Native multimodal input and output, agents, web search… What happens when all these cutting-edge AI capabilities are integrated?
Google’s latest Project Astra showcases the potential of an ultimate AI assistant:

Video Link: https://mp.weixin.qq.com/s/Z2WkvmnYIVlmd43S2r35FA
It observes its surroundings in real-time, searches for information to guide a cyclist through repairs, and even automatically calls nearby stores to check for missing parts.
At the latest I/O conference, Google unveiled a barrage of announcements as if they were free.
- All existing AI models have been updated.
- Existing products have been rebuilt with AI.
- A host of experimental new products were also introduced.
Preview versions of Gemini 2.5 Pro and Gemini 2.5 Flash currently occupy the top two spots on benchmark leaderboards.
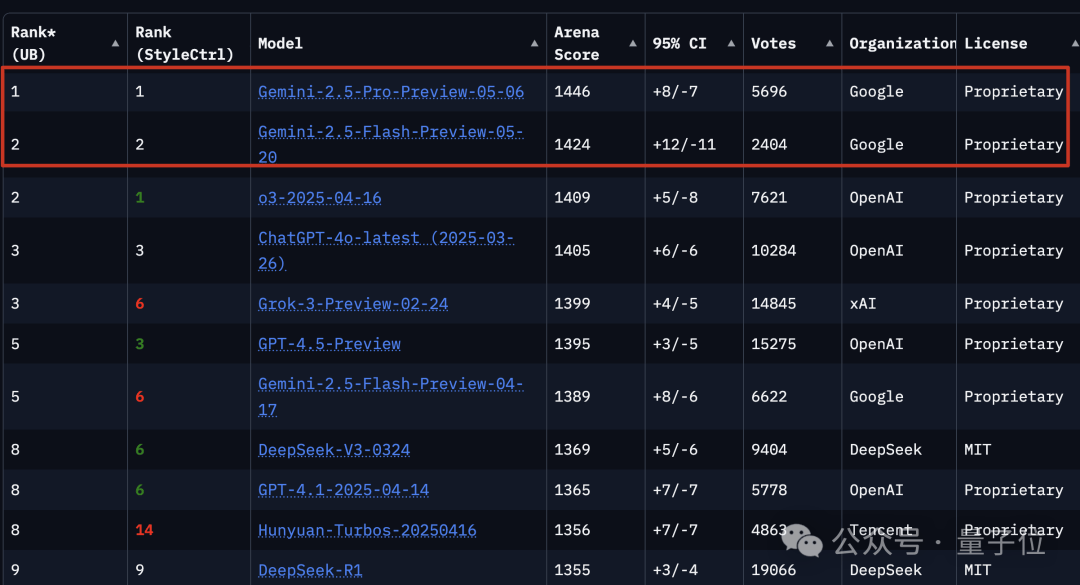
The Veo 3 video generation model achieves native integration of video and audio. Beyond music and sound effects, it can generate dialogue voices between characters, with synchronized lip movements on screen.
Video Link: https://mp.weixin.qq.com/s/Z2WkvmnYIVlmd43S2r35FA
The Imagen 4 image generation model produces richer images with more nuanced colors and realistic details.

…
In terms of traditional products, Google Search has added an end-to-end AI search mode. It integrates reasoning and multimodal analysis capabilities, breaking questions down into sub-problems and issuing multiple queries simultaneously to explore the web more deeply.
Video Link: https://mp.weixin.qq.com/s/Z2WkvmnYIVlmd43S2r35FA
Google Meet, the video conferencing platform, now supports real-time bilingual dubbed translation while preserving the speakers’ original voice tones. English-Spanish support is available in the initial rollout, with more languages to follow.
Video Link: https://mp.weixin.qq.com/s/Z2WkvmnYIVlmd43S2r35FA
The Chrome browser now integrates the Gemini model directly, allowing users to quickly summarize content or complete tasks based on the current webpage context without switching tabs.
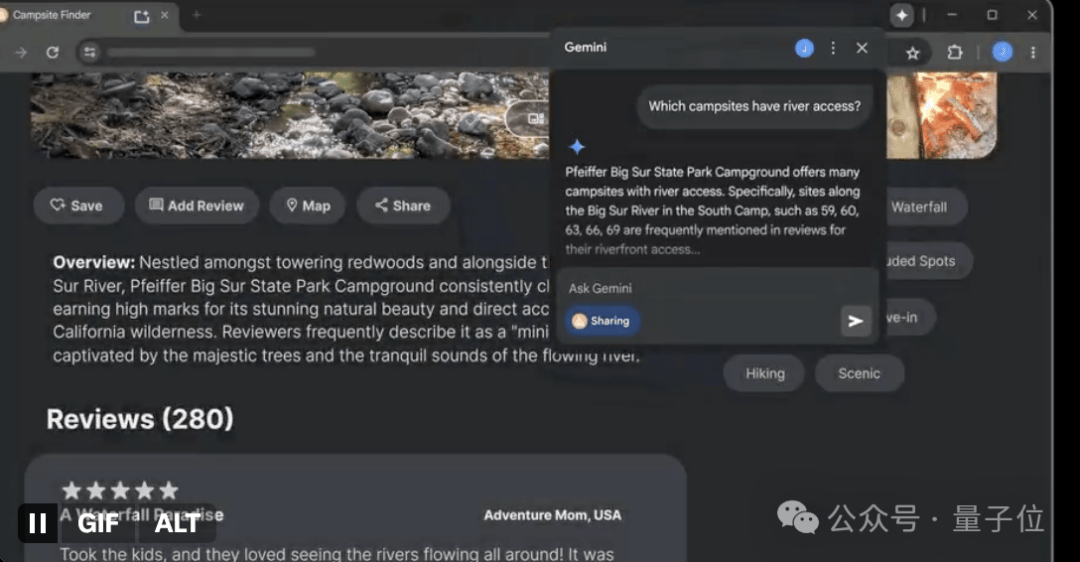
…
Regarding new products, the original naked-eye 3D video calling project, Starline, has been upgraded into an AI-driven 3D video communication platform called Google Beam.
It uses a series of cameras to capture images from different angles. AI then merges these video streams to display them on a 3D light field screen, achieving head-tracking accuracy down to the millimeter and frame rates up to 60 frames per second.
The combination of AI video models and light field display technology creates a sense of dimensionality and depth, allowing users to make eye contact, observe subtle expressions, and build understanding and trust, just as if they were face-to-face.

Additionally, there is Jules, an asynchronous AI coding assistant that allows human users to focus on other tasks while it operates in the background.
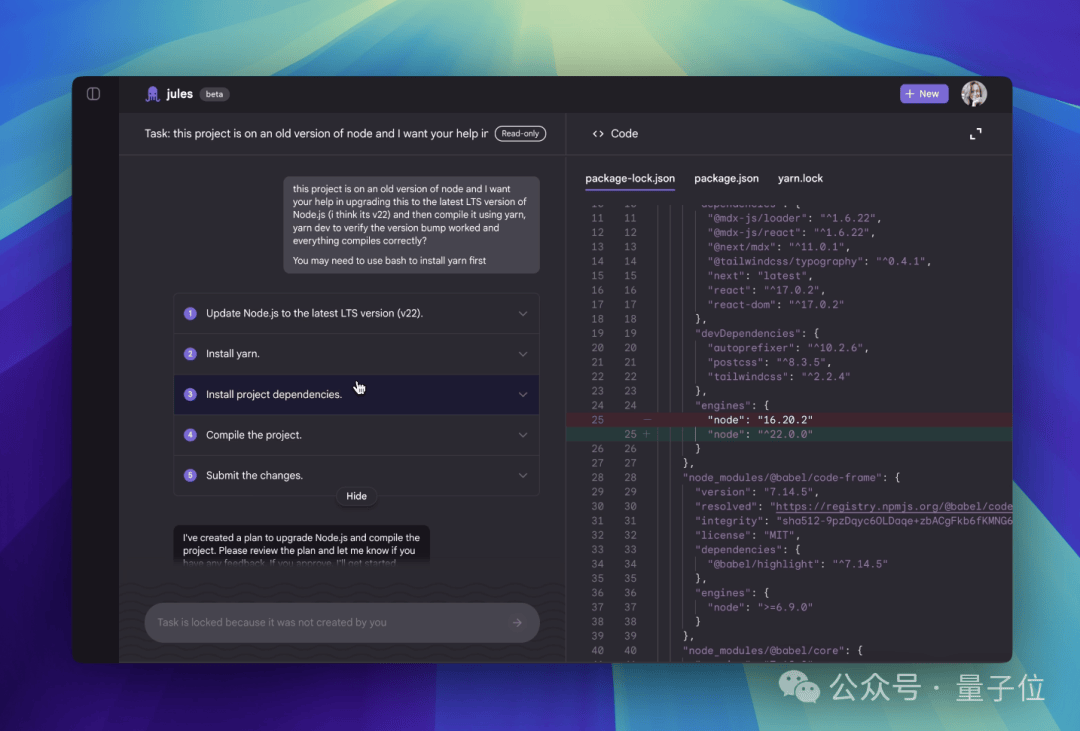
There is also Flow, an AI filmmaking tool that integrates multiple multimodal models to turn creative ideas into stories.

Collaborating with eyewear brands Gentle Monster and Warby Parker, Google has developed AI glasses equipped with cameras, microphones, and speakers. These glasses work in tandem with smartphones, allowing users to access apps without taking their phones out of their pockets.
Empowered by the Gemini model, these AI glasses can see and hear everything you do, helping them understand your context, remember important details, and provide assistance throughout the day.

Let’s look at the details of each section below.
Gemini 2.5 Series Models Fully Upgraded
The Gemini 2.5 series, including both Pro and Flash versions, has undergone significant upgrades.
First, let’s look at Gemini 2.5 Pro. In addition to performing well in academic benchmarks, it now leads the popular coding leaderboard WebDev Arena with an ELO score of 1415, a 142-point improvement over its previous version:
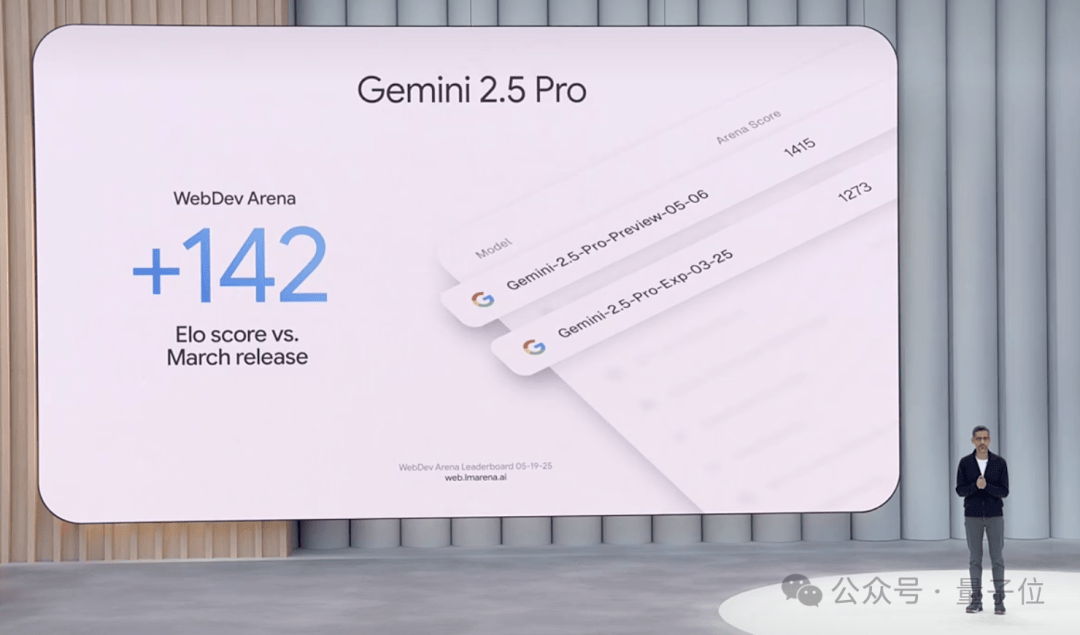
It also dominates LMArena, which evaluates human preferences across various dimensions:
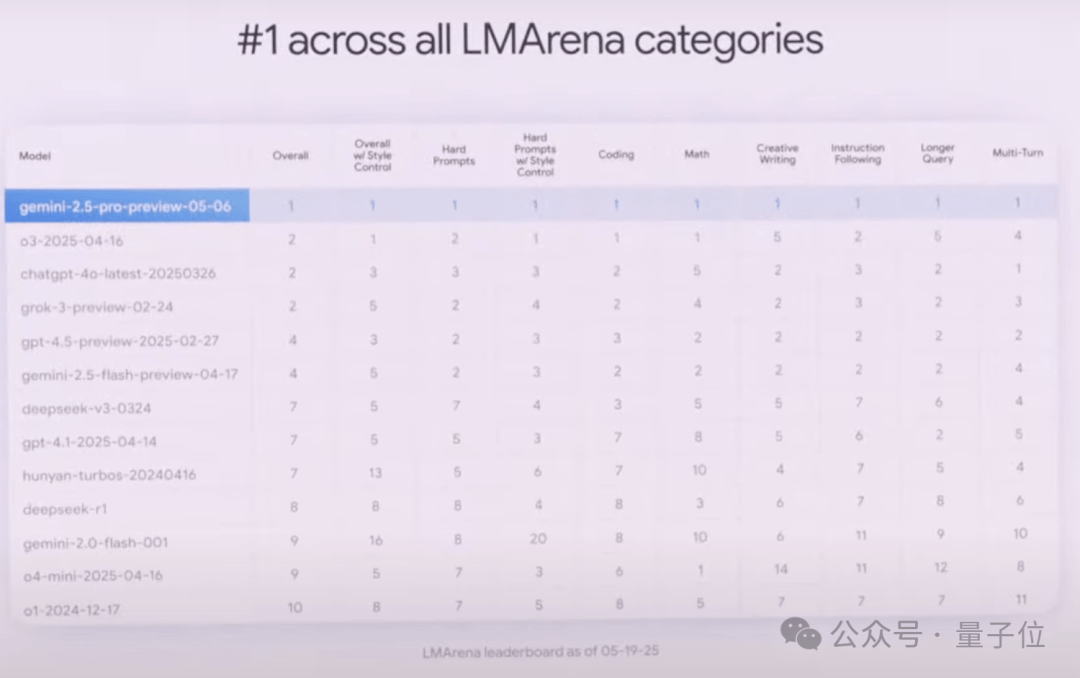
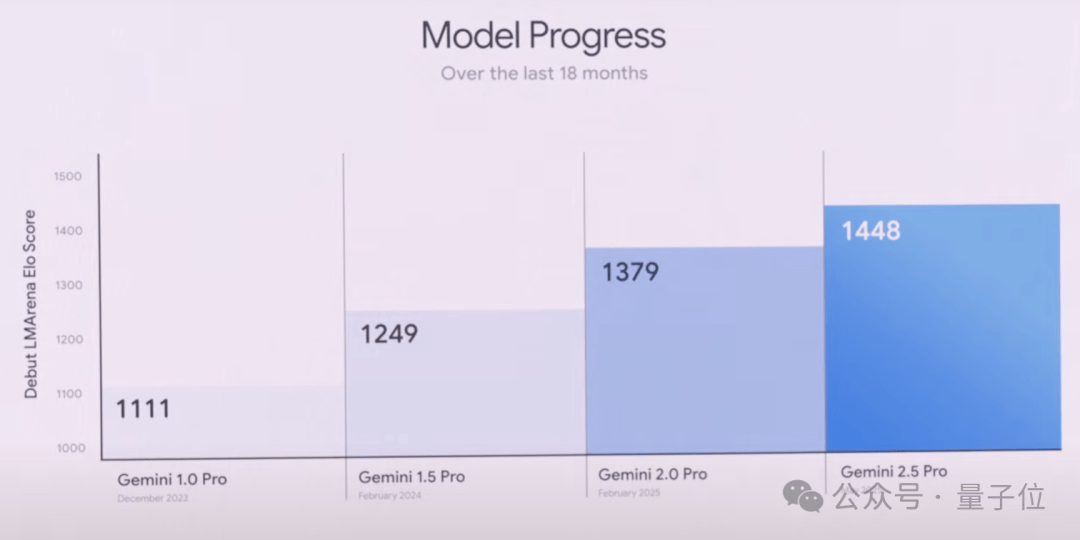
According to Google, with its million-token context window, the 2.5 Pro offers enhanced long-context and video understanding capabilities.
The 2.5 Pro also integrates LearnLM, a series of models developed by Google in collaboration with education experts. In direct comparisons evaluating pedagogy and effectiveness, educators and experts favored the 2.5 Pro across various scenarios.
Notably, the 2.5 Pro introduces a new Deep Think enhanced reasoning mode. This mode uses new technology that allows the model to consider multiple hypotheses simultaneously before responding.
How does it perform?
The 2.5 Pro scored impressively on the extremely difficult 2025 USAMO math benchmark, showed advantages in programming competition-level LiveCodeBench tests, and achieved an 84.0% score on the MMMU benchmark for testing multimodal reasoning.
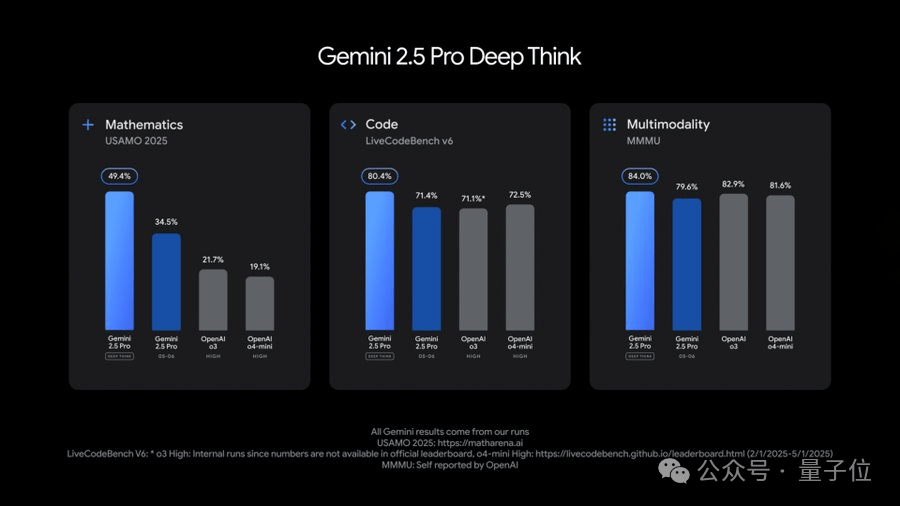
However, Google stated that Deep Think requires more time for frontier safety evaluations. Currently, this feature is only available to trusted testers via the Gemini API.
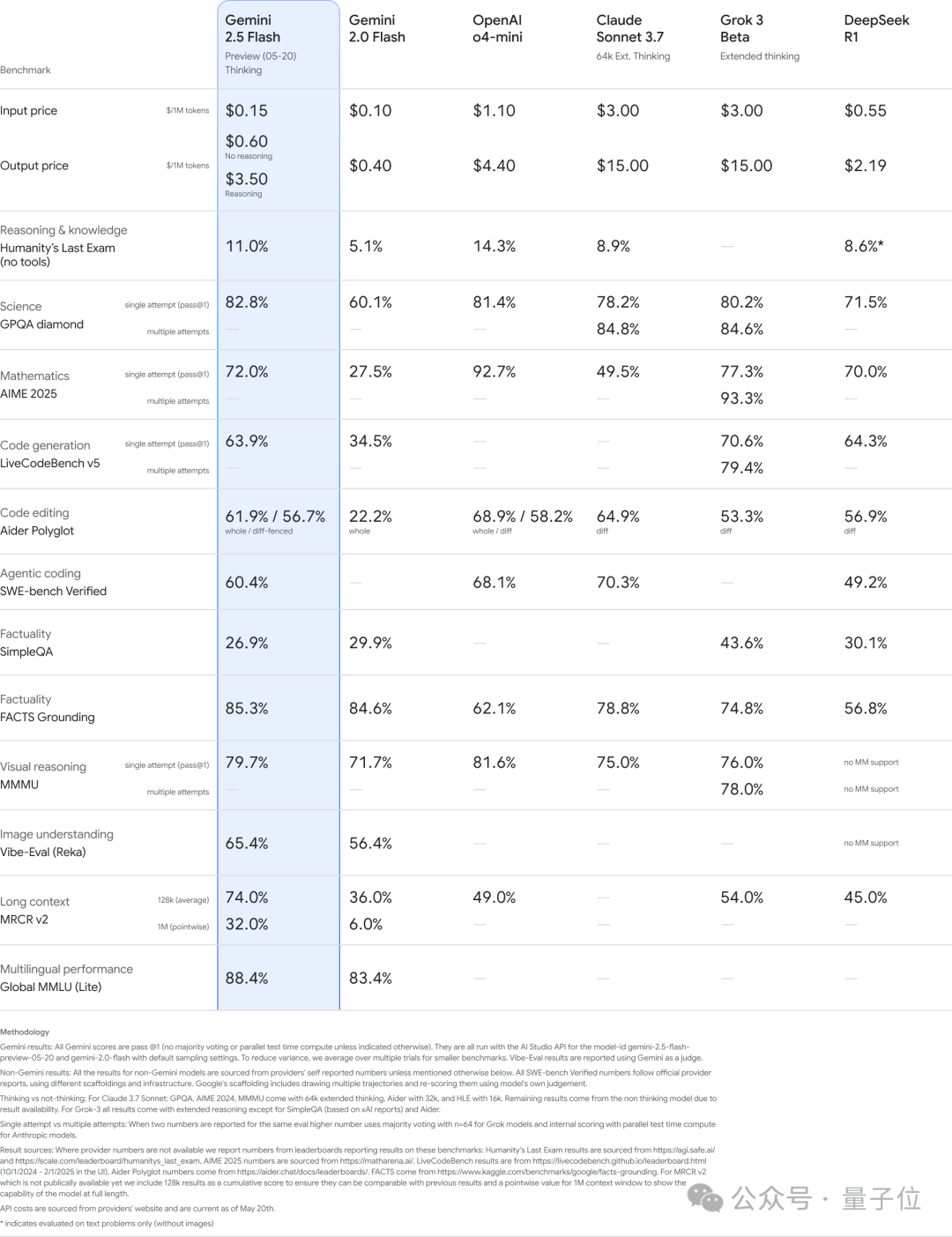
The 2.5 Flash model has also been upgraded, showing improvements in key benchmarks such as reasoning, multimodal capabilities, coding, and long-context handling. It is also more efficient, reducing token usage by 20-30% according to Google’s evaluations.
The new 2.5 Flash is now available for preview on Google AI Studio, Vertex AI, and the Gemini app.
Furthermore, the Gemini 2.5 series introduces several new features.
1. Native Audio Output & Live API Improvements
The Live API has launched a preview version supporting audiovisual input and native audio conversations, allowing users to build more natural and expressive Gemini dialogue experiences.
The model can adjust tone, accent, and speaking style according to user requests, making emotional changes audible.
Google has also introduced new text-to-speech (TTS) features for the 2.5 Pro and 2.5 Flash. For the first time, multi-speaker support is available, enabling dual voice synthesis through native audio output. This simulates two different voice characters speaking simultaneously or alternately, supporting 24 different languages.
This text-to-speech feature is now available in the Gemini API.
2. Computer Use Capabilities
Google is bringing the computer use capabilities from Project Mariner to the Gemini API and Vertex AI.
It supports multitasking, allowing up to 10 tasks to be executed simultaneously. A new “Learn and Repeat” feature has also been added, enabling the AI to learn how to automate repetitive tasks.

Video Link: https://mp.weixin.qq.com/s/Z2WkvmnYIVlmd43S2r35FA
3. Three Practical Features to Enhance Developer Experience for Gemini 2.5:
- Thought summaries: These organize the model’s raw thought process into a clear format with titles, key details, and information about model actions (such as tool calls), helping developers gain greater transparency into how the model thinks.
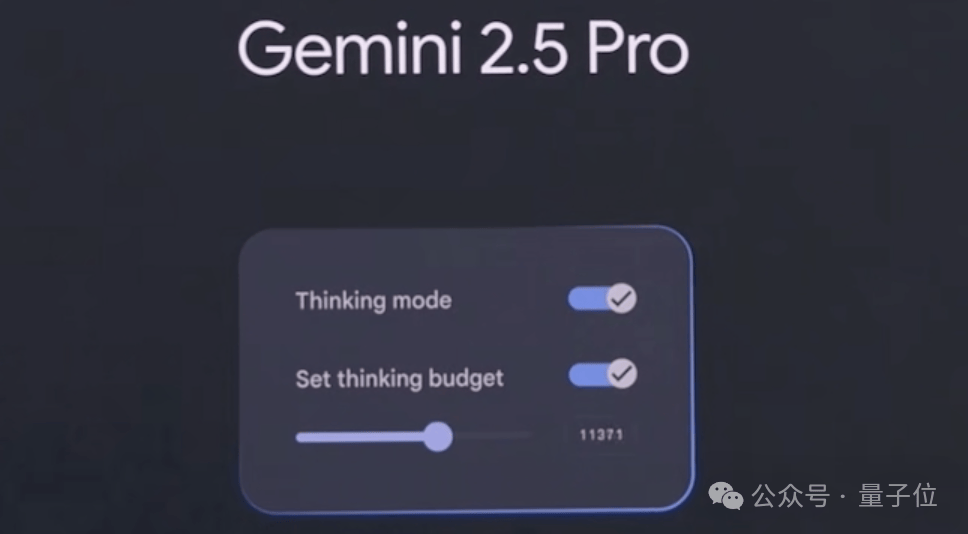
- Thinking budgets: Allow developers to control how many tokens the model uses for thinking;
- Gemini SDK compatibility with MCP tools: Enables easier integration with open-source tools.
Regarding the next steps for Google’s Gemini, Google DeepMind CE…
Demis Hassabis stated that they are working to expand their best Gemini models into a “world model,” enabling the system to plan and imagine new experiences by understanding and simulating the world, much like the human brain.
Asynchronous Code Assistant Jules
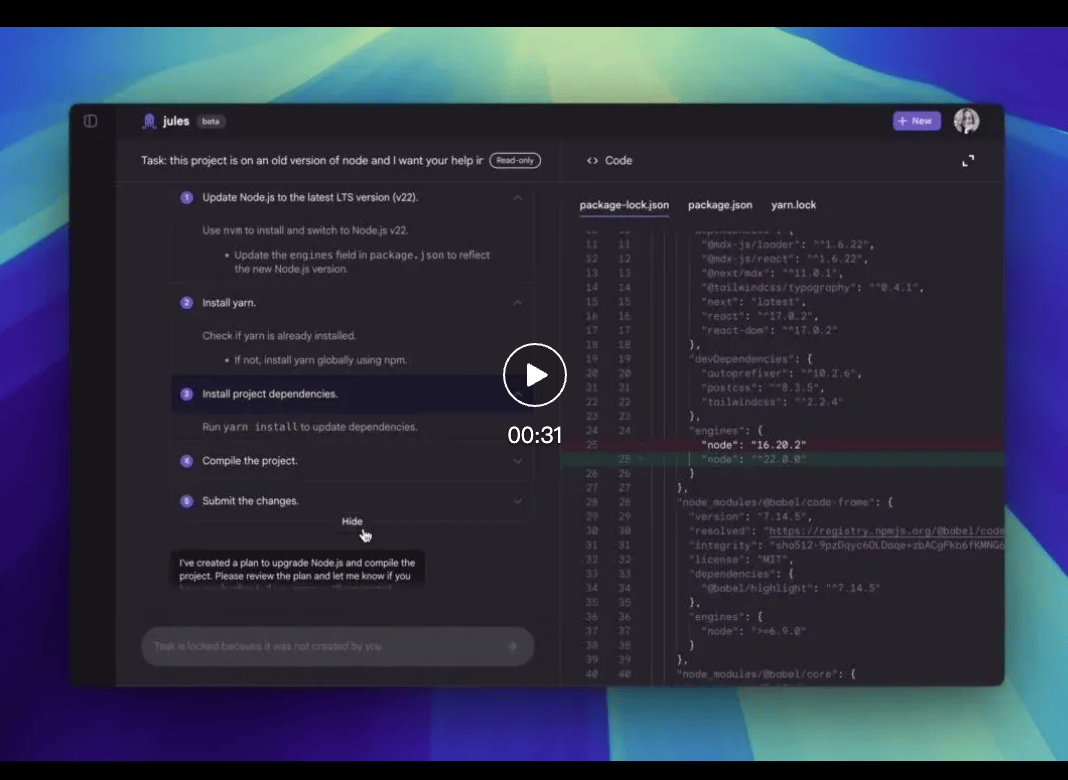
The asynchronous code assistant Jules has officially entered public beta, allowing developers worldwide to experience it without delay.
Jules clones your codebase into a secure Google Cloud virtual machine (VM) to fully understand the project context. It can write tests, build new features, provide audio update logs, fix bugs, and update dependency versions.
Operating asynchronously, Jules allows you to focus on other tasks while it works in the background. Upon completion, it displays its plan, reasoning process, and changes made. Work within private repositories remains private by default, and Jules does not use your private code for training.
Powered by Gemini 2.5 Pro, Jules possesses state-of-the-art coding reasoning capabilities. Combined with the cloud VM system, it can handle complex multi-file changes and concurrent tasks.
The public beta is completely free but subject to usage limits; paid plans are expected after the platform matures.
Video Link: https://mp.weixin.qq.com/s/Z2WkvmnYIVlmd43S2r35FA
Google Search Introduces AI Mode
In the realm of search, Google announced at I/O that it is officially introducing AI Mode to its search engine, making it fully available to users in the United States.

AI Mode is a search engine rebuilt around Gemini 2.5, integrating Gemini’s most advanced capabilities to provide end-to-end AI search.
It utilizes query fan-out technology, automatically breaking down questions into multiple sub-topics and searching them simultaneously. This allows for deeper and more comprehensive mining of web information compared to traditional search methods.
Google previewed a series of future features for AI Mode:
Deep Search, which can automatically initiate hundreds of searches, integrate information across domains, and generate expert-level reports with detailed citations, saving significant manual research time.
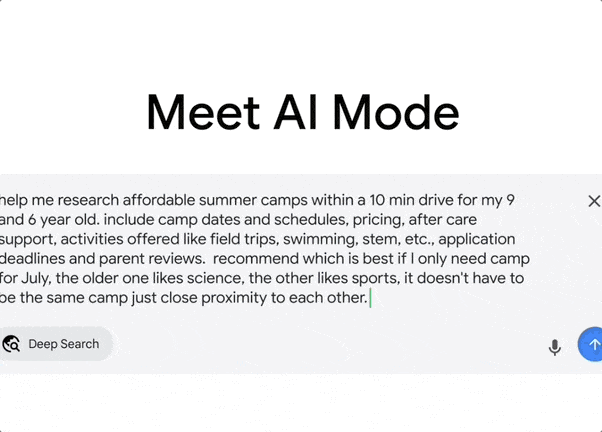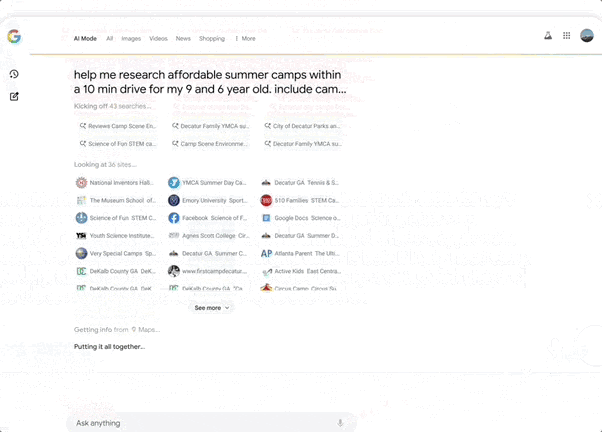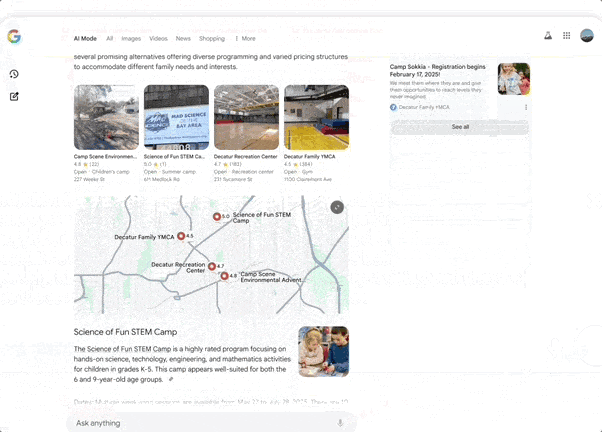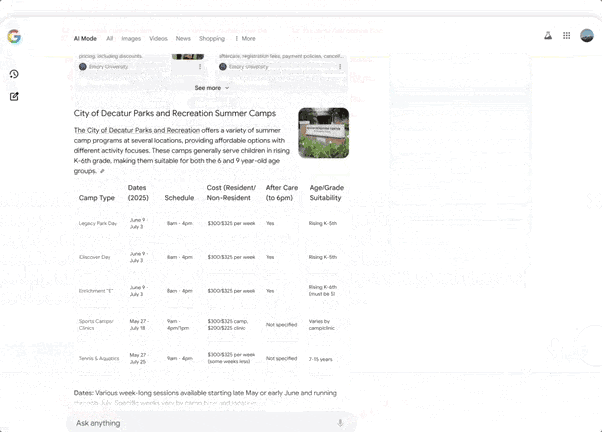
Search Live, an interactive search feature where users simply tap the “Live” icon in AI Mode and ask questions via their phone’s camera. The AI can interpret the visual content and provide real-time voice answers along with relevant resource links.
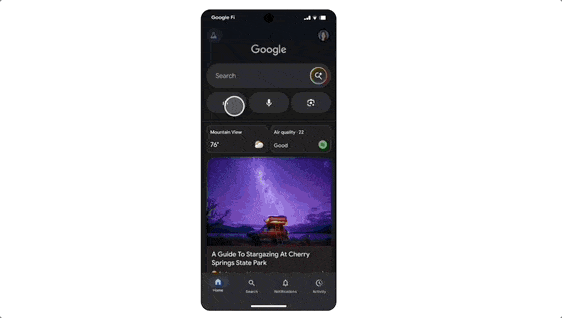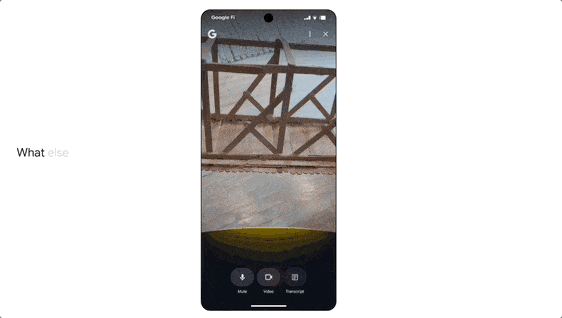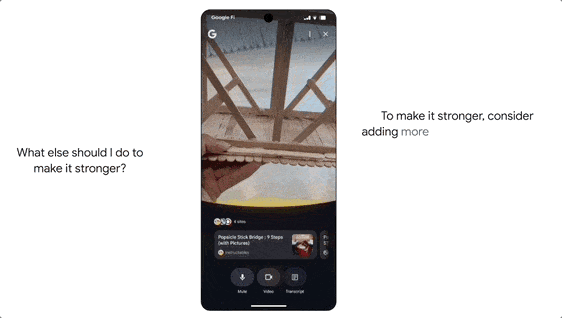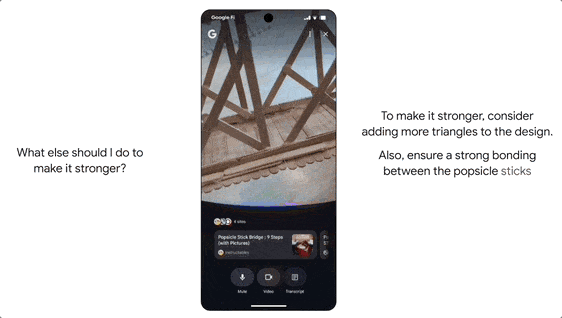
It also features agent capabilities. For example, if a user wants to buy concert tickets, they can simply state their request. AI Mode will scour ticketing information across various platforms, identify the best options, and pre-fill order details. The user only needs to confirm the suitable option to complete the purchase on their preferred website.
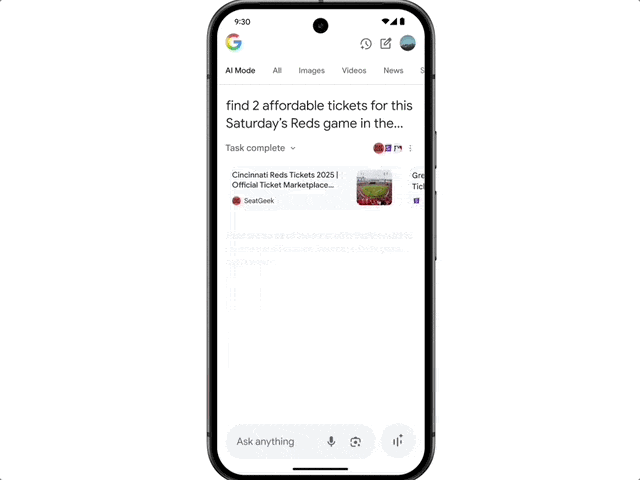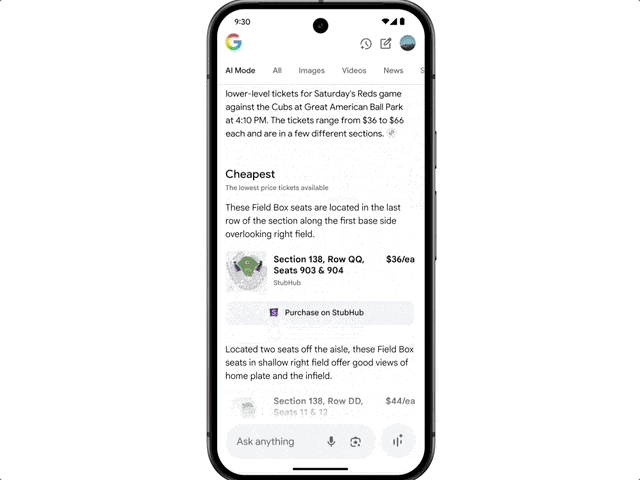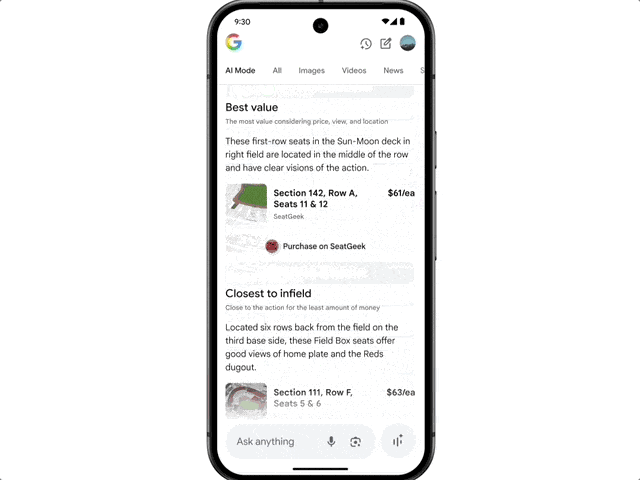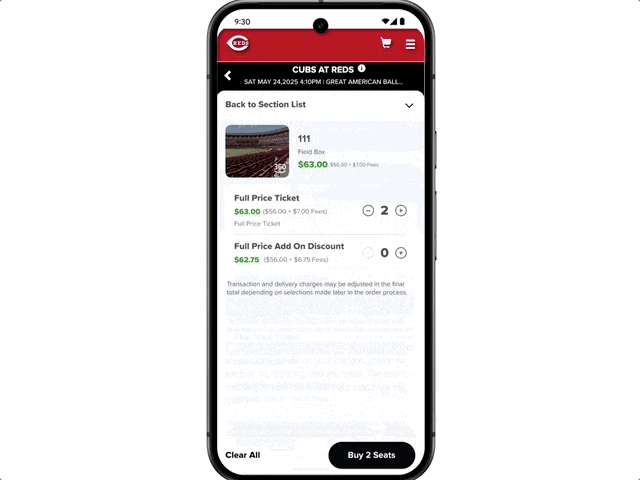
Google also highlighted a new shopping experience brought by AI Mode.
This new experience combines Gemini’s intelligence with the Shopping Graph, integrating over 50 billion high-quality product listings to help users browse, organize needs, and filter products.
When users decide to purchase, a new smart checkout feature facilitates transactions easily within their budget.
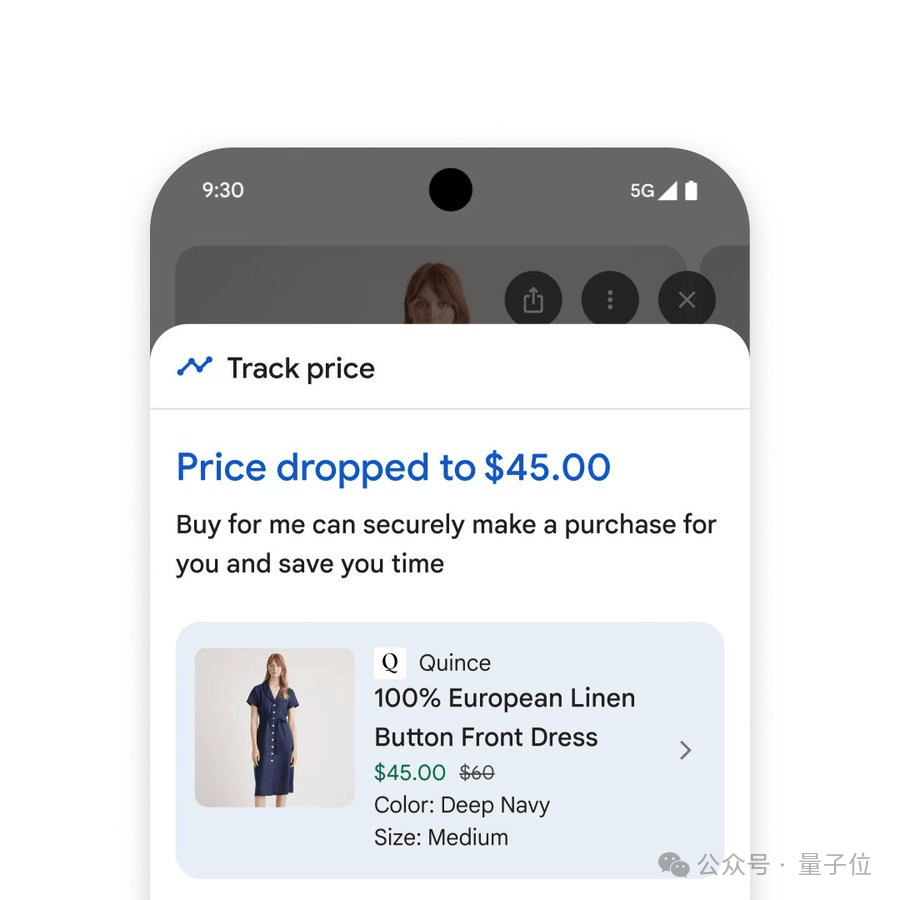
By clicking “Track Price” on any product page and setting parameters such as size, color, and budget, users will receive notifications when the price drops. After confirming purchase details and clicking “Buy for Me,” the system automatically adds the item to the cart and securely completes the checkout via Google Pay.
Additionally, when buying clothes, it offers a virtual try-on tool that supports user selfies. By uploading a selfie, users can virtually try on countless garments, with the AI model accurately rendering the drape and folds of different materials.

Comprehensive Upgrade of Multimodal Models
In the multimodal sector, Google also unveiled its latest video generation model, Veo 3, and image generation model, Imagen 4.
Veo 3 achieves native audio-visual synchronization for the first time. Whether it is traffic noise on city streets, bird songs in a park, or character dialogue, all can be generated via text prompts.
Users simply need to tell a short story using a prompt, and the model generates vivid video clips.
From text/image prompts to simulating real-world physical effects and precise lip-syncing, Veo 3 performs exceptionally across all dimensions.
Veo 3 is now available to US Ultra subscribers, and enterprise users can access it via the Vertex AI platform.

Video Link: https://mp.weixin.qq.com/s/Z2WkvmnYIVlmd43S2r35FA
Alongside the new model, Veo 2 has added several new features, including reference-driven video generation, camera control, image expansion, and object addition/removal. These features are already available in Flow and will be launched via the Vertex AI API in the coming weeks, with integration into more products expected over the next few months.
Google’s latest image generation model, Imagen 4, combines speed and precision. It is ten times faster than its predecessor, producing images with stunning fine details—from complex fabrics and water droplets to animal fur—while excelling in both realistic and abstract styles.

Imagen 4 supports various aspect ratios and up to 2K resolution. Its text spelling and typography capabilities have significantly improved, making it easy to create greeting cards, posters, and comics.

Imagen 4 is currently live on the Gemini app, Whisk, Vertex AI, and other platforms.
Additionally, Google introduced Flow, a next-generation AI filmmaking tool designed for creatives. It integrates Google’s strongest visual models (Veo, Imagen, and Gemini).
Flow boasts excellent prompt-following capabilities, outputting stunning cinematic visuals. The underlying Gemini model makes prompt input intuitive and easy to use; users can describe their creative vision in everyday language, import their own assets to create characters, or utilize Imagen’s text-to-image functionality within Flow to generate story elements.
Once a character or scene is created, these elements can be consistently reused across different clips and scenes, or a new shot can be initiated from a single scene image.

Video Link: https://mp.weixin.qq.com/s/Z2WkvmnYIVlmd43S2r35FA
Starting today, US Google AI Pro and Ultra subscribers can be the first to use Flow.
One More Thing
During the keynote, CEO Sundar Pichai revealed a significant statistic.
In April last year, Google products and model APIs collectively processed 9.7 trillion tokens per month.
Over the past year, this figure has grown by 50 times, now processing over 480 trillion tokens monthly.
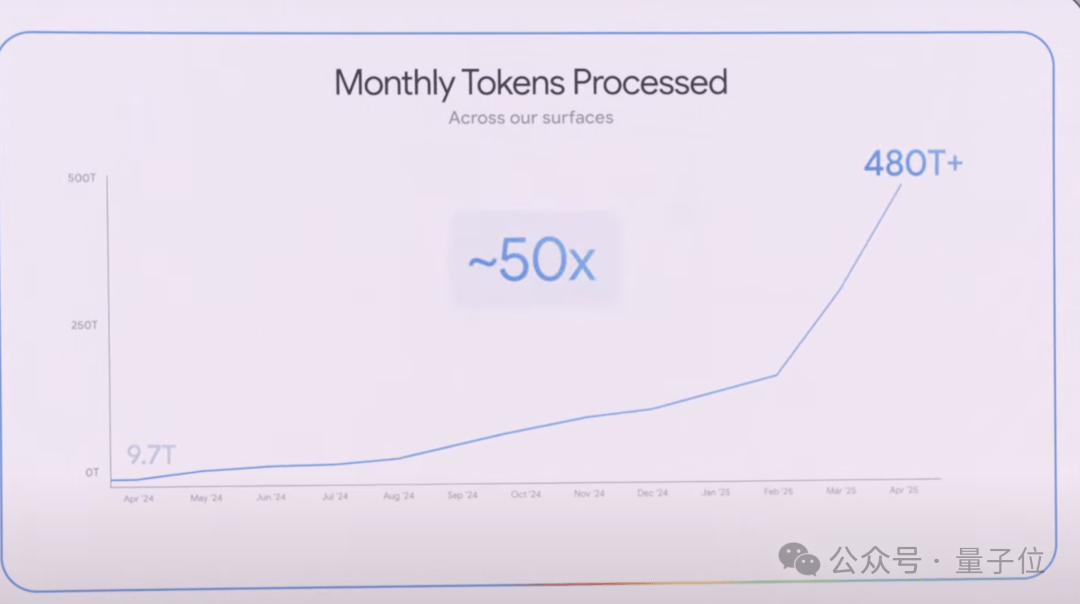
The world is adopting artificial intelligence faster than ever before.
Video Replay: https://www.youtube.com/watch?v=o8NiE3XMPrM_
References
- Google I/O 2025 Press Site.prezly — google-i-o-2025-press-site.prezly.com/