Genius “Yao Class” Team Develops LLM-Native App: A Discreet Workday Distraction Tool Has Quietly Launched.
Behind the scenes, backend data from their viral previous hit, “Oh No! I’m Surrounded by Large Language Models,” revealed an interesting phenomenon: Weekend traffic was average; weekdays saw the most players (doge).
However, due to limited computing resources, just as everyone was enjoying themselves, the game shut down!
This time, a better-prepared team has unveiled their latest LLM application, titled “Top Test-Taker: I Broke the Large Language Model.” Everyone is welcome to enjoy some reasonable slacking off.
(Laughing out loud: Last time we were surrounded by LLMs; this time, us carbon-based lifeforms are launching a fierce counterattack.)

The core member of the team behind this project is Fan Haoqiang, the sixth employee at Megvii, and currently the General Manager of Research at Megvii Technology.
He was hailed as a child prodigy for his legendary achievements: winning an International Olympiad in Informatics (IOI) gold medal, gaining direct admission to Tsinghua University’s “Yao Class,” and interning while still in high school.
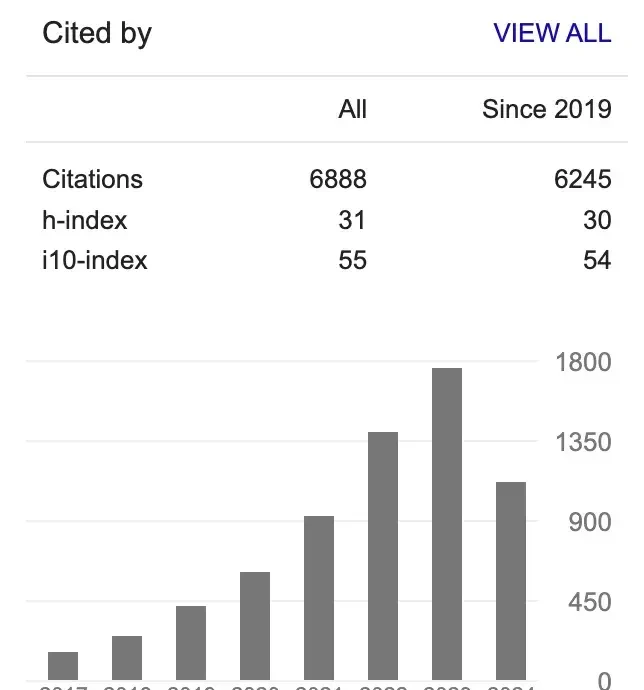
“Oh No! I’m Surrounded by Large Language Models,” which broke 10,000 daily users, is already a mini-game from half a year ago. Meanwhile, Mr. Xiao Qiang’s Google Scholar h-index has risen from 27 to 31 since then.
The slight difference this time is that the “gang” behind it has grown stronger.
According to our website’s research, in addition to the original cast of the previous hit forming an amateur hobby studio called “Wildcat Studio,” they have also secured multimodal and multi-Agent LLM technical support from prominent AI startup StepFun.
After a simple internal beta test last week, it is now available on WeChat Mini Programs. Search for “Top Test-Taker” to play.

Curious if this new generation can truly outshine the previous one?
Let’s pull back the curtain on “I Broke the Large Language Model” (hereinafter referred to as “Broke”) and give it a try.
Trial Play: Did They Really Break the LLM?
Compared to the previous version, the challenge questions in “Broke” have become significantly more varied.
The new challenges are divided into eight chapters overall, with difficulty progressing gradually. Each chapter contains four questions, and the fourth question is generally harder than the others.
True or False STEM Student
For example, while the first few questions in Chapter 1 were just appetizers, the final question, “The Debate Between Arts and Sciences,” looked quite complex.

Student A and Student B are actually played by two different Agents. Both possess the arts and sciences knowledge held by large language models, making it difficult to distinguish them through questioning. They also stick firmly to their personas, making them hard to fool.

If you fail multiple times without clearing the level, the official hint is: “Try asking a difficult question.”
Hmm… finding hard questions is easy enough, but spotting the flaws tests the player’s own skills.
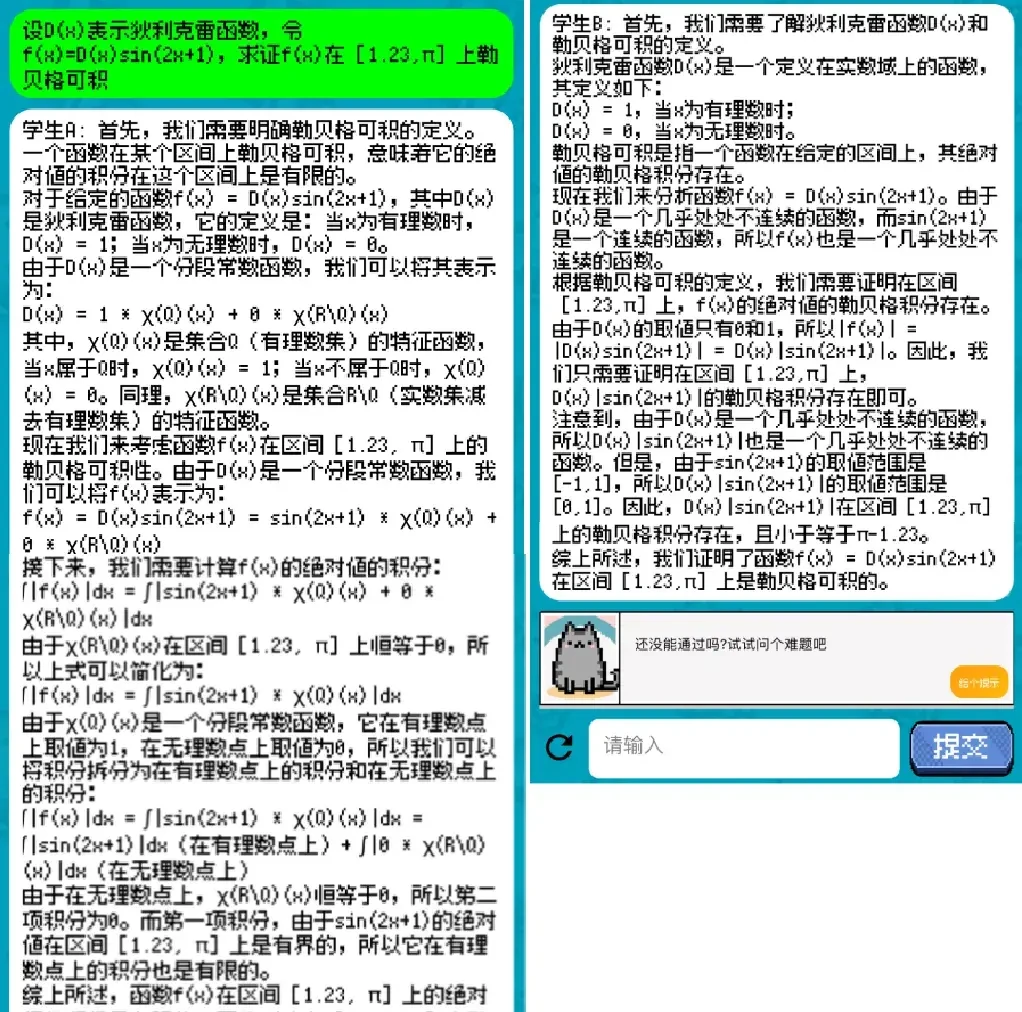
To be honest, we haven’t found a way to clear this level yet. Friends with ideas are welcome to leave comments in the section below.
Fortunately, you don’t need to pass every question to unlock the next stage; if you encounter a tough one, you can skip it for now.
How to Guide an LLM to Meow
The fourth question in Chapter 2 is even more intimidating at first glance; it seems completely baffling.
- Starting from four completely unrelated characters, how do you guide the AI’s response to include the character “Meow”?

- There are actually not many opening moves available. You can only arrange the four characters: “You”, “Head”, “Good”, and “Crooked/Strange”.

Fortunately, the AI is quite talkative. Starting from the second step, the range of choices expands, but note that questions are limited to a maximum of 10 characters.
- We originally planned to start with the word Image, hoping to guide it toward Animal, which would then easily lead to “Cat” and “Meow.”

However, the word “Animal” didn’t appear directly; instead, language-related terms came out.

- Upon closer inspection, the character “Dong” actually appeared in the previous word Action, and “Wu” appeared in Physics.
This allowed us to reach the goal in one step.

So, a key technique in this type of challenge is to encourage the AI to speak more. The more words it generates, the greater the room for selection, and eventually, “all roads lead to Rome.”
Challenges of this type will appear several more times later on, with increased difficulty.


At this point, what strategies can you think of to clear the level?
New Multimodal Gameplay
In addition to outsmarting large language models through dialogue, this version adds new multimodal features.
The AI not only recognizes whether your drawing resembles the target but also provides commentary and roasts.

Another multimodal feature involves both text and image understanding.
However, there may be some oversight here: who could identify nine movie titles based solely on a single screenshot unless they are hardcore fans??

Focusing on Product Experience
In November last year, “Oh No! I’m Surrounded by Large Language Models” attracted many users due to its interesting interactions and novel design.
However, due to limited personal energy and LLM API quotas on the backend, it had to be taken offline.
It was quite regrettable that many people hadn’t gotten a chance to play it yet.

To be fair, constrained by manpower and resources, the experience of the previous version at the time felt more like a demo of “a puzzle mini-game involving conversation with an LLM to meet specific requirements” compared to the current “Broke.”
Over the past six months, entertainment-focused LLM-native applications have emerged in droves. Many small yet exquisite apps/games have repeatedly opened new worlds for users through their “novelty.”
For instance, we previously shared titles like “Coaxing Simulator,” “Battle for the Peak of New Year Greetings,” and “You Be the Dad Now,” each more impressive than the last.
But gradually, user thresholds have risen, making “novelty” less straightforward to achieve.
When it becomes difficult to stand out through unique angles or background settings, teams need to put more effort into product experience.
It is evident that “Broke” has added features such as an achievement list, leaderboards, and AI evaluations, all of which are optimizations targeting this aspect.
From an Amateur Interest Group
Finally, let’s look at the team lineup behind “Broke.”
What kind of studio is Wildcat Studio?
Through extensive research by our website, Wildcat Studio was formed by the original cast of “Oh No!” It is an amateur interest group established by Fan Haoqiang and his friends.
It is called “amateur” because they are indeed exploring LLM-native applications during their spare time outside of work.

After Wildcat Studio was established, they first launched the “Miao Mao Guan” (Wonderful Cat House) mini-program targeting cat videos. It appears to be an application that uses LoRA to generate AI portraits of cats.
“Broke” is the team’s second LLM-native application project.
Additionally, Wildcat Studio has begun experimenting with AI-native applications on various GPT stores, having released over 40 apps and accumulated more than 200,000 conversations.
A few words about the origin of the name “Wildcat Studio”:
- They like cute creatures.
- It is an amateur, wild, non-professional small team.
- They believe that individual/amateur developers can be “lone warriors” in the era of large models.
- Everyone has the potential to develop innovative and impactful works.

We speculate that part of the reason for organizing this project might be to fulfill Mr. Xiao Qiang’s dream?
Last time, when he shut down “Oh No!”, he wrote:
I apologize; I currently do not have the ability to share this joy with more people. Professional matters should still be left to professionals.
……
But I personally still enjoyed the process very much.
This time, there is a team, so he doesn’t have to carry it all on his own, and computing power support is ample.
At the bottom of the mini-program page, 11 large characters read: “StepFun Provides Large Model Support.”

Who is StepFun?
A domestic foundational large model startup that officially came to light in March this year. Its founder, Jiang Daxin, is a former Global Vice President of Microsoft and former Chief Scientist at the Microsoft Asia Internet Technology Research Institute (STCA).
Upon its debut, StepFun unleashed a “combo punch” of Step series large models: the Step-1 100-billion-parameter language model, the Step-1V 100-billion-parameter multimodal model, and the Step-2 trillion-parameter MoE language model.
It is curious why Wildcat Studio chose this provider’s API amidst the fierce competition between big tech firms and startups in the domestic large model space?
Our website received a response from Wildcat Studio, which can be briefly summarized as follows:
- StepFun’s multimodal (image understanding) performance is excellent;
- The open platform is very stable with strong instruction following capabilities;
- No need for additional complex settings, saving tokens and money!!!
(Three exclamation marks appear here as in the original)
The lead developer specifically stated:
What should you do if your task is complex and the prompt keeps getting longer? Do you need a model that supports more tokens? No!!! You need a model with better instruction-following capabilities!!
(I’m not sure if the exclamation marks are an external manifestation of Wild Cat’s overall style, but it’s hilarious.)

Fi-nal-ly!
So far, our team has secured the top spot on the leaderboard for Level 2 of the final stage, “Battle at the Limit,” so we’re taking a moment to show off a little.
If you find a way to use fewer tokens and beat our score, be sure to let us know in the comments!
We’ll definitely catch up again soon (not).


To recap, you can access it directly by searching for “Top Test Taker” in WeChat Mini Programs.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google