Just now, CVPR 2026 awarded all of this year’s major prizes in Denver.
Here is a quick summary of the key highlights:
- Best Paper Award: D4RT, a feedforward model that can rapidly and accurately reconstruct dynamic 4D scenes from a single video clip, developed by Google DeepMind (in collaboration with UCL and Oxford University). This marks the second consecutive year that the CVPR Best Paper award has gone to research on geometric reconstruction (last year’s winner was VGGT).
- Honorable Mention for Best Paper (2 papers): Meta’s single-image 3D reconstruction foundation model, SAM 3D, and NVIDIA’s general-purpose game intelligence agent large model, NitroGen.
- Best Student Paper Award: TRELLIS.2, a 4-billion-parameter 3D generation model developed entirely by a team of Chinese researchers from Tsinghua University and Microsoft.
- Honorable Mention for Best Student Paper: ChordEdit, a team composed exclusively of students from domestic Chinese universities, including Guangdong University of Technology (GDUT), Shenzhen University, and Peking University. The first author is an undergraduate student.
- Longuet-Higgins Prize (Time-Tested Award): Jointly awarded to the two “pioneers” of 2016—ResNet and YOLO.
- PAMI Distinguished Contributor Awards: The Young Scholar Award went to Deepak Pathak from CMU and Vincent Sitzmann from MIT; the Thomas S. Huang Memorial Award was presented to Noah Snavely from Cornell University.
Competition for this year’s paper awards was fierce: 74 papers were shortlisted, 15 advanced to the final round, and ultimately five received awards.
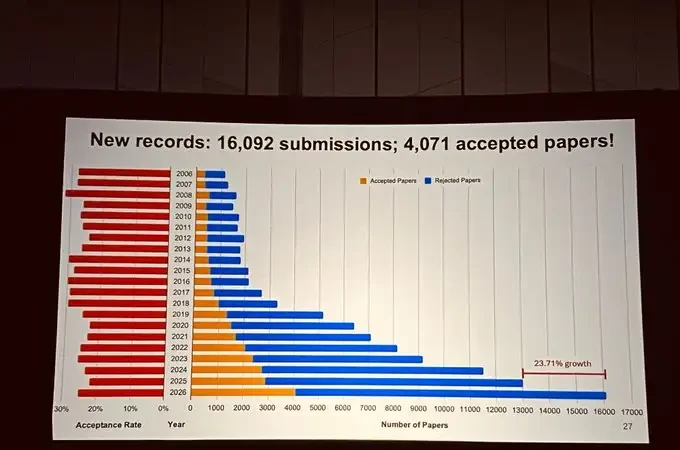
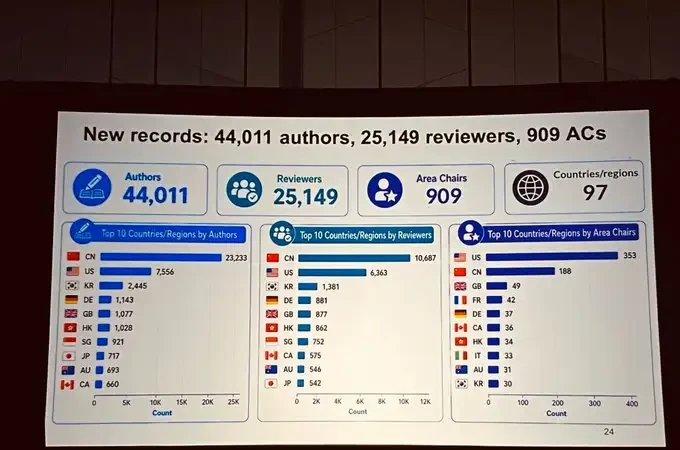
The scale of CVPR 2026 also set new records: the conference received 16,092 submissions and accepted 4,071 papers, marking a record-high paper count with a 23.71% increase over last year.
△ Image from the official CVPR 2026 X account.

△ Image from the official CVPR 2026 X account.
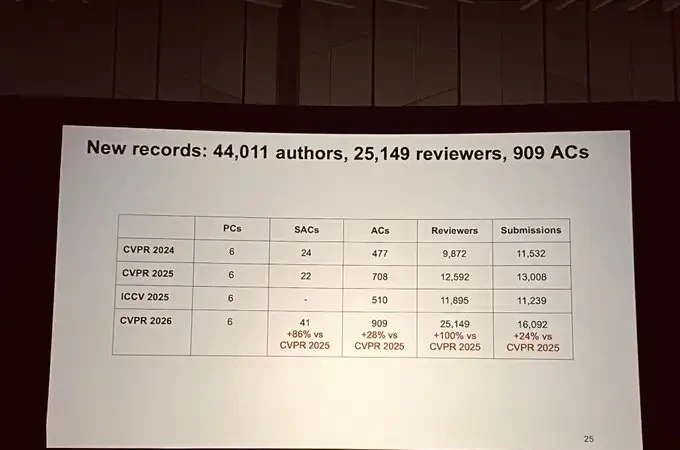
The number of authors, reviewers, and area chairs also broke historical records.
△ Image from the official CVPR 2026 X account.
Worth noting, though not entirely surprising, is that the representation of Chinese researchers was nearly at its peak this year.
From the first author of the Best Paper to the entire team behind the Best Student Paper, and even the four creators of ResNet in the Time-Tested Award, Chinese faces stood proudly in every category of honor.
However, this dominance by Chinese scholars has been the main theme for the past decade; it is no longer surprising, as AI research relies heavily on Chinese talent, much like…
But! What was most refreshing this year was a special presence among the awards given to big tech and elite universities:
ChordEdit, which received an Honorable Mention for Best Student Paper, comes from Guangdong University of Technology (GDUT), Huizhou University, Shenzhen University, and Peking University. The first author and several other team members are still undergraduate students.
A purely academic team, composed entirely of undergraduates, with the first author hailing from GDUT—a university without the resources or prestige of major tech firms or elite institutions.
Truly impressive.
Of course, Kai He (Kaiming He), who dominated CVPR this year, was also the top scorer in Guangdong’s college entrance examination (Gaokao).
This year’s CVPR was held in Denver, USA, but Guangdong truly shone.
Best Paper D4RT: Making Dynamic 4D Reconstruction “On-Demand”
The Best Paper Award this year went to D4RT (Efficiently Reconstructing Dynamic Scenes One D4RT at a Time).

△ Image from the official CVPR 2026 X account.
Reconstructing scene geometry and motion over time from a standard video—so-called 4D reconstruction (3D space + time)—has long been one of the toughest challenges in computer vision.
Previous methods either split the task into multiple modules for separate processing (which was slow and complex) or failed to handle point correspondences in dynamic regions, often suffering from multiple flaws simultaneously.
D4RT takes a different approach: replacing the inefficient method of “decoding everything frame by frame” with an on-demand query mechanism—“you ask where, I answer there.”
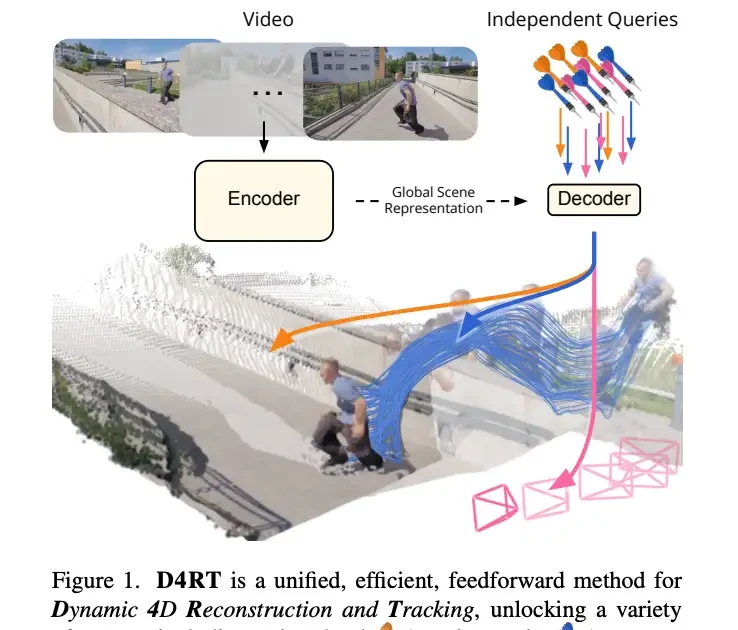
Specifically, the model first uses an encoder to compress the entire video into a global scene representation. It then employs a lightweight decoder dedicated to answering one question:
“What is the 3D position of a specific point in the video at a given moment?”
Depth maps, point clouds, point trajectories, and camera parameters are all generated from this single query interface, eliminating the need for separate decoders for each task.
The performance metrics are impressive: on an A100 GPU, D4RT achieves 200+ FPS for pose estimation, approximately 9 times faster than last year’s Best Paper winner VGGT, and about 100 times faster than MegaSaM, while also surpassing them in accuracy.
It sets new state-of-the-art (SOTA) results across a range of dynamic 4D reconstruction and tracking tasks, supporting dense holistic reconstruction for all pixels in a video.
- There is an interesting “academic lineage” easter egg here: Last year’s CVPR 2025 Best Paper was VGGT from Oxford’s Visual Geometry Group (VGG) lab. This year, D4RT directly targets VGGT as its primary benchmark.
Notably, the author list of D4RT includes Andrew Zisserman, a key figure behind the VGG lab.
Two consecutive years of CVPR’s highest honor along the same geometric reconstruction lineage.
Other Honors: Nominations, Longuet-Higgins Prize, Best Student Papers, and PAMI Awards
Honorable Mentions for Best Paper (2)
The first is SAM 3D (“SAM 3D: 3Dfy Anything in Images”), from Meta’s Superintelligence Lab.

△ Image from CVPR 2026 official X account.
This paper extends the “SAM” series from segmentation to single-image 3D reconstruction.
Given a standard photo, it predicts an object’s geometry, texture, and spatial layout, excelling at handling occlusions and cluttered scenes common in real-world photography.
Underpinning this is a human-machine collaborative annotation pipeline that acquired 3D data with visual grounding on an unprecedented scale. Through multi-stage training combining synthetic pre-training and real-world alignment, it has broken through the long-standing “data wall” in the 3D field.
In human preference tests involving real objects and scenes, it achieved a win rate of at least 5:1.
The second is NitroGen (“NitroGen: An Open Foundation Model for Generalist Gaming Agents”).

△ Image from CVPR 2026 official X account.
Developed by researchers from NVIDIA, Stanford University, Caltech, the University of Chicago, and UT Austin.
NitroGen is an open-source foundation model for generalist gaming agents. It was trained on over 1,000 games totaling 40,000 hours of gameplay video, focusing on three core achievements:
- Automatically reverse-engineering player actions from public game videos to build an internet-scale “video-action” dataset;
- Constructing a multi-game evaluation environment capable of measuring cross-game generalization;
- Training a unified “vision-action” policy using large-scale behavior cloning.
It can handle combat in 3D action games, precise platforming in 2D side-scrollers, and exploration in procedurally generated worlds. When transferred to unseen new games, it achieved up to a 52% relative improvement in task success rates.
This team is the same NVIDIA group that won the NeurIPS Best Paper award for MineDojo.
Longuet-Higgins Prize (Test of Time Award)
This prize is awarded to CVPR papers published ten years ago that have withstood the test of time. This year, it was awarded to two papers from 2016:
The first is ResNet (“Deep Residual Learning for Image Recognition”).

△ Image from CVPR 2026 official X account.
ResNet solved the dilemma that “deeper networks are harder to train” using residual connections, making networks with hundreds of layers truly trainable.
Over the past decade, it has become the default foundation for deep learning. Residual connections can be found everywhere, from CNNs in vision and Transformers in NLP to large language models.
Its citation count currently exceeds 320,000.
The second is the original paper for YOLO v1.

△ Image from CVPR 2026 official X account.
Before YOLO, the mainstream approach for detection was the R-CNN route: “generate candidate regions first, then classify each one.”
YOLO reformulated detection as an end-to-end regression problem, processing the entire image in a single pass to directly output “what is where and what it is.” Running at 45 FPS on a Titan X (and 155 FPS for the Fast version), it made real-time detection truly viable for the first time, directly spawning SSD, RetinaNet, and the entire YOLO family.
Its citation count currently approaches 80,000.
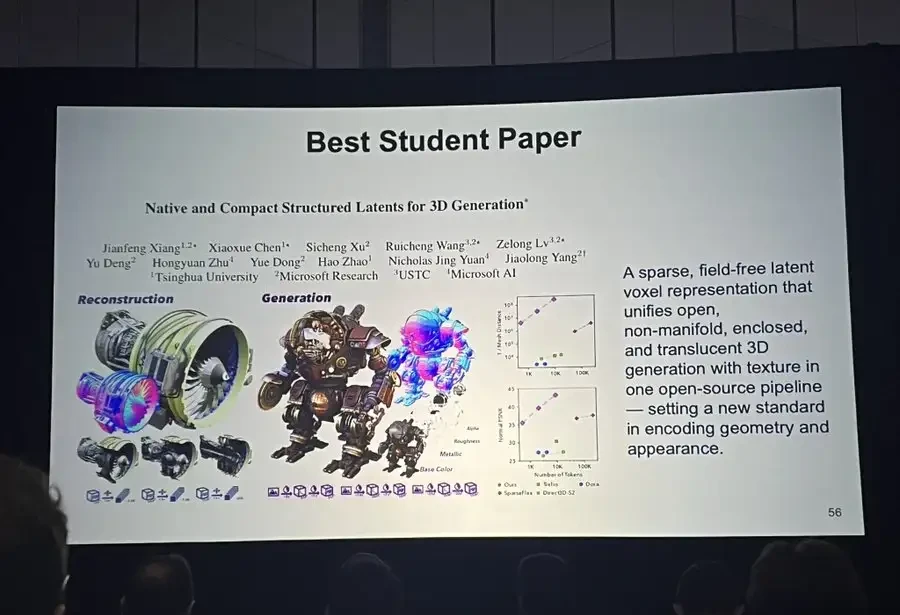
Best Student Paper: TRELLIS.2
The winning paper, “Native and Compact Structured Latents for 3D Generation,” comes from Tsinghua University, Microsoft Research, USTC, and Microsoft AI.
It is better known by its project name: TRELLIS.2.
△ Image from CVPR 2026 official X account.
It addresses the awkward situation in current 3D generation: while visual fidelity is increasing, representation methods lag behind, struggling to capture complex topologies and fine details.
The team’s solution is a novel sparse voxel structure called O-Voxel, which encodes both geometry and appearance (including PBR material parameters) simultaneously. This allows for stable modeling of open surfaces, non-manifold structures, and fully enclosed geometries.
Paired with a sparse compression VAE to condense the data into a compact latent space, they trained a 4-billion-parameter flow-matching model for image-to-3D generation.
Despite its scale, inference is fast, and the geometric and material quality of generated assets significantly outperform existing models.
Honorable Mention for Best Student Paper: ChordEdit
“ChordEdit: One-Step Low-Energy Transport for Image Editing,” from Guangdong University of Technology, Huizhou University, Shenzhen University, and Peking University, was also selected as an Oral presentation this year.

△ Image from CVPR 2026 official X account.
It addresses a pain point in one-step (single-inference) text-to-image models: while these models generate images quickly, forcing them into a single step for text-guided image editing often causes failures—such as object deformation or unintended changes to areas that should remain preserved.
The team reformulated image editing as an optimal transport problem: performing transport between distributions defined by the source and target texts. Based on dynamic optimal transport theory, they derived a low-energy control strategy that makes the editing field smoother and more stable, allowing for high-quality edits in a single step.
The result is that these “fast but hard-to-edit” models have gained true real-time editing capabilities for the first time.
PAMI Distinguished Awards
Young Researcher Award: Given to young scholars within seven years of receiving their PhD who have established representative research directions. Two recipients were honored this year.
One is Deepak Pathak, Associate Professor at CMU, whose work spans computer vision, machine learning, and robotics, focusing on how robots learn, perceive, and act in the real world.
The other is Vincent Sitzmann, Associate Professor at MIT, specializing in neural scene representations, 3D vision, and world models, with the goal of enabling machines to understand and simulate the world like humans do.

△ Image from CVPR 2026 official X account.
Thomas S. Huang Memorial Award: Honors scholars who serve as exemplars in research, teaching/mentoring, and community service.
This year, it was awarded to Cornell University Professor Noah Snavely (Computer Vision and Graphics).

Notably, this award was established to commemorate the late Chinese-American computer vision pioneer Thomas S. Huang.
Chinese Researchers Continue to Shine at CVPR
The presence of Chinese researchers remains prominent at this year’s CVPR.
This dominance is evident from the data on both submissions and reviews: in terms of author affiliations, China ranks first by a wide margin with 23,233 authors, nearly three times that of second-place United States (7,556).
Chinese reviewers also outnumber those from other regions, with 10,687 participants.
△ Image source: CVPR2026 official X account
Looking at the award-winning papers, Chinese faces are abundant across all categories.
The first author of the Best Paper D4RT is Chuhan Zhang, a Senior Research Scientist at DeepMind.
She previously earned her Ph.D. from the Visual Geometry Group (VGG) at the University of Oxford, under the supervision of Andrew Zisserman. Her research interests cover video understanding, dynamic 3D scene reconstruction, and automated evaluation of generative models.

Among the Best Paper authors are several Chinese researchers from Oxford and DeepMind.
Junyu Xie, also from Oxford’s VGG group and advised by Andrew Zisserman and Weidi Xie, completed the D4RT work during his internship at DeepMind in the summer of 2025.

Additionally, Shuyang Sun and Junlin Zhang, both researchers at Google DeepMind, are included among the authors.
The Best Student Paper TRELLIS.2 was awarded to a team composed entirely of Chinese researchers.

First author Jianfeng Xiang is a Ph.D. student at Tsinghua University and was also the first author of the previous hit 3D generation model, TRELLIS (v1).

Xiaoxue Chen, a Ph.D. student at the Institute for AI Industry Research (AIR) at Tsinghua University, specializes in computer vision.

Corresponding author Jiaolong Yang is from Microsoft Research Asia (MSRA), with long-standing expertise in 3D vision and generation.

Sicheng Xu, also from MSRA, focuses on physical AI and multimodal learning.

Ruicheng Wang, a Ph.D. student in the School of Computer Science and Technology at the University of Science and Technology of China (USTC), researches spatial intelligence.
Zelong Lv, a Ph.D. student in the School of Computer Science at USTC.

Yu Deng, a Senior Researcher at MSRA, specializes in 3D visual generation, spatial understanding, and embodied AI.

Hao Zhao, an Assistant Professor at Tsinghua University’s Institute for AI Industry Research (AIR), previously served as a Research Scientist at Intel Labs China. His research focuses on robotic 3D scene understanding, embodied AI, and autonomous driving.

Nicholas Jing Yuan, a Global Partner at Microsoft and Senior Vice President Technical Advisor; IEEE Fellow, with over 17,000 citations.
Previously, he served as the Vice President of Artificial Intelligence at Huawei Cloud, Chief Scientist, and Director of the Language and Speech Innovation Laboratory. During his tenure at Microsoft, he led the development of Microsoft Xiaoice’s AI-generated content technology.

The Best Student Paper nomination ChordEdit features a team composed entirely of students from domestic Chinese universities, including several undergraduates.

First author Liangsi Lu is an undergraduate majoring in Information and Computing Science at Guangdong University of Technology (GDUT), with research interests in representation learning and visual generation.

Corresponding author Yang Shi is an undergraduate in the School of Computer Science at GDUT, focusing on computer vision and data mining.
The team also includes researchers from Shenzhen University, Peking University, and other institutions, making it a rare “fully local” contingent among this year’s Chinese honorees.
Xuhang Chen, an instructor in the School of Computer Science and Engineering at Huizhou University and a researcher at Xuri Information Technology, earned his Ph.D. in Computer Science from the University of Macau and the Shenzhen Institute of Advanced Technology (SIAT), Chinese Academy of Sciences, in 2025.

Other authors include Minzhe Guo (GDUT), Shichu Li (Shenzhen University), and Jingchao Wang (Peking University).
Next are the four authors of ResNet, which received the Time Test Award: Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.
This work, published ten years ago from Microsoft Research Asia, now underpins nearly half of the deep learning landscape.
First author Kaiming He is arguably the most well-known among them.
Following ResNet, he developed a series of foundational works including Mask R-CNN, FPN, and MAE. He has since moved from Meta AI to teach at MIT and is currently one of the most cited researchers in computer vision.
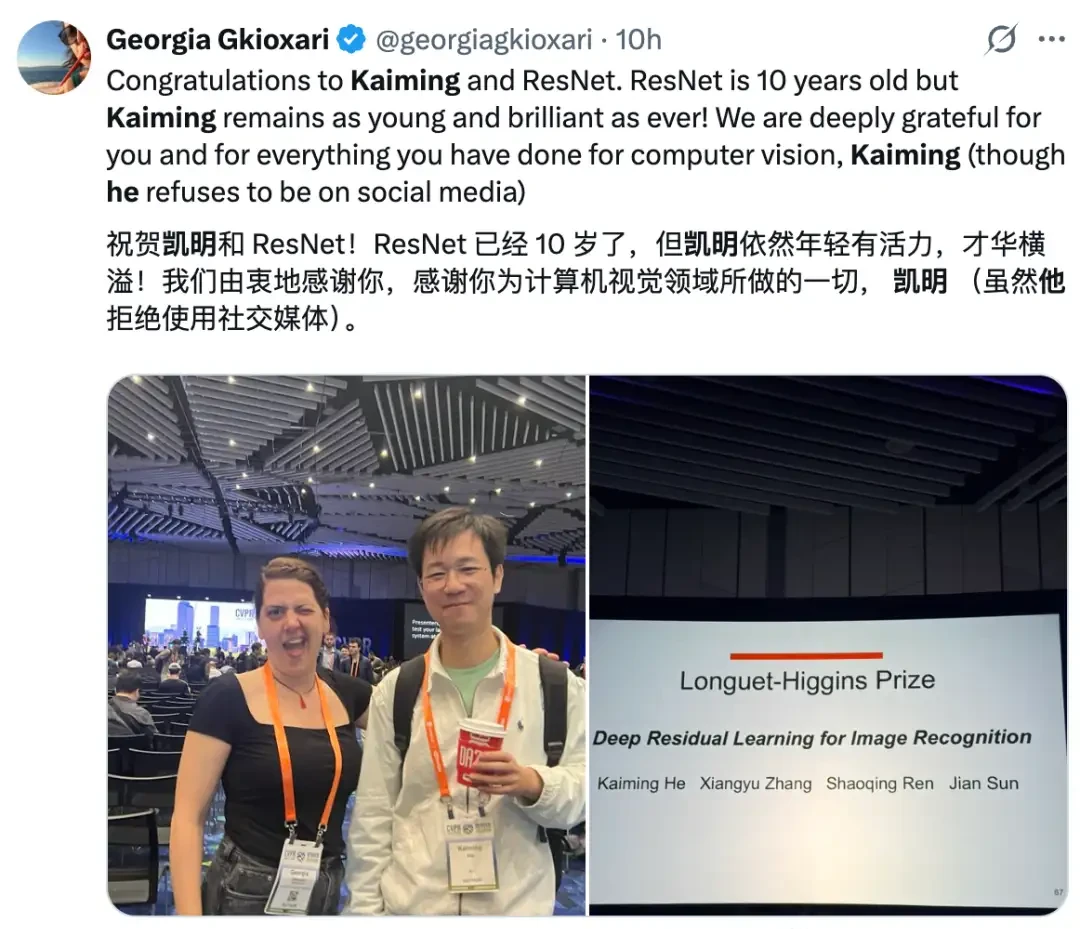
Netizens also shared photos with him on X, noting that he seems to have lost some weight.
Furthermore, Meta’s Superintelligence Lab (MSL) and two nominated papers from NVIDIA feature a large number of Chinese authors, creating an overwhelming presence…

Rumors suggest that non-Chinese employees at Meta may feel a sense of exclusion due to the high proportion of Chinese researchers in their teams… This is evident from the author lists.

Interested readers can continue to dig deeper (the editor is exhausted).
In conclusion, let us congratulate all friends who received recognition and awards at CVPR 2026. Let us also prepare for the upcoming era of intense competition in AI.
If you achieve success, use it to advance AI and benefit all humanity.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google