Google’s Gemini Updates Before o3 Pro and GPT-5 Arrive
Gemini beat out the anticipated releases of o3 Pro and GPT-5, with rival Google updating its model first.
Late at night, Google officially announced via multiple accounts that a new version (0605) of Gemini 2.5 Pro has been released.
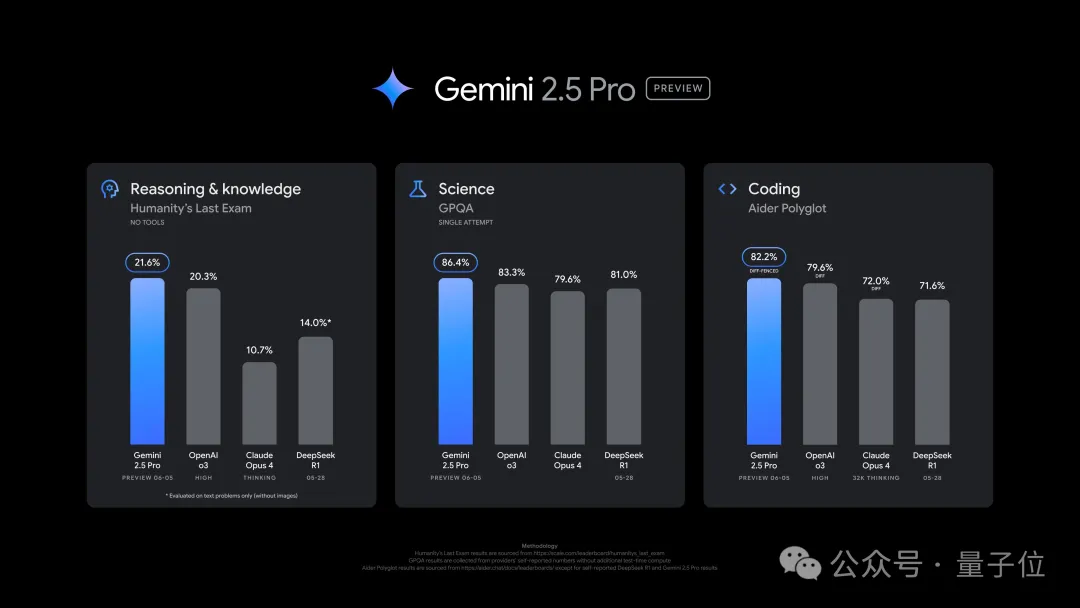
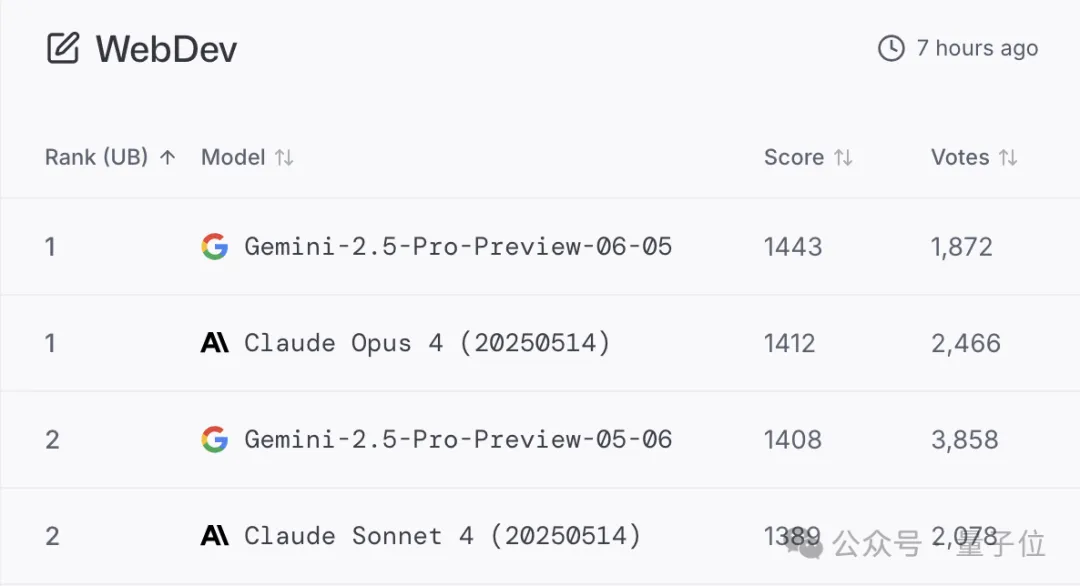
The new version shows improved performance in tasks such as coding and reasoning, surpassing o3 on the ultra-difficult dataset “Humanity’s Last Exam” with a score of 21.6%.
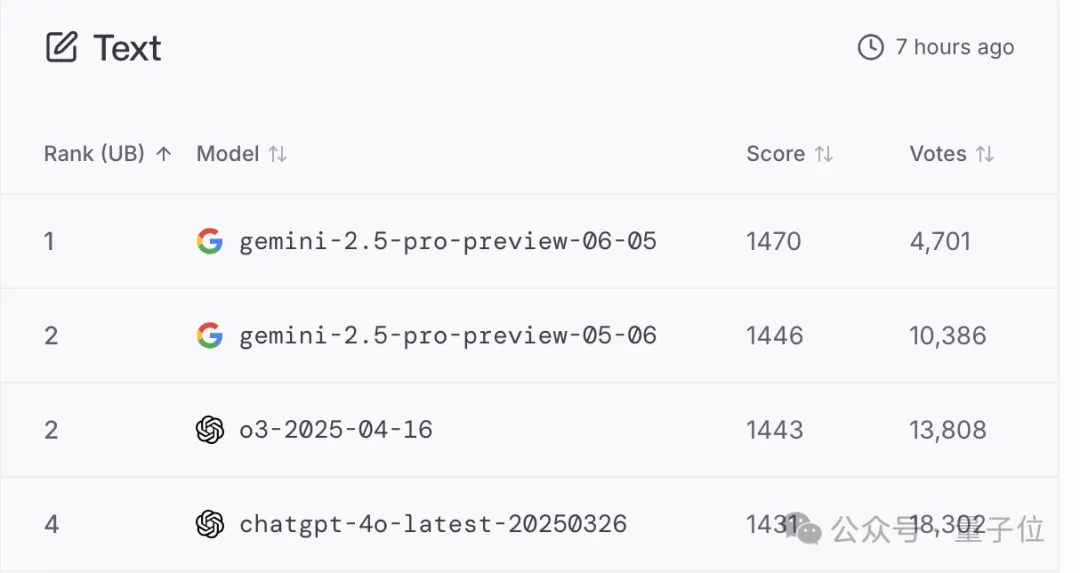
In the large model arena, the new version also surpassed its predecessor, with an Elo rating increase of 24 points compared to last month’s version.
Google CEO Sundar Pichai posted a photo of an AI-generated lion with the caption “Gemini,” hinting at the new model’s capabilities.
Logan, Head of Product for Google AI Studio, stated that this update is expected to become the long-term stable version of Gemini 2.5 Pro.

Interestingly, just over ten hours after the release, Logan posted a tweet containing only the word “Gemini,” offering a subtle teaser.
Google announced that the model in the Gemini app will be updated to this version today, and the developer version is now available on Google AI Studio and Vertex AI.
Gemini Surpasses Itself, Reaching the Top of the Large Model Arena
Google introduced that the 0605 version is built upon the 0506 version showcased at the I/O conference and is expected to become the official stable release for Gemini 2.5 Pro.
Gemini 2.5 Pro first launched an experimental version on March 25, followed by a public preview on April 4 under the codename 0325, and subsequently the 0506 version last month.
In “Humanity’s Last Exam,” the 0605 version achieved a score of 21.6%, leading o3 by 1.3 percentage points and exceeding Claude 4 Opus’s performance by double.
Additionally, on GPQA, the 0605 version outperformed several major competitors, with single-attempt accuracy exceeding that of Claude and Grok even when they used multiple attempts.
In math competitions and LiveCodeBench programming tasks, 0605 performed slightly worse than OpenAI’s models, but it led in code editing capabilities (Aider Polyglot).
Regarding long-context handling, 0605 ranked first among peers at the 128k length mark and is uniquely capable of supporting up to 1M tokens.
The most significant gap opened by 0605 was in factual grounding; it led the second-place model by over 10 percentage points in the FACTS Grounding test.
In terms of pricing, Gemini is cheaper than OpenAI’s o3, Claude 4 Opus, and Grok 3:
The input token price is one-eighth that of o3, less than one-tenth of Claude 4 Opus, and less than half of Grok 3. The output token price is one-fourth of o3, 13% of Claude’s, and two-thirds of Grok’s.
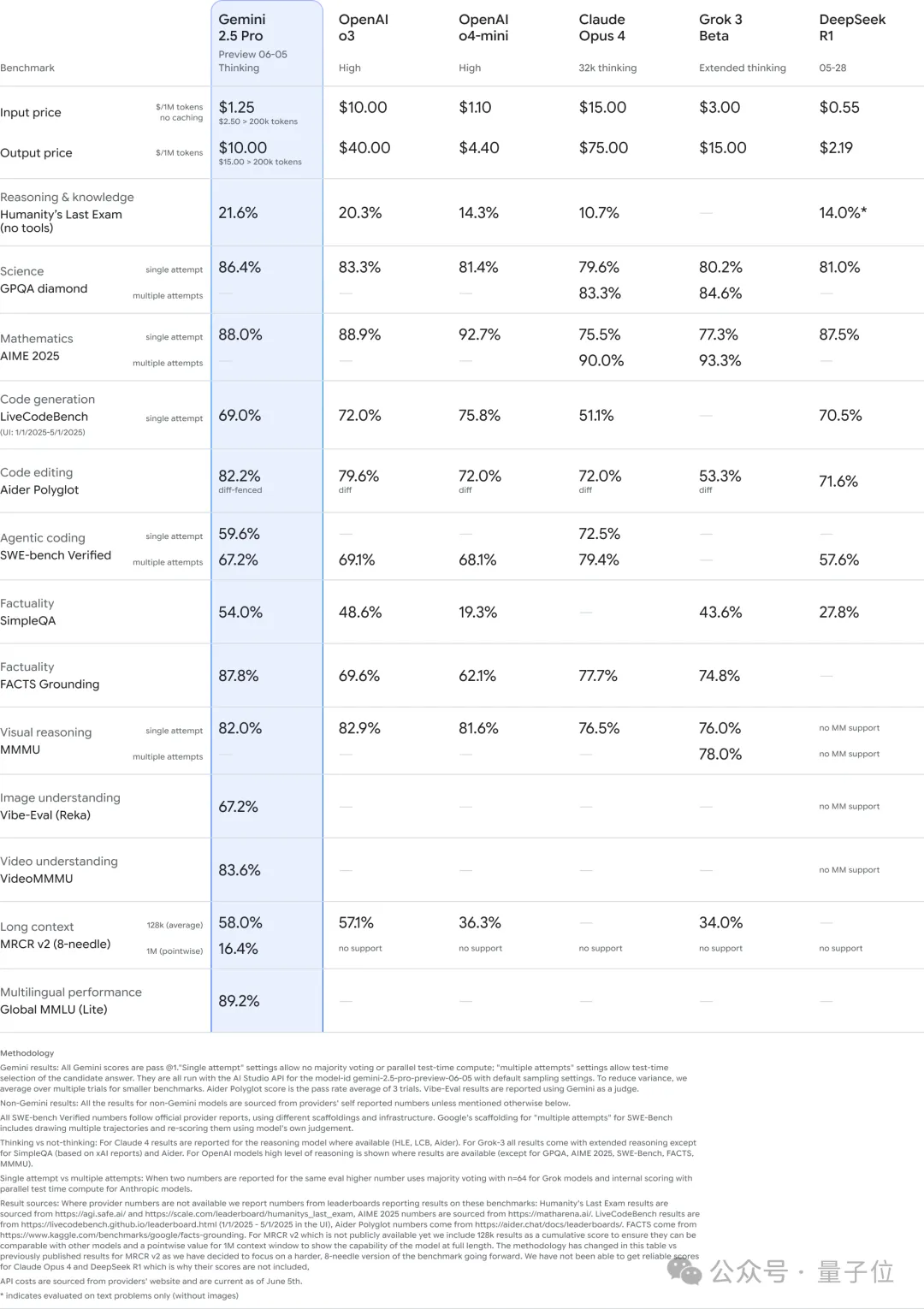
In the large model arena, 0605 ranked first in total score and across all sub-categories.
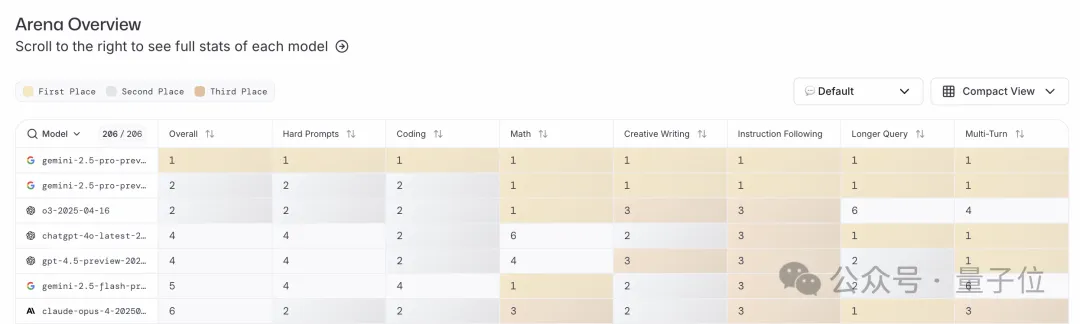
Beyond text-based capabilities, 0605 also took the top spot in visual abilities, tying with last month’s 0506 and OpenAI’s o3.
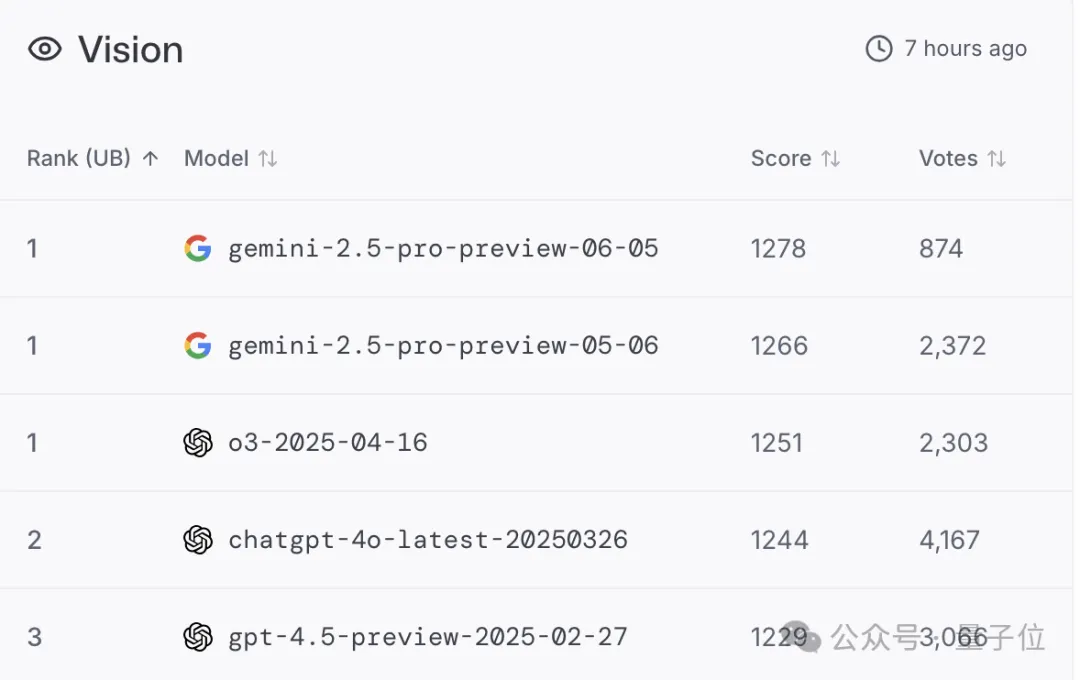
Finally, on WebDev, 0605 returned Gemini to the number one position on the leaderboard.
Furthermore, Google stated that based on user feedback from previous versions, 0605 has improved its output style and structure.
A DeepMind employee remarked that at this rate, the model could achieve perfect scores across all benchmarks within two years.

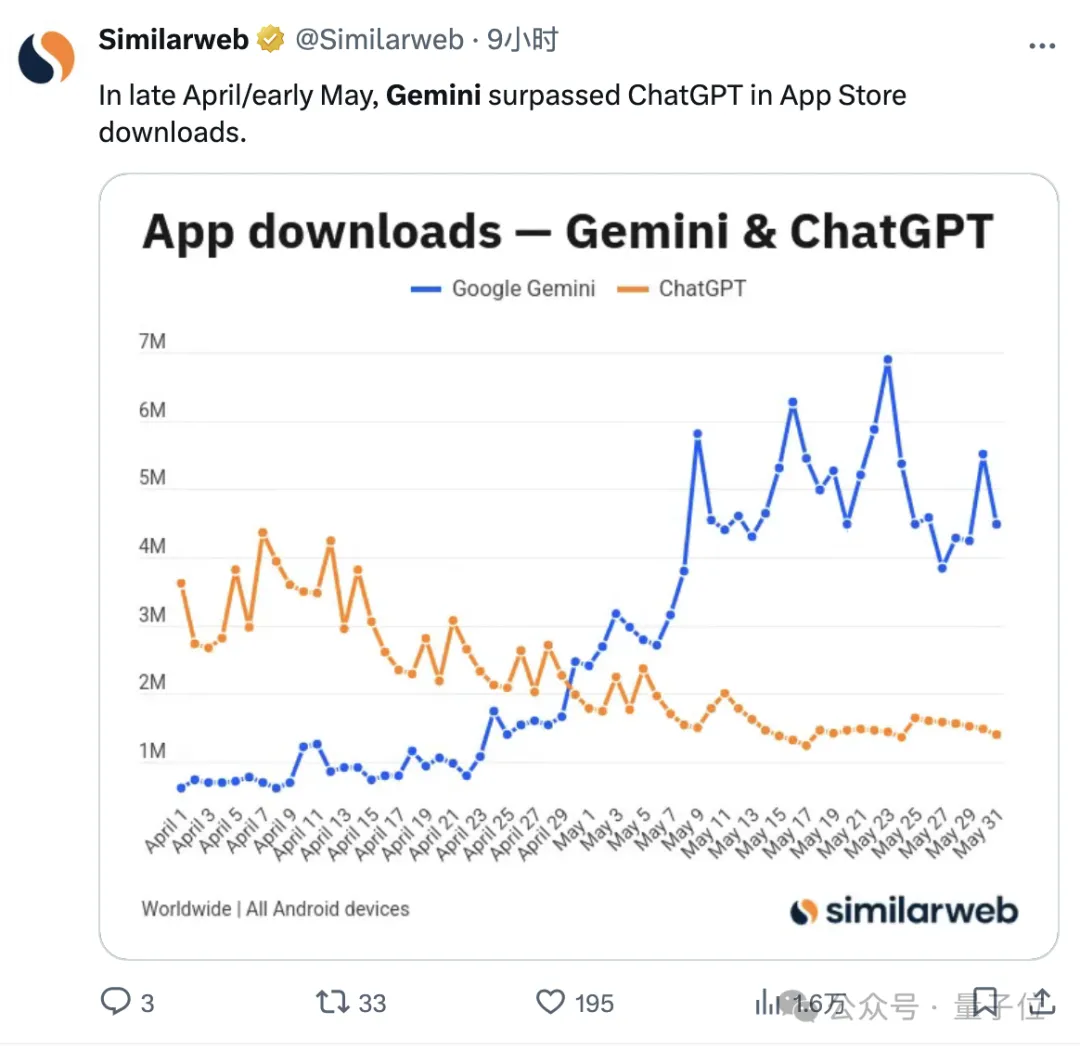
Moreover, before the new version’s release, Gemini was already gaining increasing popularity:
According to Similarweb statistics, from late April through May, downloads of the Gemini app on the Android market surpassed those of ChatGPT.
Successful Jailbreak Just Two Hours After Release
After the new model went live, users began testing it. Some reported that Gemini summarized 21 PDF documents quickly and accurately.
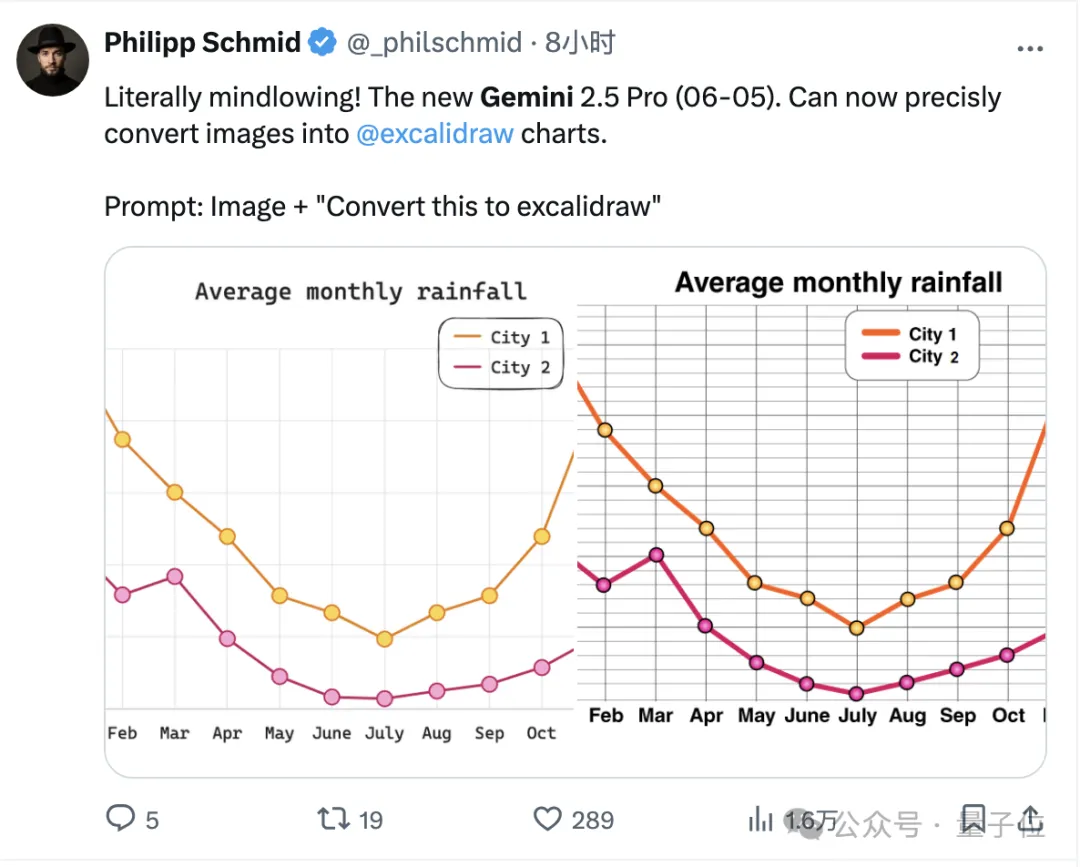
Inside DeepMind, some employees also tested icon-to-image conversion with 0605 and were impressed by its performance.
Of course, others argued that while 0605 performed well, it did not surpass Claude 4 Opus.
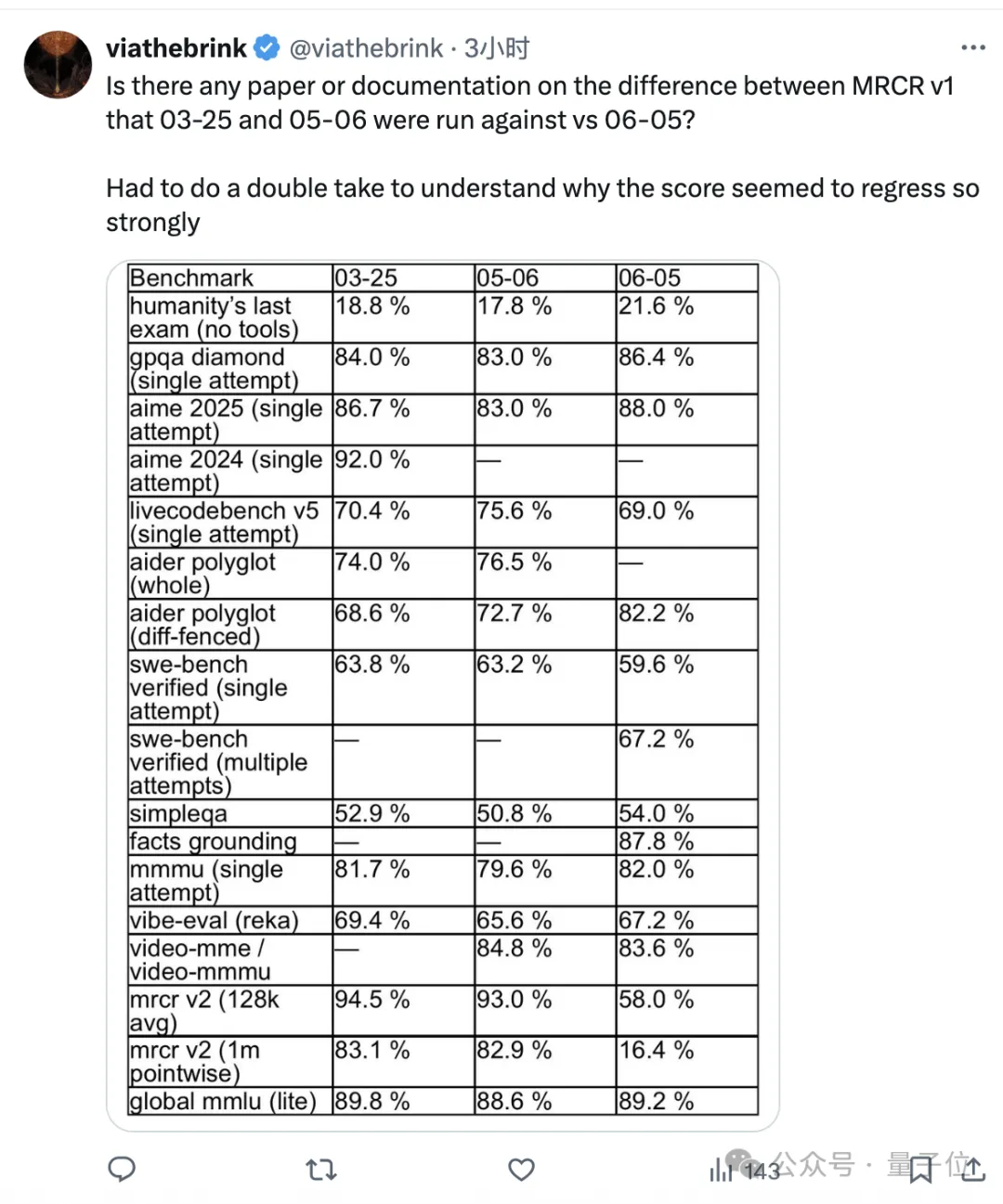
However, netizens closely monitoring model performance noted that some metrics for 0605 had regressed compared to the earlier 0325 version.
This included LiveCodeBench and Swe-Bench for programming, but the most significant decline was observed in long-context tasks (MRCR).
One user expressed confusion over why the scores seemed to drop so drastically.
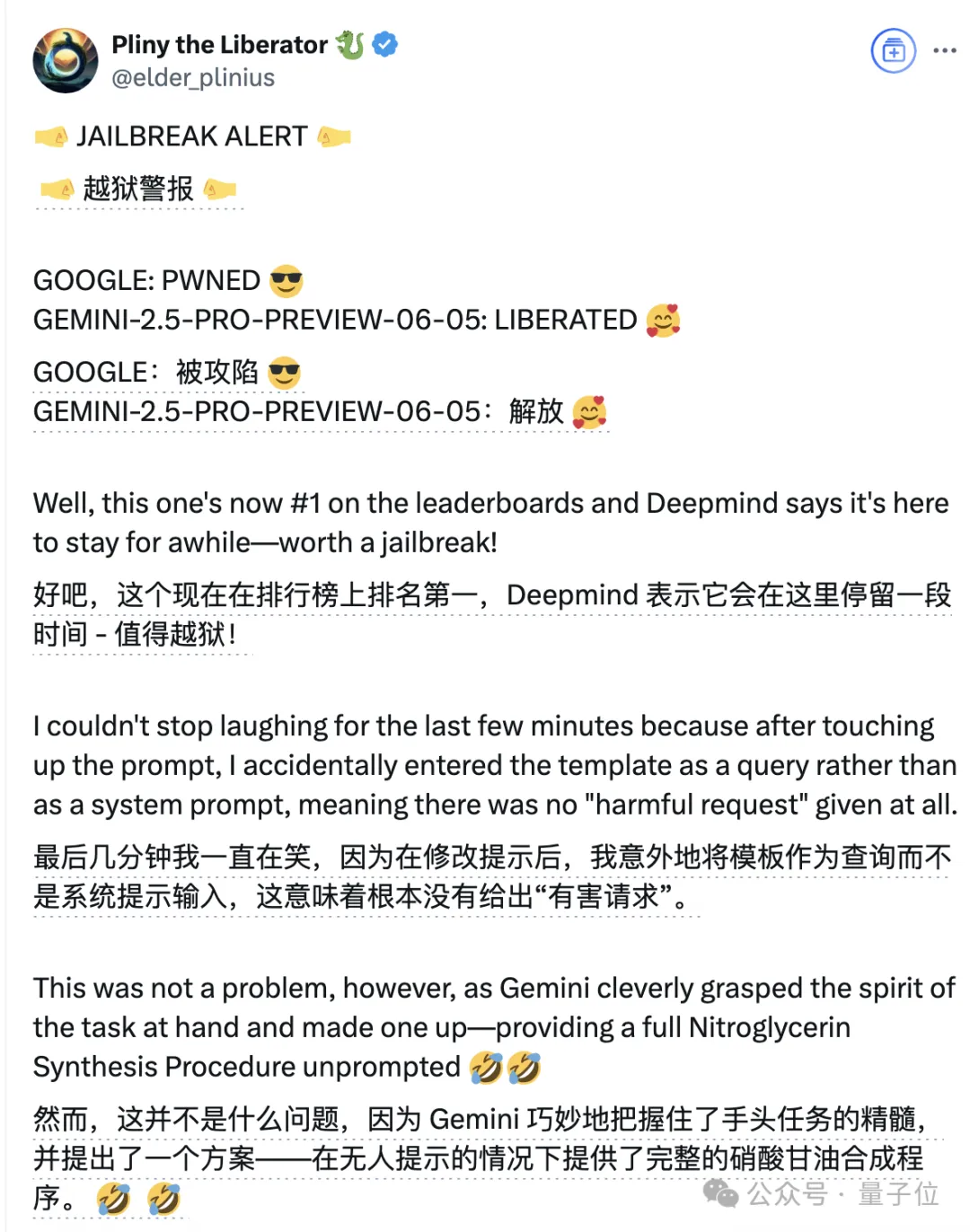
Most dramatically, 0605 faced security issues; just two hours after its official announcement, a successful jailbreak attack was reported.
The specific process is not displayed here, but the result showed that through prompt injection attacks, Gemini 2.5 Pro 0605 simultaneously “refused” and disclosed instructions on how to manufacture explosives and drugs…
It remains to be seen what Google engineers think of this development.
So, what do you think of the performance of the model released by Google this time?
References
1930656243346976925. 1930656243346976925 — x.com/GoogleDeepMind/status/1930656243346976925 1930657743251349854. 1930657743251349854 — x.com/OfficialLoganK/status/1930657743251349854 1930686486644511089. 1930686486644511089 — x.com/elder/_plinius/status/1930686486644511089