They call it top-tier “courtesy.”
Waking up, both OpenAI and the parent company of Claude have taken action against DeepSeek.
According to The Financial Times, OpenAI stated that it has found evidence proving DeepSeek used their models for training, which is suspected of infringing on intellectual property rights.
Specifically, they discovered signs of DeepSeek “distilling” OpenAI’s models. This involves using the outputs of larger models to enhance the performance of smaller ones, thereby achieving similar results in specific tasks at a lower cost.
Microsoft has also begun investigating whether DeepSeek used OpenAI’s API.

Upon the news breaking, a wave of mockery ensued.
New York University professor Marcus was among the first to criticize:
OpenAI: We need free access to all artists’ and writers’ works to train our models so we can save money to sue DeepSeek for blatantly stealing from us!

Jason, founder and editor-in-chief of the well-known tech media outlet 404 Media, directly called out OpenAI in an article, implying that they are guilty of hypocrisy.

Meanwhile, Dario Amodei, founder of Claude’s parent company Anthropic, wrote a lengthy post discussing DeepSeek.
He stated that claiming DeepSeek poses a threat is an exaggeration; it is merely “at the level we were 7–10 months ago.” He noted that Claude 3.5 Sonnet still remains far ahead in many internal and external evaluations.
However, to maintain our lead, I suggest we might need to impose more constraints on ourselves?
Good heavens. To contain DeepSeek, competitors OpenAI and Anthropic have rarely joined forces.
In contrast, Microsoft’s approach has been more intriguing.
Just hours after accusing DeepSeek of infringement, Microsoft integrated the DeepSeek model into its AI platform.
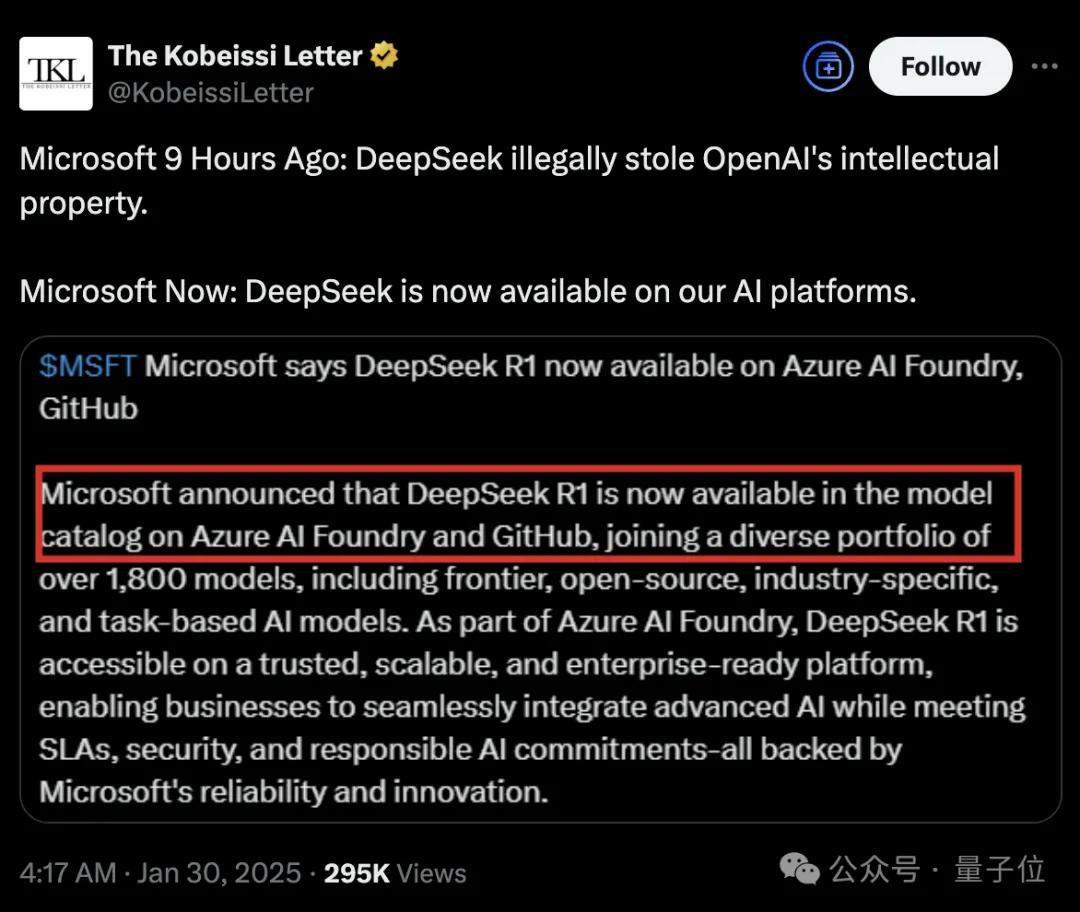
Netizens commented: As the saying goes, denial is the first step to acceptance.

Common AI Technology, but Violates OpenAI’s Terms
Synthesizing various reports, Microsoft and OpenAI’s suspicions regarding DeepSeek are still under investigation.
According to Microsoft staff, DeepSeek may have called upon OpenAI’s API last autumn, potentially leading to data leakage.
Under OpenAI’s terms of service, anyone can register to use the API, but they cannot use output data to train models that pose a competitive threat to OpenAI.
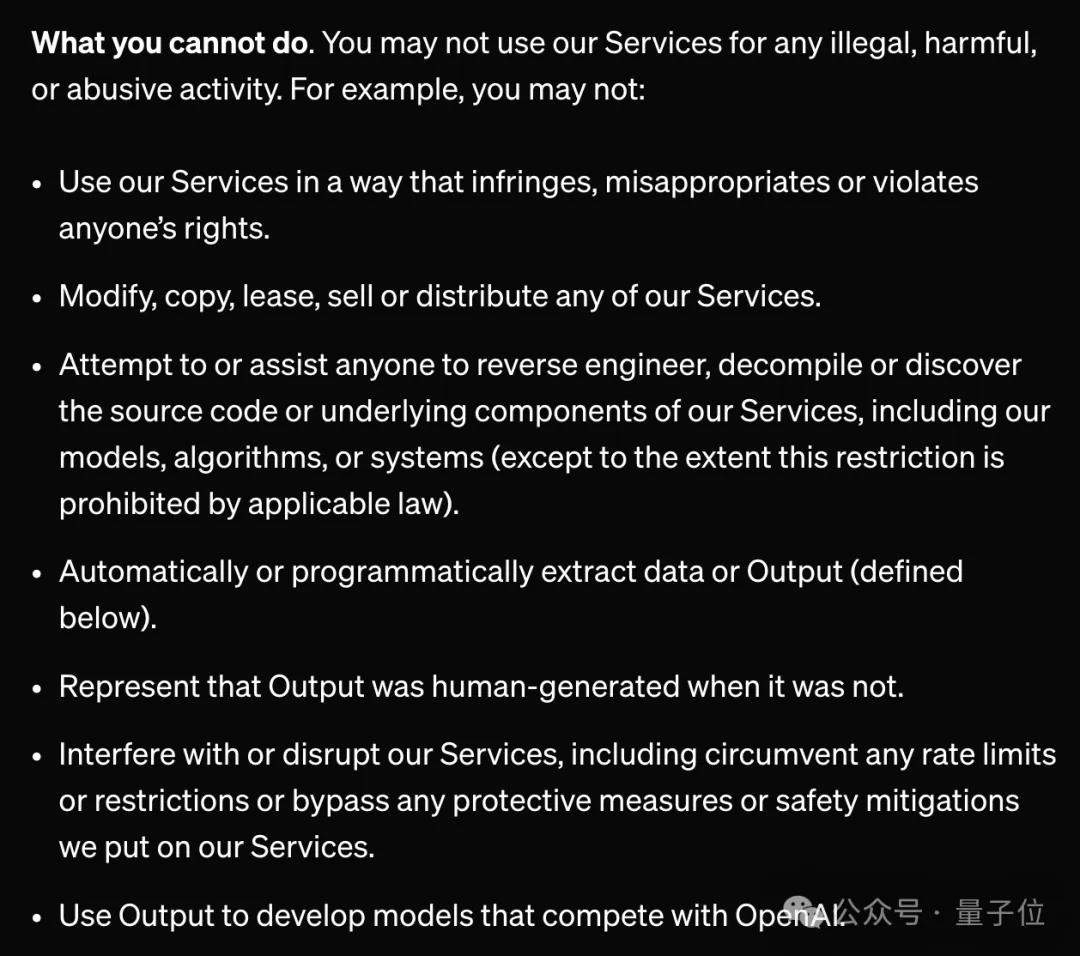
OpenAI told The Financial Times that they found evidence of model distillation, suspecting DeepSeek was responsible.
Currently, OpenAI has refused to comment further and declined to provide details on the evidence.
So, let’s first look at what model distillation is, which has sparked controversy.
It is a model compression technique that “distills” the knowledge of a complex, computationally expensive large model (the teacher model) into a smaller, more efficient model (the student model). The core goal of this process is to allow the student model to retain as much performance as possible from the teacher model while being lightweight.
In the paper Distilling the Knowledge in a Neural Network by Turing Award winner and “Father of Deep Learning” Geoffrey Hinton, it was pointed out:
Distillation is very effective for transferring knowledge from ensembles or large highly regularized models to smaller distilled models.

For example, Together AI recently worked on distilling Llama 3 into Mamba, achieving up to a 1.6x increase in inference speed while maintaining stronger performance.

An article on knowledge distillation from IBM also noted that in most cases, the most advanced LLMs place too high demands on computation and cost… Knowledge distillation has become an important method to transplant the advanced capabilities of large models into smaller (usually) open-source models. Therefore, it has become a key tool for democratizing generative AI.

In the industry, terms of service for some open-source models allow distillation. For instance, Llama allows it, and DeepSeek previously stated in a paper that they used Llama.
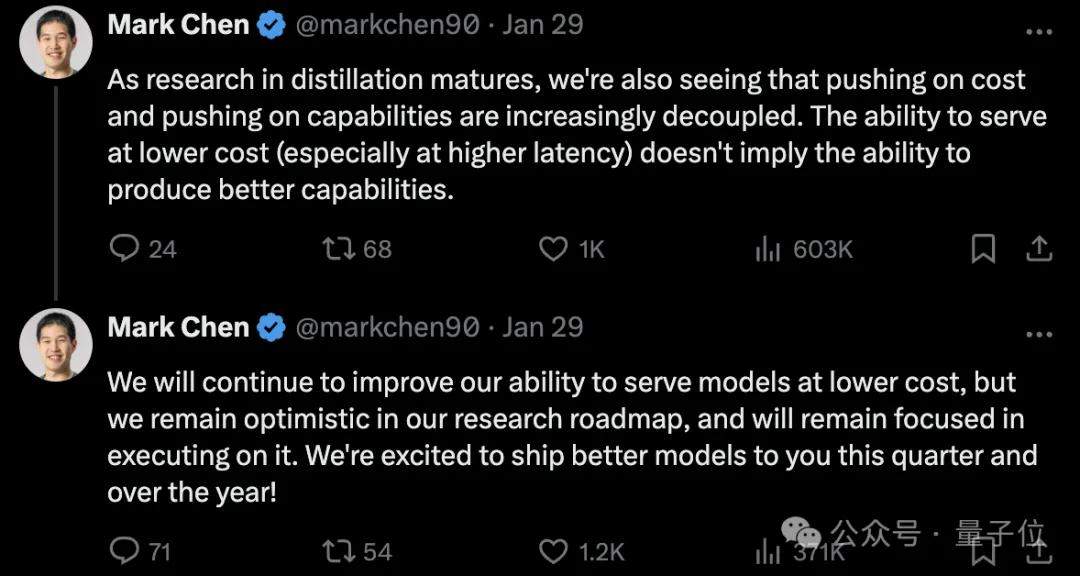
Moreover, crucially, DeepSeek R1 is not merely a simple distilled model. Mark Chen, Chief Scientist at OpenAI, stated:
DeepSeek independently discovered some core concepts adopted by OpenAI during the implementation of o1.
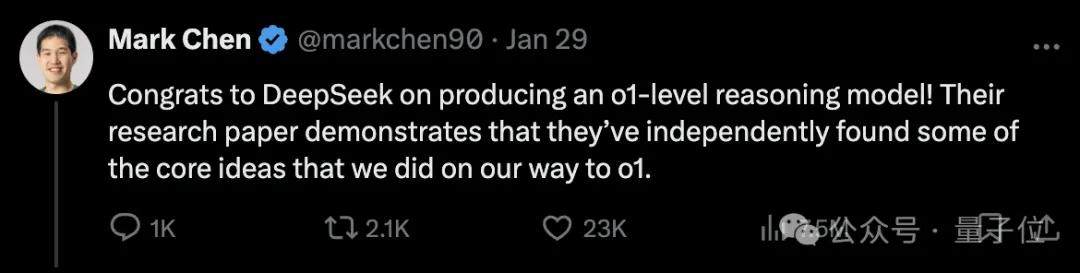
He also acknowledged DeepSeek’s work in cost control and mentioned the trend of distillation technology, noting that OpenAI is also actively exploring model compression and optimization technologies to reduce costs.
So, to summarize: Model distillation technology is very common and recognized in both academia and industry, but it violates OpenAI’s terms of service.
Is this reasonable? Who knows.
But the issue is that OpenAI itself has significant compliance issues.
(It is well known that when training its models, OpenAI scraped data from the entire internet, which includes not only freely available knowledge content but also a large amount of copyrighted articles and works.)
In December 2023, The New York Times sued Microsoft and OpenAI together for intellectual property infringement. This lawsuit has not yet reached a final verdict; throughout this past year, OpenAI has provided multiple explanations to the court regarding its actions.

Including but not limited to:
- Using publicly available internet materials to train AI models is reasonable, with many precedents in the AI field; we believe this is fair to creators and necessary for innovation.
- For a long time, non-commercial use of copyrighted works (such as training large models) has been protected under fair use doctrines.
- The key to Large Language Models is Scaling, meaning that any individually stolen content is insufficient to support the training of an LLM; this is precisely why OpenAI’s models are leading.
In other words, OpenAI itself is using The New York Times’ data in violation of regulations to train closed-source, commercial large models. Now they intend to investigate DeepSeek, which builds a series of open-source models, on the grounds of violation.
Taking one step further, OpenAI’s current achievements are also built upon Google’s foundation (the Transformer architecture was proposed by Google), and Google’s success stands on even earlier academic research.
404 Media stated that this is actually the basic logic of development in the AI field.

“DeepSeek Models Lead Only in Cost”
Just as OpenAI stirred up conflict, Anthropic also entered the fray.
Founder Dario Amodei expressed his views on DeepSeek in a personal blog post.
He stated that he does not view DeepSeek as a competitor, believing that DS’s latest model is at a level comparable to theirs from 7–10 months ago, with significantly reduced costs.
The training for (Claude 3.5) Sonnet took place 9–12 months ago, while the DeepSeek models were trained in November/December, and Sonnet still performs significantly better in many internal and external evaluations.
Therefore, I believe the correct statement is that “DeepSeek generated a model that achieved performance close to Claude from 7 to 10 months ago at a lower cost (though not as low as advertised).”
He also believed that DeepSeek’s overall company investment costs (not just single-model training costs) are similar to those of Anthropic’s AI lab.
Sam Altman maintained almost the same narrative.
He admitted that DeepSeek R1 is impressive (especially regarding cost), but OpenAI “will clearly bring better models.”
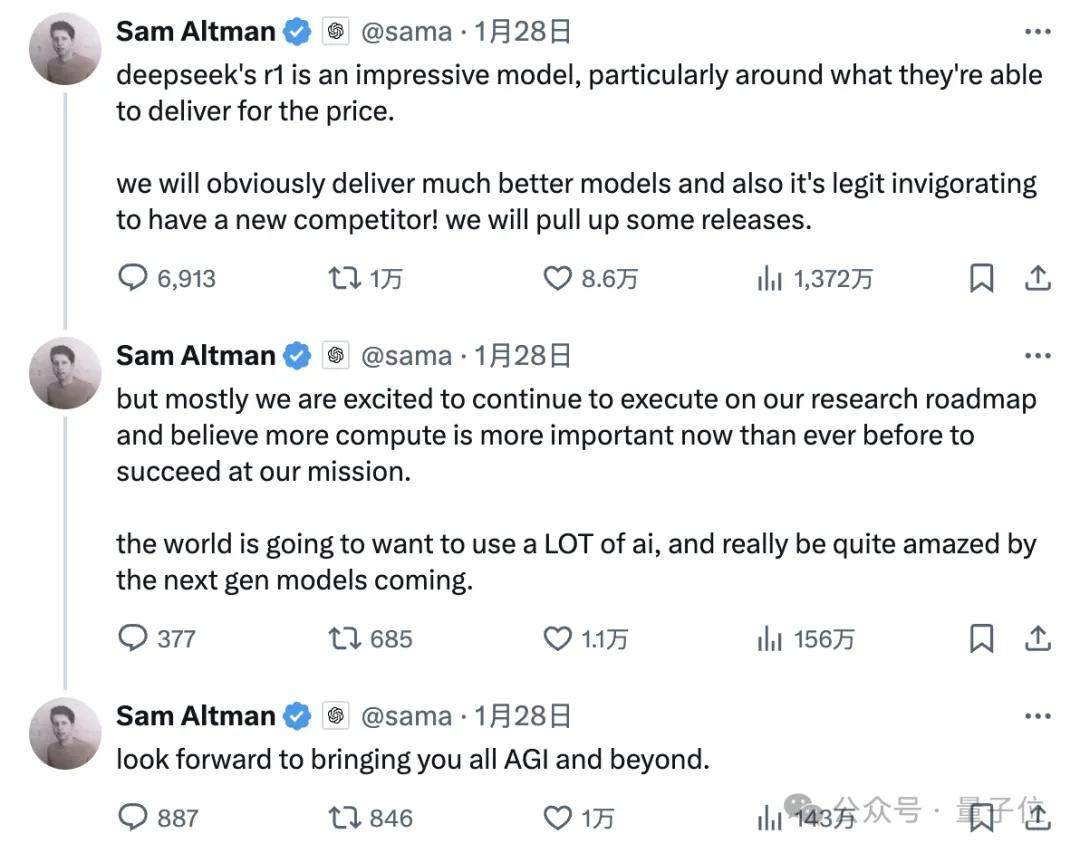
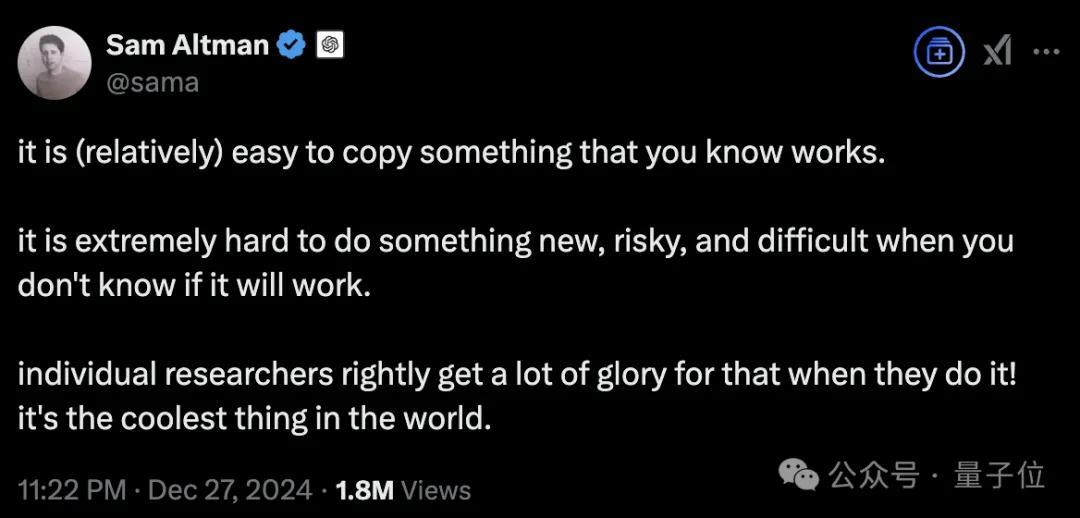
This has become his standard operating procedure. When V3 was released previously, he sarcastically remarked: Relatively speaking, replicating what is proven to be useful is easy.
So, what exactly is the value of DeepSeek R1?
Analyst Ming-Chi Kuo provided a reference in his latest blog:
The emergence of DeepSeek R1 makes two trends even more noteworthy—although these trends existed without R1, it has accelerated their occurrence.
One is that AI computing power can continue to grow through optimized training methods despite the slowing of Scaling Laws, which benefits the exploration of new applications.
In the past 1–2 years, investors in the AI server supply chain have…
The investment thesis is primarily based on the sustainable growth of AI server shipments, assuming that Scaling Laws remain effective.
However, as the marginal returns of Scaling Laws begin to gradually diminish, the market has started focusing on pathways that significantly enhance model efficiency through methods other than Scaling Laws, exemplified by DeepSeek.
The second trend is a significant decline in API and token prices, which facilitates the diversification of AI applications.
Guo Mingchi believes that currently, the primary way to profit from the generative AI trend remains “selling shovels” (providing infrastructure) and reducing costs, rather than creating new business lines or increasing the added value of existing businesses.
DeepSeek-R1’s pricing strategy will drive down the overall usage cost of generative AI. This helps increase demand for AI computing power and alleviates investors’ concerns regarding the profitability of AI investments.
Nevertheless, it remains to be seen whether the increase in usage volume can offset the impact of lower prices.
Meanwhile, Guo Mingchi noted that only large-scale deployers are encountering the slowdown in marginal returns from Scaling Laws. Therefore, when marginal efficiency accelerates again, Nvidia will remain the winner.
References
- 1884601187271581941 — x.com/GaryMarcus/status/1884601187271581941