Submitted by the General-Level Team
Multimodal Large Language Models (MLLMs) are rising rapidly, evolving from systems that could only understand a single modality to those capable of simultaneously understanding and generating images, text, audio, and even video.
When it comes to answering “how to comprehensively and objectively evaluate multimodal large models,” the traditional approach has been to aggregate scores across multiple tasks. However, simply measuring model strength by “higher scores on more tasks” is unreliable; excelling in certain tasks does not necessarily imply that a model is closer to human-level intelligence across all domains.
Therefore, as AI competitions enter their “second half”—a consensus view sparked recently by OpenAI researcher Shunyu Yao—designing scientific evaluation mechanisms has become the core key to determining victory.
The paper On Path to Multimodal Generalist: General-Level and General-Bench, recently accepted for Spotlight presentation at ICML ’25, proposes a brand-new evaluation framework called General-Level and a companion dataset named General-Bench, providing foundational answers and breakthroughs to this issue.

This evaluation framework has been deployed within the community: The project team behind the aforementioned paper constructed an ultra-large-scale evaluation benchmark and the industry’s most comprehensive multimodal generalist model Leaderboard, covering over 700 tasks, five common modalities, 29 domains, and more than 320,000 test data points. This provides the infrastructure for fair, impartial, and comprehensive comparisons among different multimodal generalist large models.
General-Level Evaluation Algorithm: Five-Tier Rank System and Synergy Effects
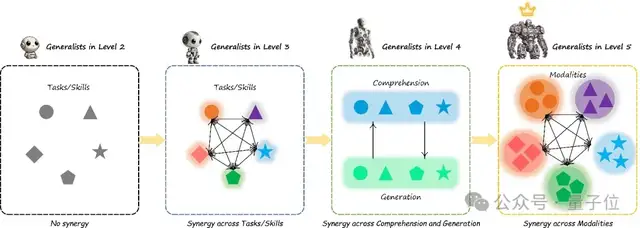
The General-Level evaluation framework introduces a five-tier rank system, measuring the generalist capabilities of multimodal models through a “rank promotion” mechanism similar to gaming tiers.
The core of General-Level assessment lies in Synergy, which refers to the model’s ability to transfer knowledge learned from one modality or task to enhance performance in another. In simple terms, this is the effect where 1+1 > 2.
Model ranks range from low to high as follows: Level-1 Specialist Expert, Level-2 Generalist Rookie (No Synergy), Level-3 Task-Level Synergy, Level-4 Paradigm-Level Synergy, and Level-5 Full Cross-Modal Total Synergy. A higher rank indicates stronger “general intelligence” demonstrated by the model and a deeper level of synergy achieved.
General-Level determines a model’s rank by examining synergistic effects at different levels:
- Level-1 Specialist (Specialist)
- This tier includes current specialized models for individual tasks, typically SOTA (State-of-the-Art) models fine-tuned to the extreme on specific datasets or tasks.
- Level-2 Entry-Level Generalist (Generalist, No Synergy)
- Reaching Level-2 means the model begins to possess “one specialty with multiple capabilities,” supporting various modalities and tasks, but has not yet demonstrated synergistic gain effects.
- Level-3 Task-Level Synergy
- Promotion to Level-3 requires the model to exhibit task-level synergistic improvements. This means that through multi-task joint learning, the model’s performance on certain tasks surpasses the SOTA of specialized models for those specific tasks.
- Level-4 Paradigm-Level Synergy
- To advance to Level-4, a model must demonstrate cross-paradigm synergy, creating synergistic effects between the two major task paradigms: “understanding” and “generation.” This rank signifies that the model has begun to possess “integrated generation-understanding” reasoning capabilities, enabling knowledge transfer across differences in task formats.
- Level-5 Full Cross-Modal Total Synergy (Cross-modal Total Synergy)
- This is the highest rank in the General-Level evaluation, marking that a model has achieved comprehensive synergy across modalities and tasks. It represents the ideal state of Artificial General Intelligence (AGI).
However, as of now, no model has reached Level-5.
Level-5 represents the ultimate goal on the path to AGI. Once a model enters this rank, it may signal that generalist AI has taken a critical step toward “Artificial General Intelligence.”

Overall, through this five-tier rank system, General-Level elevates the evaluation perspective from merely stacking task scores to examining the model’s internal knowledge transfer and integration capabilities.
This ranking system ensures objective quantification while providing the industry with a roadmap for progression from specialists to generalists, and finally to “all-rounders.”
General-Bench Evaluation Benchmark: A Super Exam Paper for Multimodal Generalists
General-Bench is hailed as the largest in scale, broadest in scope, and most comprehensive in task types among current multimodal generalist AI evaluation benchmarks.
It is not just a “generalist college entrance exam” paper testing multimodal AI capabilities, but also a panoramic evaluation system integrating breadth, depth, and complexity.
In terms of breadth, General-Bench covers five core modalities—images, video, audio, 3D, and language—truly achieving full-chain modality coverage from perception to understanding, and finally to generation.
In the dimension of depth, General-Bench not only includes numerous traditional understanding tasks (such as classification, detection, question answering, etc.) but also incorporates rich generation tasks (such as image generation, video generation, audio generation, description generation, etc.).
Notably, all tasks support free-form responses, limiting neither to multiple-choice nor true/false questions. Instead, they are objectively evaluated based on the open metrics native to each task, filling a long-standing gap in industry evaluation blind spots.
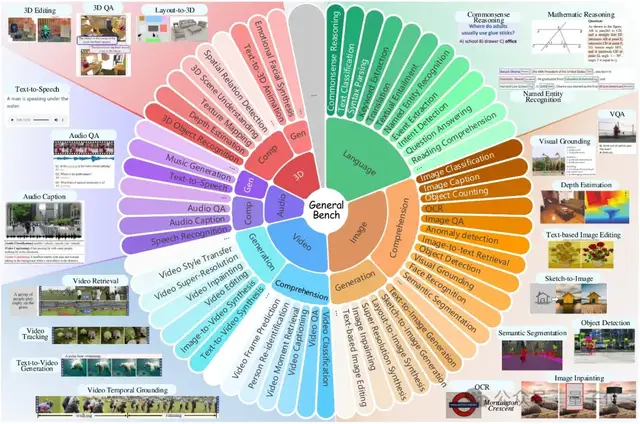
In terms of data scale, General-Bench aggregates over 700 tasks and more than 325,000 samples, subdivided into 145 specific skills. It comprehensively covers core capability points across visual, auditory, and linguistic modalities.
Behind these skills, General-Bench spans 29 interdisciplinary knowledge domains, encompassing natural sciences, engineering, healthcare, social sciences, and humanities. From image recognition to cross-modal reasoning, from speech recognition to music generation, and from 3D models to video understanding and generation, it covers everything.
Furthermore, General-Bench pays special attention to model performance in higher-order capabilities such as content identification, commonsense reasoning, causal judgment, sentiment analysis, creativity, and innovation, providing a multi-dimensional and three-dimensional evaluation space for generalist AI models.
In short, General-Bench is an unprecedentedly challenging comprehensive multimodal exam paper, comprehensively testing the breadth, depth, and integrated reasoning capabilities of AI models across modalities, task paradigms, and knowledge domains.
Currently, the total number of task samples in General-Bench has reached 325,876 and will continue to grow dynamically. This openness and sustainable updating ensure that General-Bench possesses long-term vitality, capable of continuously supporting the R&D and evolution of multimodal generalist AI.
Multi-Scope Leaderboard Design: From Full-Modal Generalists to Sub-Skill Generalists
With the General-Level evaluation standards and dataset in place, a transparent leaderboard is needed to present model evaluation results and rankings. This is precisely the function of the project’s Leaderboard system.
To balance comprehensive evaluation with participation barriers, the Leaderboard designs a multi-level Scope decoupling mechanism (Scope-A/B/C/D).
Different Scopes act as sub-leaderboards with varying ranges and difficulties, allowing models with different capabilities to showcase their strengths. Covering everything from an “all-around champion competition” to “single-skill competitions,” this ensures that top-tier generalist models have a stage to compete for the all-around crown, while ordinary models can choose appropriate scopes for comparison, lowering the barrier for community participation.
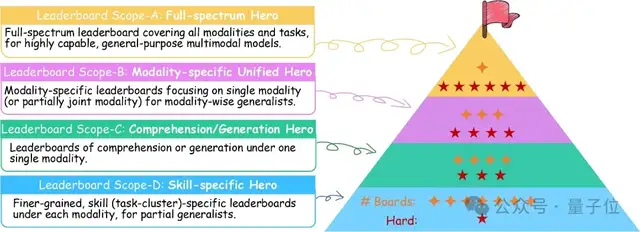
Scope-A: Full-Spectrum Hero Board: Competition among “Full-Modal Generalists.”
This is the most difficult and widest-reaching main leaderboard: Participating models must undergo the full test of the General-Bench collection, meaning a complete evaluation covering all supported modalities and all domain tasks.
Scope-A aims to select truly all-around multimodal foundation models, testing their comprehensive strength in fully complex scenarios.
Scope-B: Unified Modality Hero Board: Competition among “Single-Modal Generalists.”
Scope-B includes several sub-leaderboards, each targeting a specific modality or a limited combination of modalities.
Specifically, Scope-B divides into seven parallel boards: four are single-modality boards (e.g., pure vision, pure audio, pure video, pure 3D), and the other three are modality-combination boards (e.g., image + text, video + text, etc.).
Participating models only need to complete multi-task evaluations within their selected modality range, without involving data from other modalities.
Scope-C: Understanding/Generation Hero Board: Group competition based on “Paradigm Capabilities.”
Scope-C further subdivides evaluation into two major paradigms: understanding tasks and generation tasks, with separate boards for each modality. Specifically, within image, video, audio, and text modalities, there are separate “Understanding Ability Boards” and “Generation Ability Boards,” totaling eight boards.
Scope-C evaluation emphasizes cross-paradigm transfer capabilities within the same modality: For example, if a model performs excellently on the visual understanding board, it indicates shared knowledge capabilities across various understanding tasks like visual classification and detection; high scores on the visual generation board imply generalist capabilities across various generation tasks (description, drawing).
By limiting the scope of task paradigms, Scope-C has lower resource requirements (three-star difficulty), making it suitable for lightweight models or teams with limited resources.
Scope-D: Skill Specialty Board: An arena for niche skills.
This is the finest-grained and lowest-barrier category of boards. Scope-D clusters tasks from General-Bench by specific skills or task types, creating a separate board for each small category.
For example: “Visual Question Answering (VQA) Board,” “Image Caption Generation Board,” “Speech Recognition Board,” “3D Object Detection Board,” etc., with each board covering a group of closely related tasks.
Participating models can submit results targeting only one type of skill, allowing them to compete with other models in their narrowest area of expertise.
This skill-board mechanism encourages gradual model development: first achieving excellence in single-point skills, then progressively challenging broader multi-task and multi-modal evaluations.
The Leaderboard link is available at the end of this article.
Leaderboard Participation Guide: Submission Process and Fair Evaluation Mechanism
To promote community participation, the General-Level project provides a clear Leaderboard submission process and strict fairness guarantee mechanisms.
No
Whether you are an academic research team or an industrial laboratory, you can submit your developed multimodal models to the Leaderboard for evaluation by following these steps:
1. Select a Leaderboard and Download Evaluation Data
First, select the appropriate Leaderboard Scope and specific leaderboard ID based on your model’s capabilities.
Once a leaderboard is selected, download the corresponding closed-set test data from the link provided by the official source.
This dataset contains only input data; standard answers are not disclosed and are used for formal evaluation.
The official source also provides an open development set for debugging purposes. This can be used to locally test model output formats before submitting results to the leaderboard.
2. Run Local Model Inference
After obtaining the closed-set test data, perform inference on it using your local model to generate corresponding outputs.
Note that each leaderboard may contain multiple task types. The submitted result files must strictly adhere to the format and directory structure specified by the official guidelines. Please refer to the detailed submission documentation to confirm formatting requirements before submitting.
Once the output results are organized, name the file “[Model Name]-[Leaderboard ID].zip” in preparation for upload.
3. Submit Results and Fill in Information
At the submission portal on the Leaderboard website, upload the result ZIP file. You will also need to provide necessary model information (such as model name, parameter scale, description, etc.) and a contact email address so that the organizers can process the results correctly in the backend.
If you wish for your model to gain more exposure, your team may choose to publish a detailed explanation or technical report of the model after submission, facilitating community understanding of its highlights.
4. Wait for Evaluation and View the Leaderboard
After submission, the system will score the model outputs in the backend, calculating metrics for each task and aggregating them into a General-Level rank score.
Because the answers to the closed-set test data and the scoring scripts are kept confidential in the backend, submitters cannot access the answers for unpublished data, thereby ensuring the fairness of the evaluation.
Upon completion of the evaluation, the Leaderboard page updates in real time: new models appear on the corresponding leaderboards, displaying information such as model name, modality category, scores per modality, total score, rank level, and submission date. This allows both submitters and the public to immediately see a model’s rank and tier on the leaderboard.
The leaderboard supports sorting by tier or score, clearly identifying which models have reached collaborative levels such as Level-3 or Level-4.
To ensure the fairness and authority of the Leaderboard evaluation, the project has established a series of rules and restrictions:
Closed Testing: All datasets used in the leaderboards are closed sets. Models must not use this test data for training or fine-tuning. This is strictly enforced through agreements and data monitoring.
Furthermore, because the evaluation is closed, model developers cannot know the correct answers before submitting results, fundamentally guaranteeing the credibility of the scores.
Submission Frequency Limits: Each user may submit a maximum of two times within 24 hours and four times within seven days. Additionally, new submissions are not allowed while the evaluation for a previous submission is still pending.
These measures effectively prevent users from reverse-engineering standard answers or overfitting to the closed set through repeated trial-and-error speculation, maintaining the seriousness of the leaderboard.
Unified Evaluation Environment: All model submissions are scored within an evaluation environment unified by the organizers, ensuring that comparisons between different models are conducted under identical standards.
Regardless of the framework or inference acceleration used by a model, final scores are measured using the same metric system and converted into tier scores based on the General-Level algorithm, allowing for direct horizontal comparison.
Through this process and mechanism, the General-Level Leaderboard provides an open and fair arena for researchers.
Here, new model algorithms can be objectively tested and compete alongside existing industry methods; meanwhile, closed evaluation ensures result credibility, making the leaderboard a widely recognized authoritative data point.
Current Status of the Leaderboard: Model Tier Distribution and Community Feedback
To date, the leaderboard has recorded results from over 100 multimodal models, revealing their hierarchy in generalist capabilities according to General-Level standards.
In the initial batch of closed-set evaluation leaderboards released, there were significant differences in overall performance among models, even overturning common perceptions regarding the capability rankings of mainstream multimodal large language models.
Looking across the leaderboard, tier distributions are beginning to take shape.
Level-2 (No Collaboration)
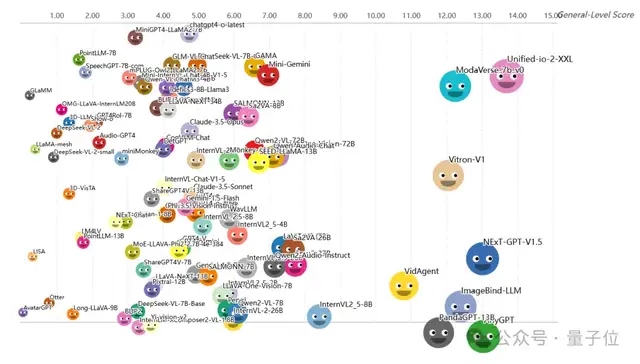
The most prevalent tier in the leaderboard is Level-2, which includes heavyweight closed-source models such as GPT-4V. Many other commonly used open-source models are also listed here.
These models excel in their wide range of supported tasks, covering almost all evaluation tasks; however, they rarely surpass single-task State-of-the-Art (SOTA) performance on any specific task. Therefore, General-Level rates them as Level-2 generalists, representing a “passing grade across all subjects” level.
Notably, although models like GPT-4V are top-tier commercial products, they did not receive standout scores because they were not specifically optimized for the evaluation tasks and thus failed to demonstrate collaborative gains.
Conversely, some open-source models have entered Level-2 through multi-task training, achieving comprehensive performance across areas, such as SEED-LLaMA and Unified-IO. Models in this tier primarily excel in image modalities, with average single-modality scores generally ranging between 10 and 20 points, indicating significant room for improvement.
The current top three models at Level-2 are Unified-io-2-XXL, AnyGPT, and NExT-GPT-V1.5.
Level-3 (Task Collaboration)
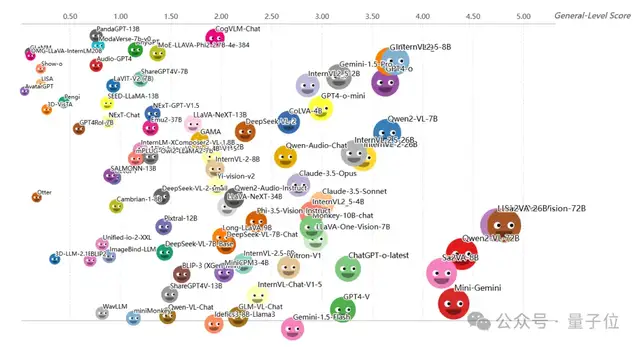
The number of multimodal large models gathered at this level is significantly lower than at Level-2. These models have defeated specialized models in several tasks, demonstrating performance leaps brought about by collaborative learning.
Many new models released after 2024 have advanced to this tier, including open-source models such as Sa2VA-26B, LLaVA-One-Vision-72B, and the Qwen2-VL-72B series. These models typically possess hundreds of billions of parameters and undergo massive multimodal, multi-task training, allowing them to surpass traditional single-task SOTA results on certain benchmarks.
This proves the value of collaborative effects: unified multi-task training enables models to learn more general representations, mutually enhancing performance across related tasks.
Conversely, some closed-source large models, such as OpenAI’s GPT-4o, GPT-4V, and Anthropic’s Claude 3.5, do not rank highly at Level-3.
The overall average score range for Level-3 models is lower than that of Level-2, indicating a more difficult scoring environment at this level.
Level-4 (Paradigm Collaboration)
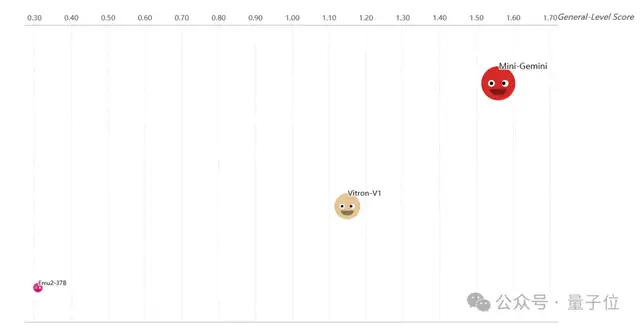
Models reaching this tier remain rare.
According to the Leaderboard (as of the evaluation date, December 2024), only a very small number of models are rated as Level-4, such as large-scale prototype open-source models like Mini-Gemini, Vitron-V1, and Emu2-37B.
These models have made breakthroughs in cross-paradigm reasoning, possessing excellent understanding and generation capabilities while integrating the two seamlessly.
For example, the Mini-Gemini model leads in both image understanding and generation, ranking prominently on the Leaderboard’s paradigm collaboration scores.
The emergence of Level-4 signifies progress toward true cross-modal reasoning AI. However, the average score for current Level-4 models is very low. This reveals the immense challenge of building AI with comprehensive paradigm synergy: achieving dual breakthroughs in both multimodal understanding and generation while maintaining balance is extremely difficult.
Level-5 (Full Modality Total Collaboration)
This tier remains empty to date, with no model having achieved it.
This is not surprising, as surpassing experts across all modalities and tasks while simultaneously enhancing language intelligence currently exceeds the capabilities of existing technology.
The General-Level team speculates that the next milestone may come from a “multimodal version” of GPT-5, which could potentially demonstrate the first signs of full-modal collaboration, thereby changing the situation where Level-5 remains unclaimed.
However, until that day arrives, the Level-5 position on the Leaderboard will remain vacant, reminding us that we are still quite far from achieving true AGI.
The launch of the current Leaderboard has sparked enthusiastic responses within the AI research community. Many researchers believe that such a unified, multi-dimensional evaluation platform is urgently needed in the multimodal field: it is not only unprecedented in scale (covering 700+ tasks) and comprehensive in structure (with tiers and sub-categories), but also open and transparent, providing the industry with a common reference for progress.
On social media and forums, discussions have arisen regarding the leaderboard results: some are surprised that open-source models like Qwen2.5-VL-72B can defeat many closed-source giants, proving the potential of the open-source community; others analyze GPT-4V’s shortcomings in complex audio-visual tasks to explore how to address them.
Leaderboard data is also being used to guide research directions: it is clear which tasks are weak points for most models and which modality combinations have not yet been well resolved.
It can be anticipated that as more models join the leaderboard, it will continue to update. This is not merely a competition but an ongoing accumulation of valuable scientific insights.
The launch of the General-Level evaluation framework and its Leaderboard marks a new stage in multimodal generalist AI research. As hoped by the authors in their paper, the assessment system constructed by this project will serve as fundamental infrastructure, helping the industry measure the progress of general artificial intelligence more scientifically.
Through unified standard tier evaluations, researchers can objectively compare the strengths and weaknesses of different models to identify directions for further improvement; through large-scale multi-task benchmarks, they can comprehensively examine a model’s shortcomings in various domains, accelerating problem discovery and iterative improvement. All of this is of significant importance for driving the next generation of multimodal foundation models and advancing toward true AGI.
More importantly, the General-Level project adheres to an attitude of open sharing, welcoming broad community participation in co-construction. Whether you have new model proposals or unique datasets at hand, you can participate: submit your model results to join the leaderboard and compete with top global models; or contribute new evaluation data to enrich the task diversity of General-Bench.
Every dataset added will receive acknowledgment on the official website homepage and be cited in technical reports.
Project Homepage: https://generalist.top/
Leaderboard: https://generalist.top/leaderboard
Paper Address: https://arxiv.org/abs/2505.04620
Benchmark: https://huggingface.co/General-Level