Nature Cover Recognition! DeepSeek R1 Achieves Latest Prestigious Honor.
In the latest issue of Nature, DeepSeek has become the first Chinese large model company to appear on the cover of the journal, with founder Liang Wenfeng serving as the corresponding author.
Globally, only a very small number of entities, such as DeepMind with AlphaGo and AlphaFold, have previously received similar honors.

The Nature version of the R1 paper not only discloses the training cost of R1 for the first time—approximately $294,000 (about 2.08 million RMB)—but also provides further technical details on the data types used in model training and safety measures.
Lewis Tunstall, a machine learning engineer at Hugging Face who reviewed the paper, stated that R1 is the first large language model to undergo peer review, setting a highly welcome precedent.
Huan Sun, an AI researcher at Ohio State University, praised R1 even more highly, noting that since its release, it has influenced almost all research on using reinforcement learning in large language models.
As of this writing, the data stands as follows:
- Google Scholar Citations: 3,596
- Hugging Face Downloads: 10.9 million (Ranking first among open-source model downloads)
- GitHub Stars: 91.1K
However, thanks to DeepSeek, it seems the next major work from Chinese AI companies will no longer be satisfied with presenting at top AI conferences like CVPR, ICLR, and ICML.
Should they aim for covers of Nature and Science instead?

Clarification of Training Details
In this Nature version, DeepSeek provided further clarifications on training costs, data, and safety in its latest supplementary materials.
Regarding training expenses, both R1-Zero and R1 utilized 512 H800 GPUs, training for 198 hours and 80 hours, respectively. At a rental price of $2 per GPU hour for an H800, the total training cost for R1 amounted to $294,000.
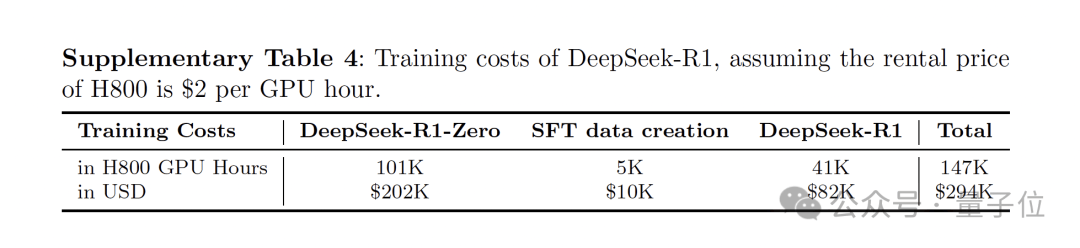
It is worth noting that R1 is a substantial 660B parameter large model.
In comparison, its training cost of less than $300,000 directly puts competitors who burn through tens of millions of dollars “out of their depth.”
No wonder it triggered a tsunami in the US stock market when released earlier this year, dispelling rumors that “massive investment is required to build top-tier AI models.”
(Altman: Just give me my ID number already.)
Furthermore, regarding data sources, DeepSeek broke the rumor of using outputs from other models as inputs for R1.
According to the supplementary materials, the DeepSeek-R1 dataset includes five types of data: mathematics, programming, STEM (Science, Technology, Engineering, and Mathematics), logic, and general knowledge.
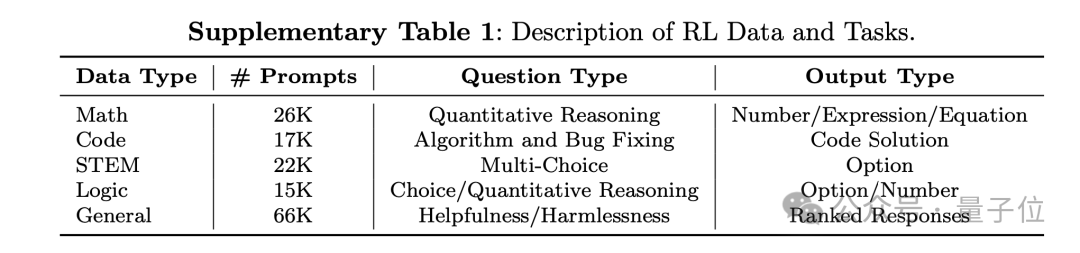
Specifically, the mathematics dataset contains 26,000 quantitative reasoning questions, including math exam and competition problems;
The code dataset includes 17,000 algorithmic competition problems and 8,000 code repair issues;
The STEM dataset comprises 22,000 multiple-choice questions covering subjects such as physics, chemistry, and biology;
The logic dataset contains 15,000 questions, including real-world and synthetic problems;
The general dataset includes 66,000 questions designed to evaluate the model’s usefulness, covering categories such as creative writing, text editing, factual Q&A, role-playing, and assessing harmlessness.
Regarding safety, while open-source sharing helps disseminate technology within the community, it also carries potential risks of misuse. Therefore, DeepSeek further released a detailed security assessment covering the following aspects:
- Risk control systems for official DeepSeek-R services
- Comparative evaluations against other state-of-the-art models across six public safety benchmarks
- Taxonomic research based on internal security test sets
- Multilingual security evaluation of the R1 model
- Robustness assessment of the model against jailbreak attacks.
The assessments indicate that the inherent safety level of the DeepSeek-R1 model is generally moderate, comparable to GPT-4o, and can be further enhanced by combining it with risk control systems.
Next, let us review this classic paper together.
A Milestone in Applying Reinforcement Learning to Large Language Models
Overall, DeepSeek-R1 (Zero) aims to address the reliance of large language models on complex problem-solving and human-annotated data by proposing a pure reinforcement learning (RL) framework to enhance their reasoning capabilities.
This method does not rely on manually annotated reasoning trajectories but instead develops reasoning abilities through self-evolution. The core lies in the reward signal being based solely on the correctness of the final answer, without imposing constraints on the reasoning process itself.
Specifically, they used DeepSeek-V3-Base as the foundational model and adopted GRPO (Group Relative Policy Optimization) as the reinforcement learning framework to improve performance on reasoning tasks.
After thousands of steps of reinforcement learning training, DeepSeek-R1-Zero demonstrated excellent performance on reasoning benchmarks.
For example, on AIME 2024, the pass@1 score increased from 15.6% to 71.0%, and further improved to 86.7% through majority voting, performing comparably to o1.
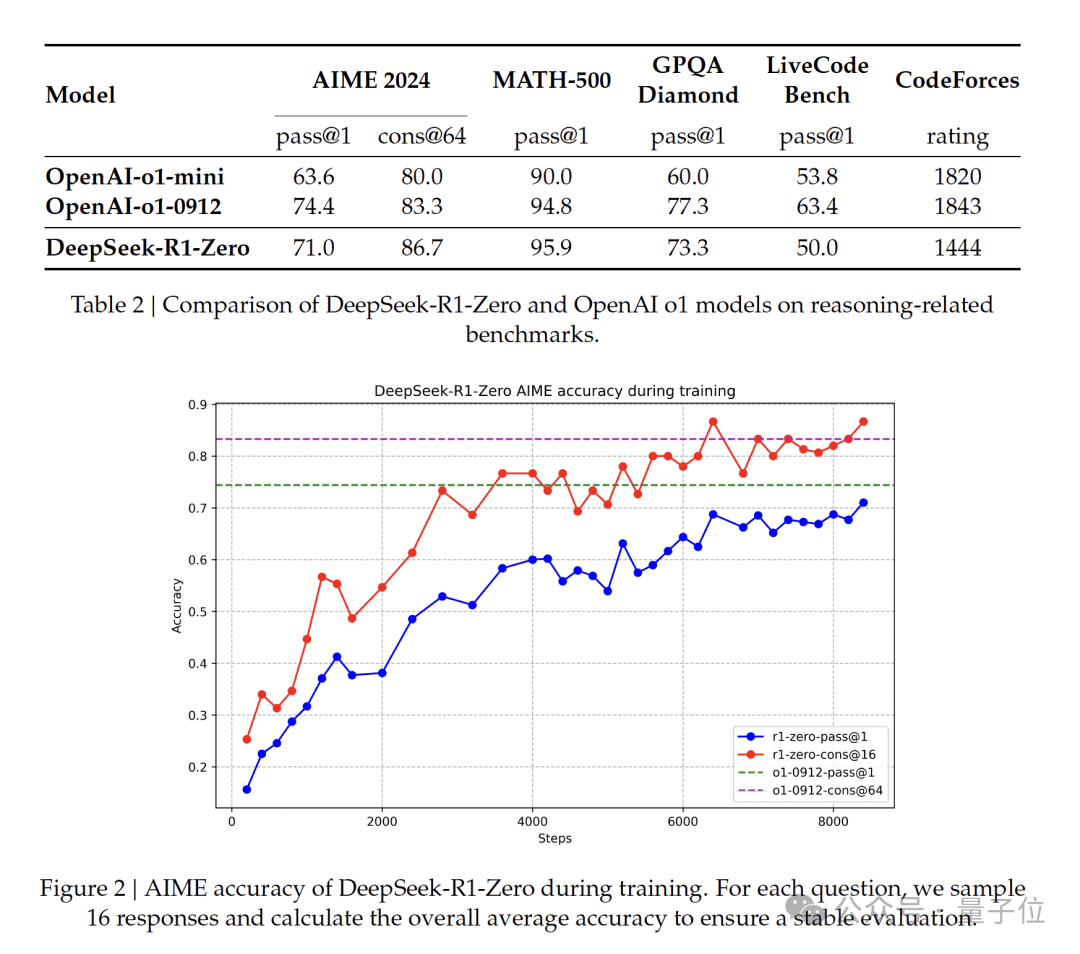
Furthermore, to address issues with readability and language mixing in DeepSeek-R1-Zero, researchers introduced DeepSeek-R1. This version employs a multi-stage training framework combining cold-start data, rejection sampling, reinforcement learning, and supervised fine-tuning (SFT).
Specifically, the team first collected thousands of cold-start data points to fine-tune the DeepSeek-V3-Base model. Subsequently, the model underwent reasoning-oriented reinforcement learning training similar to that of DeepSeek-R1-Zero.
As reinforcement learning approached convergence, the team performed rejection sampling on RL checkpoints and combined them with supervised data from DeepSeek-V3 in areas such as writing, factual Q&A, and self-awareness to generate new SFT data, which was then used to retrain the DeepSeek-V3-Base model.
After fine-tuning with the new data, the model underwent an additional reinforcement learning process covering various prompt scenarios, resulting in DeepSeek-R1.
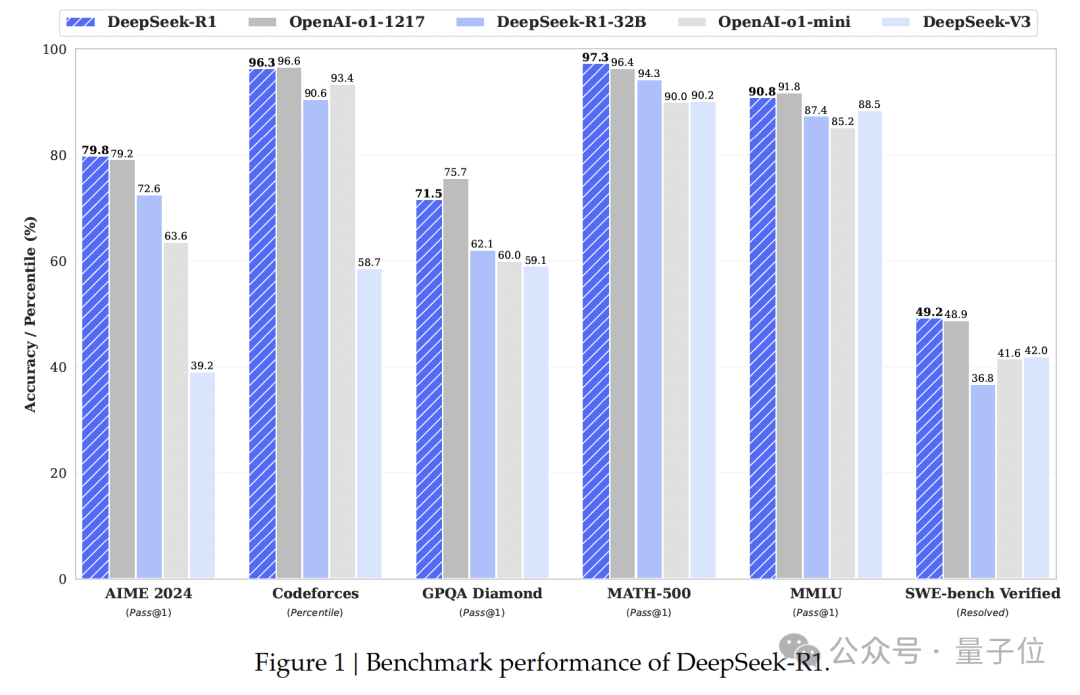
Experiments showed that DeepSeek-R1 was comparable to the top model at the time, OpenAI-o1-1217.
Additionally, using the reasoning patterns emergent in large models to guide and enhance the reasoning capabilities of smaller models has become a classic approach.
The paper used Qwen2.5-32B as the base model, showing that performance distilled from DeepSeek-R1 outperformed directly applying reinforcement learning on that base model.
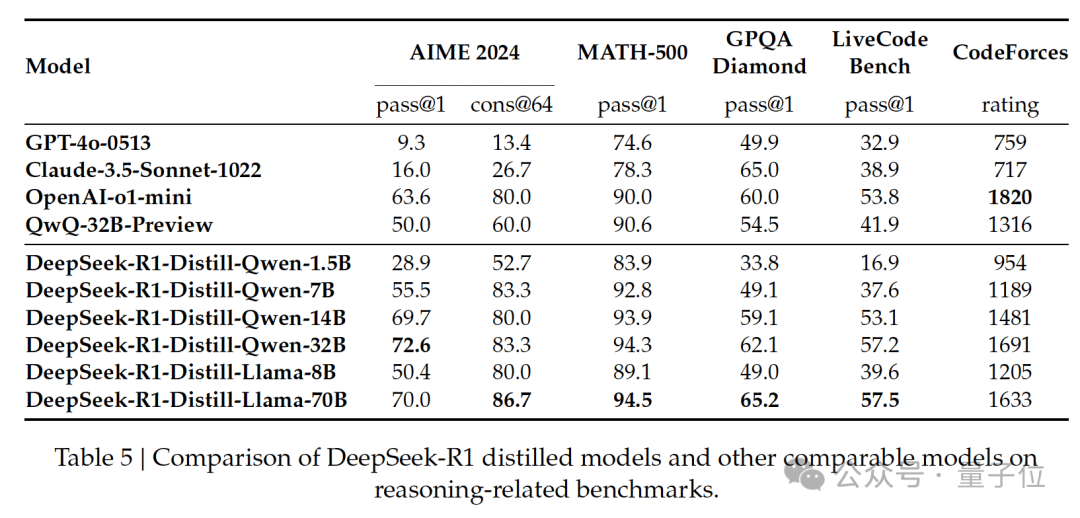
Of course, beyond this pioneering paper, what has garnered even more discussion and praise from Nature is DeepSeek’s transparency and open-source spirit:
DeepSeek has publicly released the model weights for DeepSeek-R1 and DeepSeek-R1-Zero on HuggingFace, while also open-sourcing distilled models based on the Qwen2.5 and Llama3 series for free use by the community.
Recall when DeepSeek went viral overseas earlier this year; founder Liang Wenfeng’s bold statement that “Chinese AI cannot follow forever” was inspiring.
Now, with Nature cover recognition validating DeepSeek’s influence, if there were an S-tier certification for AI research institutions, DeepSeek has undoubtedly earned it.
Who is next? Alibaba Tongyi, ByteDance Seed, Tencent Hunyuan, Baidu Wenxin, Huawei, Zhipu, Kimi, StepFun…
Who?
References
- Secrets of DeepSeek AI model revealed in landmark paper — First peer-reviewed study shows how a Chinese start-up firm made the market-shaking LLM for US$300,000.
- DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning - Nature — A new artificial intelligence model, DeepSeek-R1, is introduced, demonstrating that the reasoning abilities of large language models can be incentivized through pure reinforcement learning, removing the need for human-an