224 GPUs Used to Train a New Open-Source Video Generation SOTA!
Open-Sora 2.0 Officially Released.
With an 11B parameter scale, its performance rivals HunyuanVideo and Step-Video (30B).
It is worth noting that many proprietary video generation models with similar effects incur training costs of millions of dollars.
In contrast, Open-Sora 2.0 has compressed this figure to just $200,000.
Furthermore, this release includes the full open-source model weights, inference code, and distributed training pipeline, making it a valuable resource for developers!
GitHub Repository: https://github.com/hpcaitech/Open-Sora
Supports High-Quality Generation at 720P and 24FPS
Let’s look at the Open-Sora 2.0 demo.
Regarding motion amplitude, parameters can be adjusted to better showcase nuanced movements of characters or scenes.
In the generated videos, a man performing push-ups moves smoothly with reasonable amplitude, indistinguishable from real-world physics.

Even in virtual scenarios like a tomato surfing, the splashes of water, the leaf boat, and the tomato adhere to physical laws.

In terms of image quality and fluidity, it offers 720P high resolution and 24FPS smoothness, ensuring stable frame rates and detailed performance in the final video.

It also supports rich scene transitions. From rural landscapes to natural scenery, Open-Sora 2.0 delivers excellent performance in both image details and camera movements.

11B Parameter Scale Rivals Mainstream Proprietary Large Models
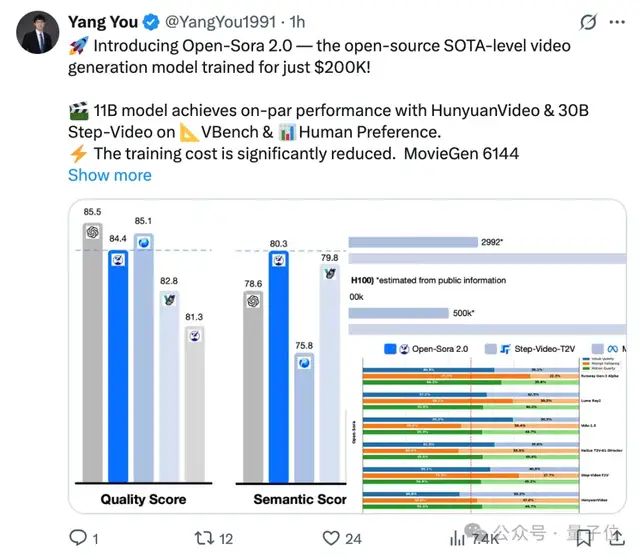
Open-Sora 2.0 adopts an 11B parameter scale. After training, it achieves performance levels comparable to mainstream proprietary large models developed at high costs in both VBench and Human Preference evaluations, rivaling HunyuanVideo and the 30B Step-Video.

Across three evaluation dimensions—visual appearance, text consistency, and motion performance—Open-Sora surpasses the open-source SOTA HunyuanVideo in at least two metrics, as well as commercial models like Runway Gen-3 Alpha. It achieves high performance with low cost.
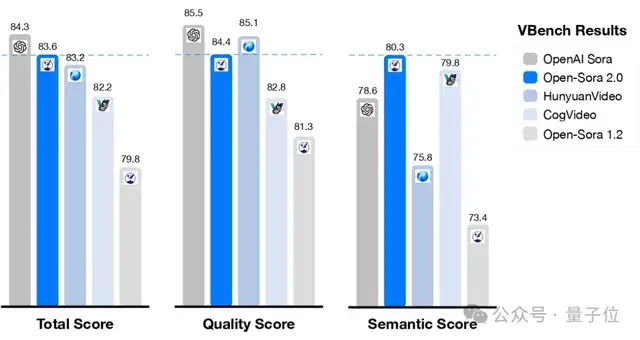
According to evaluation results from the authoritative video generation benchmark VBench, Open-Sora has shown significant performance improvements. Upgrading from Open-Sora 1.2 to version 2.0 significantly narrowed the performance gap with industry-leading proprietary models like OpenAI Sora, reducing it from 4.52% to just 0.69%, nearly achieving parity in performance.
Additionally, Open-Sora 2.0’s score on VBench exceeds that of Tencent’s HunyuanVideo, delivering higher performance at a lower cost and setting a new benchmark for open-source video generation technology.
Achieving Breakthroughs: Low-Cost Training and High-Efficiency Optimization
Since its release as an open-source project, Open-Sora has attracted significant attention and participation from developers due to its efficiency and high-quality output in the field of video generation.
However, as the project progressed, it faced challenges related to the persistently high costs of generating high-quality videos. To address these issues, the Open-Sora team conducted a series of effective technical explorations that significantly reduced model training costs. Estimates suggest that while open-source video models with over 10B parameters typically require single-training costs in the millions of dollars, Open-Sora 2.0 has reduced this cost by 5 to 10 times.
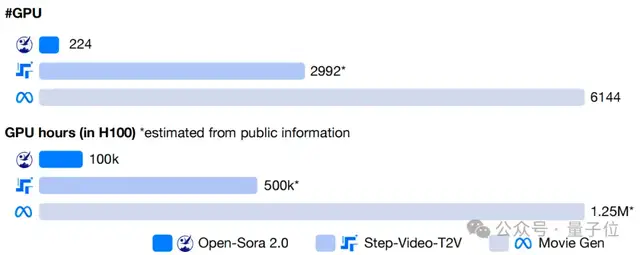
As a leader in the open-source video generation field, Open-Sora not only continues to release model code and weights but also opens up the full training pipeline code, successfully building a robust open-source ecosystem. According to third-party technical platforms, Open-Sora’s academic papers received nearly 100 citations within six months, firmly ranking first in global open-source influence among all open-source I2V/T2V video generation projects, making it one of the most influential open-source video generation projects worldwide.
Model Architecture
Open-Sora 2.0 continues the design philosophy of Open-Sora 1.2, employing a 3D Autoencoder and a Flow Matching training framework. It utilizes a multi-bucket training mechanism to simultaneously train videos of different lengths and resolutions. In terms of model architecture, it introduces a 3D Full Attention Mechanism to further enhance video generation quality.
Additionally, it adopts the latest MMDiT architecture to more accurately capture the relationship between text information and video content, expanding the model scale from 1B to 11B. Furthermore, by leveraging initialization from the open-source image-to-video model FLUX, it significantly reduces training costs and achieves more efficient video generation optimization.
Fully Open-Source Efficient Training Methods and Parallel Solutions
To pursue extreme cost optimization, Open-Sora 2.0 focuses on reducing training overhead in four key areas.
First, through strict data filtering, it ensures high-quality data input, improving model training efficiency from the source. By employing a multi-stage, multi-level filtering mechanism combined with various filters, it effectively enhances video quality and provides more precise and reliable training data for the model.

Secondly, the cost of high-resolution training is far higher than that of low-resolution training. When achieving the same data volume, computational overhead can be up to 40 times greater. For example, a video with dimensions of 256px and 5 seconds contains approximately 8 thousand tokens, whereas a 768px video contains nearly 80 thousand tokens—a difference of 10 times. Coupled with the quadratic computational complexity of attention mechanisms, high-resolution training is extremely expensive. Therefore, Open-Sora prioritizes allocating computing power to low-resolution training to efficiently learn motion information, ensuring the model captures key dynamic features while reducing costs.
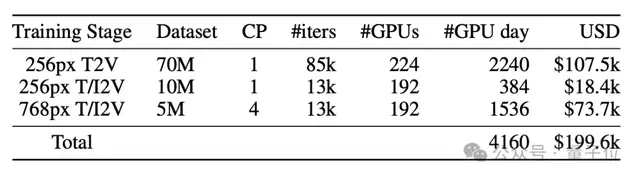
Meanwhile, Open-Sora prioritizes training image-to-video tasks to accelerate model convergence. Compared to directly training high-resolution videos, image-to-video models exhibit faster convergence when increasing resolution, further reducing training costs. During inference, in addition to direct text-to-video (T2V), users can combine open-source image models to generate images first and then video (T2I2V) for more refined visual effects.
Finally, Open-Sora employs an efficient parallel training scheme, integrating ColossalAI and system-level optimizations to significantly improve computing resource utilization and achieve more efficient video generation training. To maximize training efficiency, we introduced a series of key technologies, including:
- Efficient Sequence Parallelism and ZeroDP, optimizing distributed computing efficiency for large-scale models.
- Fine-grained Gradient Checkpointing control, maintaining computational efficiency while reducing VRAM usage.
- Automatic training recovery mechanism, ensuring over 99% effective training time and minimizing wasted computing resources.
- Efficient data loading and memory management, optimizing I/O to prevent training bottlenecks and accelerate the process.
- Efficient asynchronous model saving, reducing interference from model storage on the training flow and improving GPU utilization.
- Operator optimization, deeply optimizing key computational modules to speed up the training process.
These optimizations work synergistically, allowing Open-Sora 2.0 to achieve the best balance between high performance and low cost, significantly lowering the barrier for training high-quality video generation models.
High Compression Ratio AE Brings Higher Speed
After training completion, Open-Sora looks toward the future by further exploring the application of a high-compression-ratio video autoencoder to drastically reduce inference costs. Currently, most video models still use autoencoders with a 4×8×8 compression ratio, resulting in single-GPU generation times for 768px, 5-second videos nearing 30 minutes.
To address this bottleneck, Open-Sora trained a high-compression-ratio (4×32×32) video autoencoder, reducing inference time to under 3 minutes per GPU, thereby increasing inference speed by 10 times.
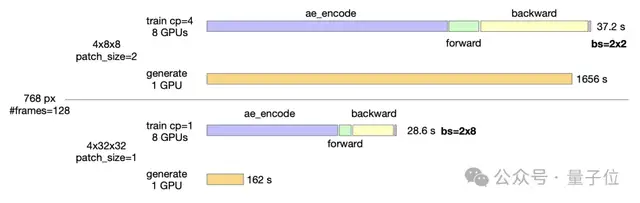
Achieving a high-compression-ratio encoder requires solving two core challenges: how to train an autoencoder that is highly compressed yet maintains excellent reconstruction quality, and how to utilize this encoder for training video generation models. For the former, the Open-Sora team introduced residual connections in the video up/downsampling modules, successfully training a VAE with reconstruction quality comparable to current open-source SOTA video compression models but with a higher compression ratio, laying the foundation for efficient inference.

High-compression autoencoders face higher data requirements and convergence difficulties when training video generation models, typically requiring more training data to achieve ideal results. To solve this, Open-Sora proposed a distillation-based optimization strategy to enhance the expressive power of the AE feature space, utilizing already trained high-quality models for initialization to reduce the amount of data and time needed for training. Additionally, Open-Sora focused on training image-to-video tasks, using image features to guide video generation, further accelerating the convergence speed of the high-compression autoencoder, allowing it
Achieved results.
Open-Sora believes that high-compression video autoencoders will become a key direction for reducing the cost of video generation in the future. Preliminary experimental results have already demonstrated significant inference acceleration, with the hope of further stimulating community interest and exploration in this technology, jointly promoting the development of efficient and low-cost video generation.
Join Open-Sora 2.0 to Drive the AI Video Revolution Together
Today, Open-Sora 2.0 is officially open-sourced!
GitHub Repository: https://github.com/hpcaitech/Open-Sora
Technical Report: https://github.com/hpcaitech/Open-Sora-Demo/blob/main/paper/Open\_Sora\_2\_tech\_report.pdf
Welcome to join the Open-Sora community and explore the future of AI video!