone:

First, boundary control capability.
In industrial environments, exceeding boundaries often implies risk. A model must not only provide correct results but also operate within regulatory constraints and safety limits.
IndustryGPT did not simply adopt the Reinforcement Learning from Human Feedback (RLHF) training methods commonly used by general large models. Instead, it introduced “Norm Consistency Reward Models” and “Calculation Process Reward Models.”
During training, the model receives feedback not just on whether the final answer is correct, but also on fine-grained evaluations of whether intermediate reasoning steps comply with engineering standards and whether calculation paths are rigorous.
This approach helps the model develop stable preferences for safety boundaries, numerical precision, and handling normative conflicts, thereby demonstrating higher reliability and consistency in complex engineering problems.

Second, norm compliance capability.
Industrial production is governed by strict mandatory standards that serve as non-negotiable red lines.
In this regard, IndustryGPT adheres to the principle of “learning norms before learning expression.” It does not follow the training paradigm dominated by general internet corpora; instead, it performs a structural reconstruction of industrial knowledge systems.
By hierarchically organizing professional content such as engineering specifications, national standards, process documents, and equipment manuals before feeding them into the large model, IndustryGPT instills a “norm-first” mode of knowledge expression during training. Consequently, when answering questions, it naturally adheres to the context of engineering.
Third, task execution capability.
Industrial scenarios do not need AI that merely engages in theoretical discussion. IndustryGPT’s Agent architecture enables it to call tools, decompose tasks, and execute workflows, transforming abstract understanding into executable engineering processes.
This “cognition + execution” integrated architecture allows the model to complete multi-step tasks in real-world industrial environments, rather than remaining at the level of textual suggestions.

In summary, IndustryGPT’s path to capability enhancement represents a clear technical direction for industrial large models: shifting from “general intelligence” to “licensed intelligence.”
The model no longer merely understands the world; it strictly adheres to industrial rules and stably, compliantly, and efficiently completes engineering tasks under real-world strong constraints, achieving a leap from the laboratory to the production line.
As “AI + Manufacturing” continues to deepen its implementation and spread, these three capabilities are becoming new standards for industrial clients when evaluating AI suppliers.
What Kind of Industrial AI Does China’s Manufacturing Sector Need?
Debates over the trajectory of industrial AI have never ceased within the industry. Currently, mainstream technical routes fall into two camps:
One camp advocates the “General Large Model + Industry Fine-Tuning” route. Its core logic is to first build a powerful general foundation and then fine-tune it using industry-specific data to adapt to the needs of industrial scenarios.
The other camp promotes the “Native Industrial Vertical Large Model” route, represented by SIGHT’s IndustryGPT. Its core logic is to reconstruct the underlying training paradigm from the ground up, natively adapting to the rules and requirements of industrial contexts.
The divergence between these two routes does not lie in the technical paths themselves, but rather in their differing understandings of “acceptance criteria.”
If the acceptance criterion is “can answer industrial questions,” then the fine-tuning route is sufficient to pass.
However, if the criterion is “can be embedded into production lines, can work according to specifications, and can take responsibility for results,” the situation changes significantly.
This is because boundary control, norm compliance, and task execution are fundamentally incompatible with the training paradigms of general models—the core of general large models lies in “generalized understanding,” whereas the core of industrial large models lies in “precise execution.” The latter cannot be achieved through post-training fine-tuning; it requires reconstruction from the foundational training paradigm.

In 2025, China’s core AI industry scale exceeded 1.2 trillion yuan, yet its integration with manufacturing remains stuck in the stage of “technology lacking practical grounding and scenarios lacking depth.”
In January this year, eight departments including the Ministry of Industry and Information Technology issued the Implementation Opinions on the “AI + Manufacturing” Special Action Plan, explicitly stating the goal to “launch 1,000 high-level industrial agents by 2027.” The term “agents” sets the tone for acceptance criteria: what is needed are AI systems that can execute tasks, not just ones that can answer questions.

In 2026, as large models enter the application phase, competition is shifting from a “parameter race” to “implementation acceptance.”
IndustryGPT’s 20% lead over international top-tier general large models like GPT-5.2 Thinking (high) does not merely signify who won an exam; rather, it reflects that a systematic misalignment still exists between current mainstream general models and real industrial demands.
This misalignment precisely validates the core value of industrial vertical large models: in the process of deep integration between AI and manufacturing, while general large models serve as important technical foundations, native vertical large models tailored to industry needs are the key drivers for achieving technological implementation.
Returning to the initial question: What kind of AI does China’s manufacturing sector actually need?
The ultimate goal of empowering the real economy with AI is not about competing on who is “smarter,” but on who can be more effectively implemented. For China’s myriad manufacturing enterprises and countless complex scenarios, the value of AI has never been about “showing off skills,” but about “empowerment.”
SIGHT’s exploration with IndustryGPT marks the beginning of the curtain-raising for AI industry implementation. The answers for the entire industry remain hidden within more hands-on practices.