No need for Google’s “money power.” Two Tsinghua alumni have joined forces, enabling the foundational model Gemini 2.5 Pro to easily achieve an International Mathematical Olympiad (IMO) gold medal level.
All it took was a tweak in the prompt…

This discovery comes from two Tsinghua alumni, Lin Yang and Yichen Huang, who designed a self-iterative verification process and optimized prompts. This approach successfully enabled Gemini 2.5 Pro to solve this year’s IMO problems.
They have also recently updated their code, demonstrating that model reasoning can be enhanced using just general-purpose prompts.

Turns out, we were all misled by Large Language Models (LLMs). Foundational models have already overtaken competitors on the curve, possessing superhuman abilities to solve complex mathematical reasoning problems.
However, using them directly yields poor results.
For instance, MathArena also ran this year’s IMO questions through Gemini 2.5 Pro, but it scored only 13 points, far below the IMO bronze medal threshold of 19/42.

But with a little prompt engineering magic and iterative verification, the result is greater than 1+1=2.
This finding has received recognition from Terence Tao:
I agree that rigorous verification is key to achieving outstanding performance in complex mathematical tasks.
How exactly did they achieve this? Let’s look further.
General Prompts + Iterative Verification
First, why are AI models increasingly participating in IMO tests recently?
Compared to traditional math benchmarks like GSM8K and MATH, which target primary and secondary school levels, the IMO more thoroughly tests a model’s abstract thinking and multi-step logical reasoning capabilities. It is considered the “touchstone” for evaluating LLM reasoning abilities.
In previous years, model results were unsatisfactory; they either failed to understand problem requirements or showed bias toward specific types of problems.
It was only this year that an officially recognized gold-medal AI appeared. Both Google and OpenAI solved five problems. Google’s Gemini models utilized a new Deep Think mode, while OpenAI’s models reportedly achieved technical breakthroughs in general reinforcement learning and compute scaling.
Now, however, the research team has achieved similar results using only prompt design.
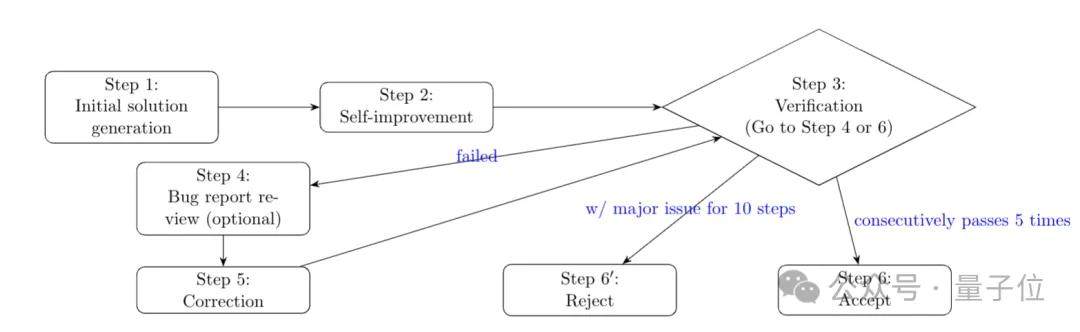
The key lies in their self-verification process, which consists of six steps:
- Initial Solution Generation: The model generates a preliminary solution based on the prompt, requiring clear logical reasoning and explicit explanations at each step.
- Self-Improvement: The model reviews and optimizes its initial answer to compensate for shortcomings caused by limited thinking budgets during the initial generation.
- Verify Solution and Generate Error Report: A verifier checks the solution against the prompt, generating a report that includes key errors such as logical fallacies or factual mistakes and incomplete arguments.
- Review Error Report (Optional): The error report is reviewed to remove false positives, enhancing the reliability of the report.
- Correct or Improve Solution Based on Error Report: The model improves its answer based on the error report and returns it to the verification step.
- Accept or Reject Solution: If the solution passes verification five consecutive times, it is accepted; if major issues persist after ten iterations, it is rejected.
Specifically, this entire process is executed by a solver and a verifier, both powered by Gemini 2.5 Pro, using differentiated prompts for distinct roles.
The solver is primarily responsible for generating and improving answers. Its prompt design prioritizes rigor, ensuring results can be strictly verified.
Since Gemini 2.5 Pro’s maximum thinking token limit is 32,768, it cannot independently solve complex IMO problems in a single initial generation. Therefore, through step 2 (self-improvement), an additional 32,768 tokens are injected, allowing the model to review and optimize its initial solution, thereby improving overall quality.
The verifier then simulates an IMO scoring expert, performing iterative improvements and deciding whether to accept the improved solution.
The verifier checks each solution step-by-step to identify issues, categorizing them into critical errors and argument gaps. Critical errors refer to obvious mistakes or clear logical fallacies that severely break the logic chain of the proof, leading to incorrect answers.
Argument gaps include major gaps and minor gaps. Major gaps may cause the entire proof to fail, while minor gaps might still lead to a correct conclusion but leave the argument incomplete.
Upon identifying issues, the verifier outputs an error report, providing useful information for the model to improve its solution. In step 4, any misjudgments by the verifier are corrected, after which the model attempts to refine its answer based on the report.
Since the verifier can also make mistakes, sufficient repeated iterations are required to mitigate the impact of false judgments. Ultimately, if the answer passes verification, it is accepted; if critical errors or major argument gaps persist, it is rejected.

In the specific experimental process, the research team selected the newly released IMO 2025 questions. Because these were published recently, it effectively avoids training data contamination, ensuring the authenticity of the evaluation.
Regarding parameter settings, a low temperature value of 0.1 was chosen because higher temperatures could lead to more random errors. The maximum inference token limit of Gemini 2.5 Pro was used, while excluding interference from other models or code.
In the key prompts, the initial generation prompt requires sufficient reasoning to support answers. Fabrication is prohibited if a complete solution cannot be found, and all mathematical content must be presented in TeX format.

The output format must strictly follow the order of summary to detailed solution. The summary includes conclusions and an overview of methods, while the detailed solution presents a complete, step-by-step mathematical proof. Careful checks are performed before final output to ensure compliance with all instructions.
In the verification prompt, the sole task is to identify and report all issues in the solution without attempting to correct loopholes. A detailed verification log must be generated, classifying problems. The output format includes a summary (final verdict and list of findings) and a detailed verification log.

Ultimately, the model generated complete and mathematically rigorous solutions for five of the six IMO problems. For the first two problems, both prompted and unprompted solutions were generated.
For Problem 1, mathematical induction was used in the prompt; for Problem 2, analytic geometry was used. Comparing these shows that detailed prompts can reduce the computational search space and improve efficiency, but do not grant the model new capabilities per se.
On the sixth problem, which remained unsolved, researchers found that the model made a core error in one of its proofs, rendering subsequent steps invalid.
The experimental results demonstrate that structured iterative processes are key to transforming LLM potential into rigorous mathematical proofs, overcoming limitations such as finite reasoning budgets and initial answer errors inherent in single-generation attempts.
Additionally, researchers anticipate that mixing multiple models, such as Grok 4 or the OpenAI-o series, along with multi-agent systems like Grok 4 heavy, could yield even stronger mathematical capabilities.
Tsinghua Alumni Team Up
The two authors of this study—Yichen Huang and Lin Yang—were undergraduate classmates in the Basic Science Experimental Class for Mathematics and Physics at Tsinghua University. After graduation, they both pursued advanced degrees overseas.

Yichen Huang earned his Ph.D. in Physics from the University of California, Berkeley. He previously worked as an AI researcher at Microsoft and later served as a postdoctoral fellow at the California Institute of Technology (Caltech), working under Professor Xie Chen, a leading figure in condensed matter physics.
Professor Xie Chen also graduated from Tsinghua University for his undergraduate studies and received his Ph.D. in Theoretical Physics from MIT in 2012. He is currently the Eddleman Professor of Theoretical Physics at Caltech.
His research focuses on new phases and phase transitions in quantum condensed matter systems, including topological order in strongly correlated systems, many-body system dynamics, tensor network representations, and applications in quantum information.
He won a Sloan Fellowship in 2017 and later received the New Horizons in Physics Prize in 2020 for his outstanding contributions to the topology of matter states and their interrelations. This award is part of the Breakthrough Prizes, often referred to as the “Oscars” of contemporary science.
Subsequently, Yichen Huang continued postdoctoral research at the Center for Theoretical Physics at MIT and the Department of Physics at Harvard University, focusing on quantum physics, including quantum information, condensed matter theory, and machine learning.

The other author, Lin Yang, is currently an Associate Professor at the University of California, Los Angeles (UCLA), holding appointments in both the Department of Electrical and Computer Engineering and the Department of Computer Science.

Previously, he earned dual Ph.D.s in Computer Science and Physics & Astronomy from Johns Hopkins University. He also conducted postdoctoral research at Princeton University under Professor Mengdi Wang.
Professor Mengdi Wang entered Tsinghua University at age 14 and graduated with a Ph.D. from MIT at age 23. Her advisor was Dimitri P. Bertsekas, an academician of the U.S. National Academy of Engineering. At just 29, she became a tenured professor at Princeton University.
Her research primarily involves generative AI, reinforcement learning, and large language models. In 2024, she received the Donald P. Eckman Award, the highest honor in the field of control theory (awarded to only one recipient annually).
Professor Yang’s research focuses on reinforcement learning theory and applications, machine learning and optimization theory, big data processing, and algorithm design. He has published numerous papers at top-tier machine learning conferences such as ICML and NeurIPS, and has received awards including the Amazon Award for Faculty in Machine Learning and the Simons Scholar Award.
Even with Limited Resources, Academia Can Compete with Big Tech
We spoke in depth with Professor Yang Lin about the details of this study.
When asked why Gemini 2.5 Pro was prioritized as the subject of research, Professor Yang explained:
At the start of the experiment, Gemini was relatively convenient to use, offering a wider range of adjustable parameters.
Regarding the computational resources and time required for Gemini 2.5 Pro to solve the first five problems, Professor Yang responded candidly:
We did not meticulously track the specific resources used, but roughly estimating, the initial step requires approximately 60,000 tokens. For subsequent verification steps, if the answer passes, it consumes about 15,000 tokens; if modifications are needed, it takes around 30,000 tokens.
Due to randomness, results vary each time. The number of tokens required per problem can range from 300k to 5,000k. For instance, on an unlucky run, a single problem took eight independent experiments to solve. Computation time depends on the availability of Google’s servers; it can take as little as ten minutes to solve one problem under optimal conditions.
On the difference in model performance with and without prompting, Professor Yang noted:
When prompted, the model typically solves the problem within a single independent experiment (where an agent’s output is either successful or failed). Without prompts, the model’s reasoning tends to diverge; the aforementioned eight independent experiments occurred in the absence of such prompts.
As for Problem 6, which remained unsolved, Professor Yang attributed the issue primarily to the verifier:
When the solver outputs a false positive answer, the verifier fails to distinguish certain nuances effectively.
The team has already conducted manual verification and self-checked all details of the proofs. However, lacking official scoring, Professor Yang expressed willingness to participate in IMO’s official grading process if the organizing committee is interested, further validating the solutions.
In the future, they plan to enhance the base model’s capabilities by pre-training and fine-tuning it with more training data.
Professor Yang also shared some insights gained from this research:
Sometimes, the potential of base models needs to be unlocked through alternative methods. If future model training hits a bottleneck, Agent-based approaches could be the key breakthrough. This study demonstrates that academia can achieve results of equal significance to those produced by major tech companies, even with limited resources.
He hopes AI will play an increasingly important role in mathematical research in the future, particularly regarding long-standing unsolved problems.
Finally, we asked Professor Yang for advice on coexisting with AI. He humbly replied:
Students are younger than me and may use AI more naturally, so I cannot offer much advice. However, personally, I hope to improve my own knowledge base while using AI.
In short: Use it, and learn from it.
Paper link: https://www.alphaxiv.org/abs/2507.15855v2
References
- 1948223115437154372 — x.com/ns123abc/status/1948223115437154372
- GitHub - lyang36/IMO25: An AI agent system for solving International Mathematical Olympiad (IMO) problems using Google’s Gemini, OpenAI, and XAI APIs. — An AI agent system for solving International Mathematical Olympiad (IMO) problems using Google’s Gemini, OpenAI, and XAI APIs. - lyang36/IMO25
- 1947466281990738339 — x.com/lyang36/status/1947466281990738339