On June 27, Tencent Hunyuan announced the open-sourcing of its first hybrid reasoning Mixture-of-Experts (MoE) model, Hunyuan-A13B. With a total parameter count of 80 billion and only 13 billion active parameters, the model delivers performance comparable to leading open-source models with similar architectures, while offering faster inference speeds and higher cost-effectiveness. This development lowers the barrier for developers to access superior model capabilities.
As of today, the model is available on open-source communities such as GitHub and Hugging Face. The model API has also officially launched on the Tencent Cloud website, supporting rapid integration and deployment.
Hunyuan-A13B marks the industry’s first 13B-level open-source MoE hybrid reasoning model. Leveraging an advanced architecture, it demonstrates robust general capabilities, achieving strong results across multiple authoritative industry benchmark datasets. It shows particularly outstanding performance in Agent tool calling and long-document comprehension.
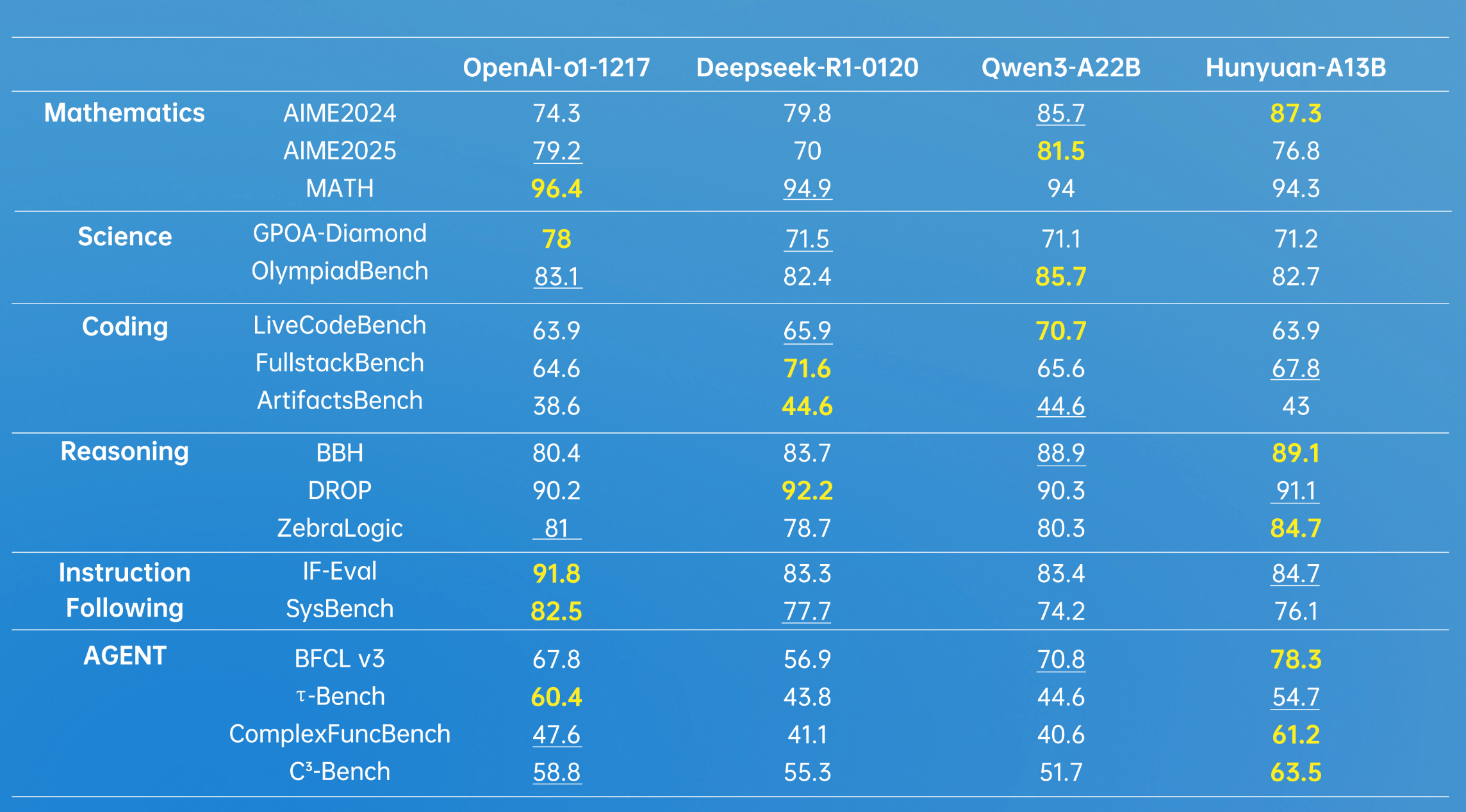
*Bold indicates the highest score; underlined text denotes second place. Data sourced from various public test dataset scores for the model.
Regarding the currently popular Agent capabilities of large language models, Tencent Hunyuan has developed a multi-Agent data synthesis framework. This framework integrates diverse environments such as Model Context Protocol (MCP), sandboxes, and large language model simulations. Through reinforcement learning, Agents are enabled to autonomously explore and learn across various environments, further enhancing the performance of Hunyuan-A13B.
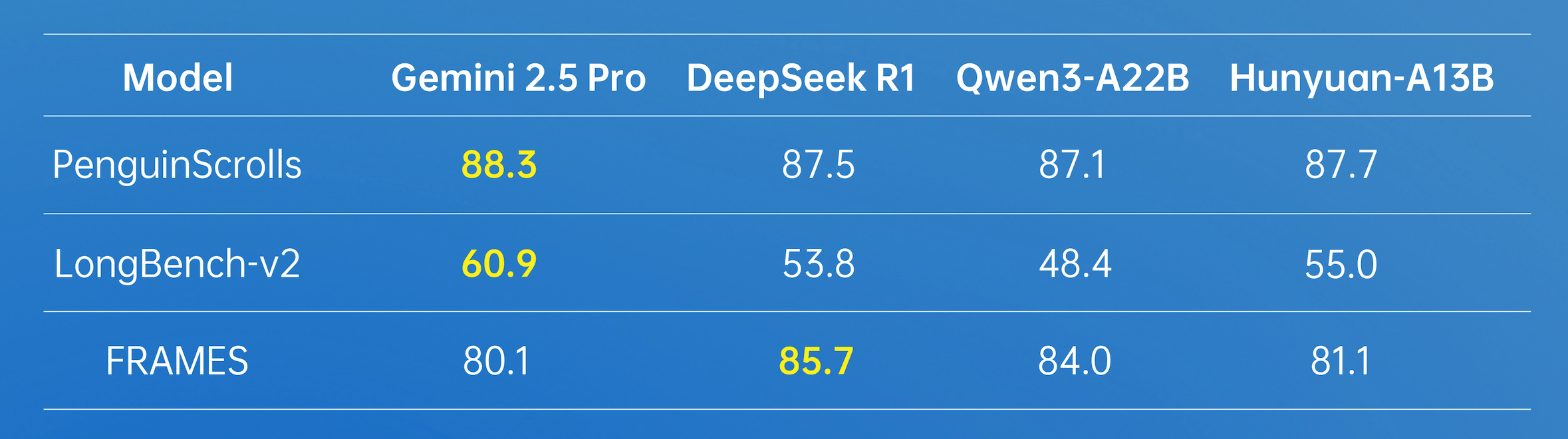
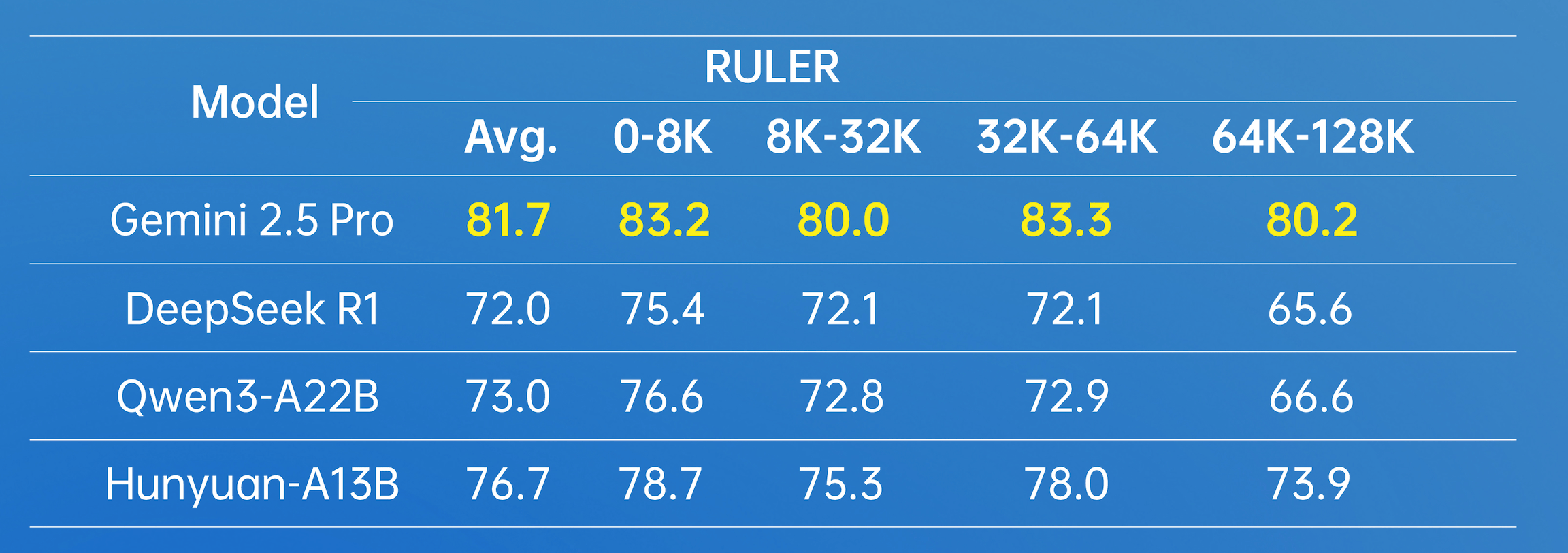
In terms of long-document processing, Hunyuan-A13B supports a native 256K context window and has achieved excellent results in multiple long-text datasets.
In practical usage scenarios, the Hunyuan-A13B model allows users to select a thinking mode based on their needs. The “fast thinking” mode provides concise and efficient outputs, suitable for simple tasks where speed and minimal computational overhead are prioritized. Conversely, “slow thinking” involves deeper and more comprehensive reasoning steps, such as reflection and backtracking. This hybrid reasoning approach optimizes the allocation of computational resources, allowing users to balance efficiency and task-specific accuracy by switching between think and no_think modes.
The Hunyuan-A13B model is particularly developer-friendly. Under strict conditions, it can be deployed with just one mid-to-low-end GPU card. Currently, Hunyuan-A13B has integrated into the mainstream open-source inference framework ecosystem, offering lossless support for various quantization formats. At equivalent input-output scales, its overall throughput exceeds that of frontier open-source models by more than two times.
Hunyuan-A13B incorporates innovative technologies from Tencent Hunyuan across multiple stages, including pre-training and post-training, which collectively enhance its inference performance, flexibility, and efficiency.
During the pre-training phase, Hunyuan-A13B was trained on 20 trillion tokens of corpus data covering various domains. High-quality corpora significantly improved the model’s general capabilities. Furthermore, through systematic analysis, modeling, and validation, the Tencent Hunyuan team constructed a joint scaling law formula applicable to MoE architectures. This discovery refined the theoretical framework for MoE architecture scaling laws and provided quantifiable engineering guidance for MoE design, greatly enhancing pre-training effectiveness.
In the post-training phase, Hunyuan-A13B adopted a multi-stage training approach to boost inference capabilities while maintaining general competencies in content creation, comprehension, and Agent functionalities.

Figure: Four steps of post-training for Hunyuan-A13B
To further enhance large language model capabilities, Tencent Hunyuan has also open-sourced two new datasets to fill gaps in industry-related evaluation standards. ArtifactsBench aims to bridge the visual and interaction gap in code generation evaluations by establishing a new benchmark comprising 1,825 tasks across nine domains, ranging from web development and data visualization to interactive games, with difficulty levels graded for comprehensive assessment. C3-Bench addresses three key challenges faced by models in Agent scenarios—planning complex tool relationships, handling critical hidden information, and making dynamic path decisions—by designing 1,024 test cases to identify potential weaknesses in model capabilities.
Hunyuan-A13B is one of the most widely used large language models within Tencent internally, with over 400 business units fine-tuning or directly invoking it, generating more than 130 million daily requests. This upgrade and subsequent open-sourcing represent another significant milestone for the Hunyuan LLM series following the release of the “large” version. Despite having fewer parameters, Hunyuan-A13B achieves substantial improvements in performance and effectiveness. Moving forward, Tencent Hunyuan will introduce more models with varying sizes and features, sharing practical technologies with the community to foster a thriving open-source ecosystem for large models.
Tencent Hunyuan remains committed to embracing open source, continuously promoting the open-sourcing of its full range of multi-size and multi-scenario models. Its foundational models across various modalities—including images, video, 3D, and text—are already fully open-sourced. In the future, Hunyuan plans to release hybrid reasoning models in multiple sizes, including dense models ranging from 0.5B to 32B, as well as MoE models with 13 billion active parameters, catering to diverse enterprise and edge-side needs. Additionally, its image, video, 3D, and other multimodal foundational models, along with supporting plugin models, will continue to be open-sourced.

References
Experience Portal: https://hunyuan.tencent.com/
API Address: https://cloud.tencent.com/product/tclm
GitHub: https://github.com/Tencent-Hunyuan
Hugging Face: https://huggingface.co/tencent
C3-Bench: https://github.com/Tencent-Hunyuan/C3-Benchmark
ArtifactsBench: https://github.com/Tencent-Hunyuan/ArtifactsBenchmark