Ant Group and Renmin University of China jointly developed LLaDA-MoE, a native Mixture-of-Experts (MoE) architecture diffusion language model (dLLM). The team completed zero-to-one training of the MoE-based dLLM on approximately 20 trillion tokens of data, validating the scalability and stability of industrial-grade large-scale training. The model’s performance surpasses previously released dense diffusion language models such as LLaDA 1.0/1.5 and Dream-7B, matches equivalent autoregressive models in capability, and retains a multi-fold advantage in inference speed. The model will be fully open-sourced in the near future to advance technological development in dLLMs within the global AI community.
On September 11, at the 2025 Inclusion·The Bund Conference, Ant Group and Renmin University of China jointly unveiled LLaDA-MoE, the industry’s first native MoE architecture diffusion language model. Li Chongxuan, Associate Professor at the School of Artificial Intelligence at Renmin University’s Lingling College, and Lan Zhenzhong, Director of Ant Group’s General AI Research Center, Distinguished Researcher at Westlake University, and Founder of Westlake Xinchen, participated in the launch ceremony.

(Joint release of the first MoE architecture diffusion model LLaDA-MoE by Renmin University and Ant Group)
According to reports, this new model utilizes a non-autoregressive masked diffusion mechanism to achieve language intelligence comparable to Qwen 2.5—such as in-context learning, instruction following, code generation, and mathematical reasoning—for the first time through native MoE training on large-scale language models. This achievement challenges the mainstream belief that “language models must be autoregressive.”
Performance data shows that LLaDA-MoE leads other diffusion language models like LLaDA 1.0/1.5 and Dream-7B in tasks involving code, mathematics, and agents. It approaches or surpasses the autoregressive model Qwen2.5-3B-Instruct, achieving performance equivalent to a 3B dense model while activating only 1.4B parameters.
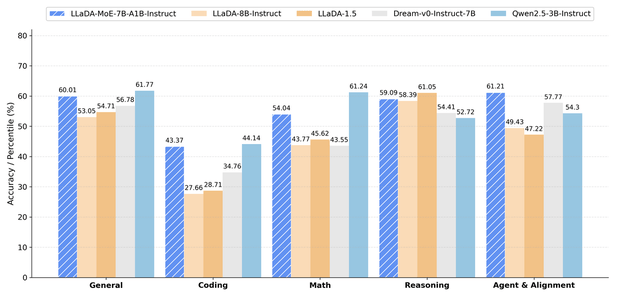
(LLaDA-MoE Performance Results)
“The LLaDA-MoE model validates the scalability and stability of industrial-grade large-scale training, marking another step forward in our journey to scale dLLMs to larger sizes,” said Lan Zhenzhong at the launch event.
Li Chongxuan from Renmin University’s Lingling College noted, “Over the past two years, AI foundation models have seen rapid advancements, yet several fundamental issues remain unresolved. The root cause lies in the autoregressive generation paradigm widely adopted by current large models—models are inherently unidirectional, generating tokens sequentially from start to finish. This makes it difficult for them to capture bidirectional dependencies between tokens.”
In response to these challenges, some researchers have turned their attention to diffusion language models with parallel decoding. However, existing dLLMs are based on dense architectures and struggle to replicate the “parameter scaling, computation efficiency” advantages found in Mixture-of-Experts (MoE) systems within autoregressive models (ARM). Against this industry backdrop, the joint research team from Ant Group and Renmin University introduced LLaDA-MoE, the first native diffusion language model built on an MoE architecture.
Lan Zhenzhong added, “We will fully open-source the model weights and our proprietary inference framework to the global community in the near future, working together with the community to drive a new breakthrough in Artificial General Intelligence (AGI).”
The Ant Group and Renmin University team spent three months tackling technical challenges. Building on LLaDA-1.0, they rewrote the training code and leveraged parallel acceleration technologies provided by Ant’s proprietary distributed framework, ATorch, including Expert Parallelism (EP). Utilizing training data based on Ant’s Ling 2.0 foundation model, the team achieved breakthroughs in core issues such as load balancing and noise sampling drift. Ultimately, they completed efficient training on approximately 20 trillion tokens using a 7B-A1B MoE architecture (totaling 7 billion parameters with 1.4 billion activated).
Under Ant’s proprietary unified evaluation framework, LLaDA-MoE achieved an average improvement of 8.4% across 17 benchmarks, including HumanEval, MBPP, GSM8K, MATH, IFEval, and BFCL. It outperformed LLaDA-1.5 by 13.2% and matched the performance of Qwen2.5-3B-Instruct. These experiments further validate that the “MoE Amplifier” law holds true in the dLLM domain, providing a viable path for subsequent sparse models ranging from 10B to 100 billion parameters.
According to Lan Zhenzhong, alongside the model weights, Ant will simultaneously open-source an inference engine deeply optimized for the parallel characteristics of dLLMs. Compared to NVIDIA’s official fast-dLLM, this engine delivers significant acceleration. The related code and technical reports will be published on GitHub and the Hugging Face community in the near future.
Lan Zhenzhong also revealed that Ant will continue to invest in AGI fields based on dLLMs. In the next phase, they will collaborate with academia and the global AI community to drive new breakthroughs in AGI. “Autoregression is not the end; diffusion models can equally become a main highway toward AGI,” Lan stated.