After ImageNet, Fei-Fei Li strikes again!
The team led by Fei-Fei Li has just released ESI-Bench, a new benchmark specifically designed to evaluate embodied spatial intelligence.

Previous benchmarks for spatial intelligence assumed optimal observations were provided to the model. ESI-Bench is the first to transform the observer into an actor, closing the perception-action loop.
It provides a systematic evaluation framework for the field of embodied spatial intelligence, covering four dimensions of core human spatial cognitive abilities.
The paper’s core conclusion is: Current AI is excellent at interpreting images, but it is still far from possessing “spatial intelligence” that involves moving, touching, and actively seeking answers.

What is ESI-Bench?
ESI-Bench was released against the backdrop of current spatial intelligence benchmarks, which primarily measure “passive perception.”
Throwing one or a few images at a model and asking questions like “Is object A to the left or right of object B?”, “How much water can this cup hold?”, or “Is there anything in the drawer” tests the model’s visual acuity rather than its spatial reasoning capabilities.
In contrast, how do humans approach these tasks? Humans stand up, walk around an object to see it from behind, open drawers, and pour out liquids to measure them.
This is the core stance of ESI-Bench: Transforming the observer into an actor.

In the real world, agents must act like humans: actively deciding on actions to gather evidence, and then making subsequent judgments based on new observations. The team refers to this as the “Perception-Action Loop.”
ESI-Bench is a new spatial intelligence evaluation benchmark that surpasses existing standards. It comprises 10 task categories, 29 sub-categories, and 3,081 task instances, all constructed within the OmniGibson simulation platform using scene assets from the BEHAVIOR-1K dataset.
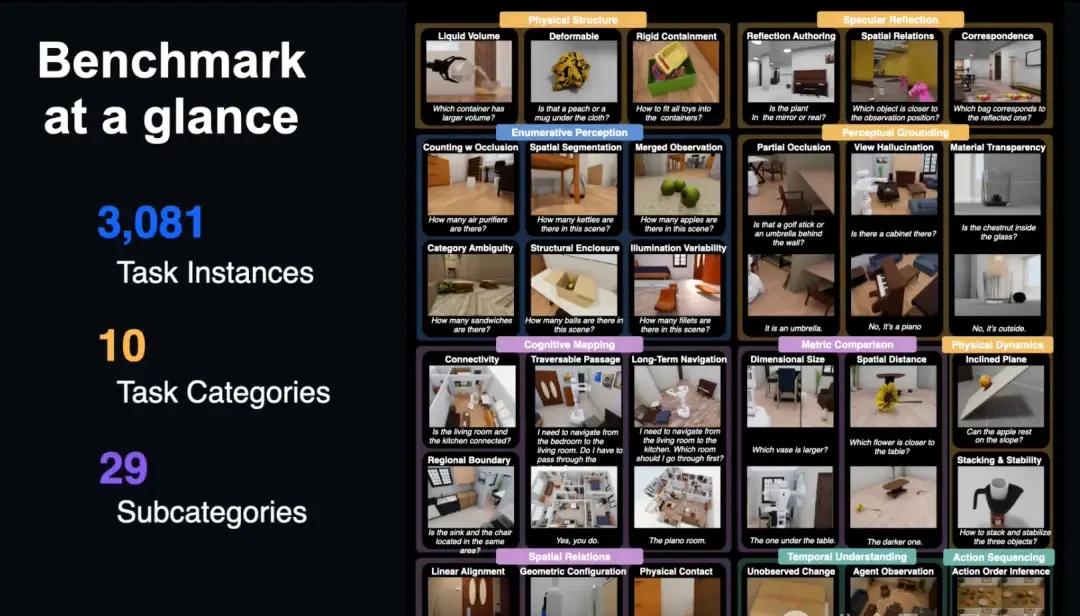
All tasks are centered around Spelke’s four core knowledge systems, representing the spatial intuitions humans possess innately from infancy: object representation, layout and geometry, number representation, and goal-directed action.
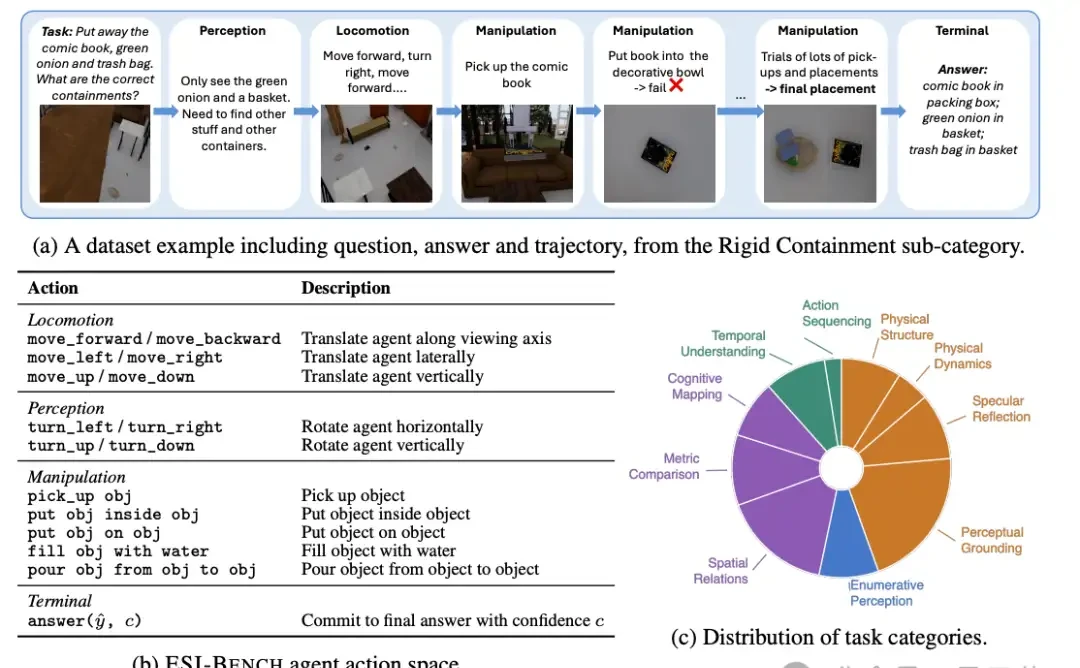
Its key setting is mandatory action. For every question, the AI agent must take active steps to gather sufficient information before answering. The model cannot sit idle waiting for images; it must decide where to go, what to look at, what to pick up, and how to manipulate objects.

Here are a few specific examples:
Consider the “rigid containment” task: Given several containers and objects, the agent must fit all objects inside. Some containers have small openings, others have internal dividers, and some require lids to be lifted to reveal their true capacity.
The model must approach, lean in, or even pick up the container to observe it from the bottom to determine if it can hold the items.

Then there is the “liquid volume” task: Two cups may appear identical in capacity based on their exterior. The model needs to pour water into them for testing or pick them up to gauge their weight.
This should give you an intuitive sense of the design philosophy behind this benchmark:
The correct answer does not exist within any single image; the agent must actively act and reason to derive the correct result.
The team specifically highlights that ESI-Bench surpasses previous work in three key areas:
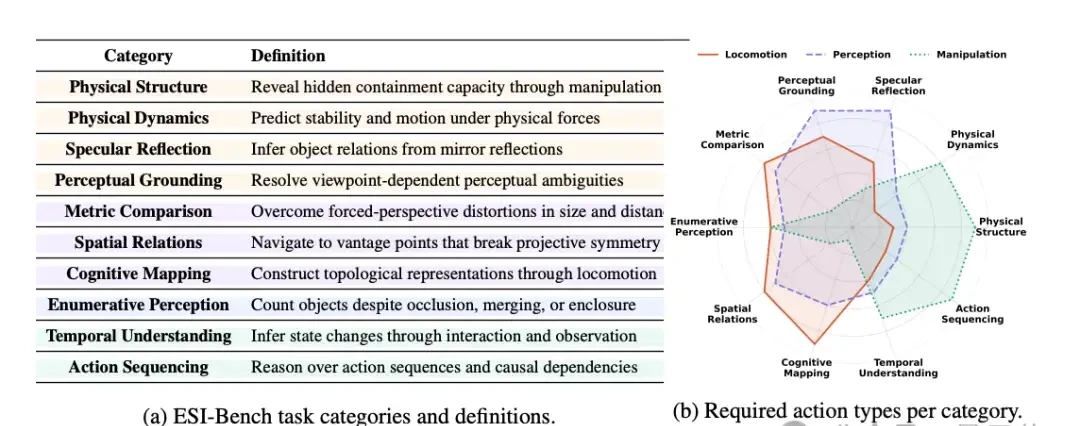
From spatial perception to spatial capability: Here, agents are evaluated not only on what they can perceive but also on whether they know which specific capabilities to deploy to solve spatial tasks.
Selective perception: Agents must determine which observations are worth acquiring, prioritizing information relevant to the task over redundant or uninformative inputs.
Resolving perceptual ambiguity: Agents must reason through misleading observations to infer hidden spatial structures and underlying physical constraints that go beyond direct observation.
What did we find? 3 Core Conclusions
The team conducted comprehensive tests on current state-of-the-art multimodal large language models, including GPT-5 and the Gemini series.
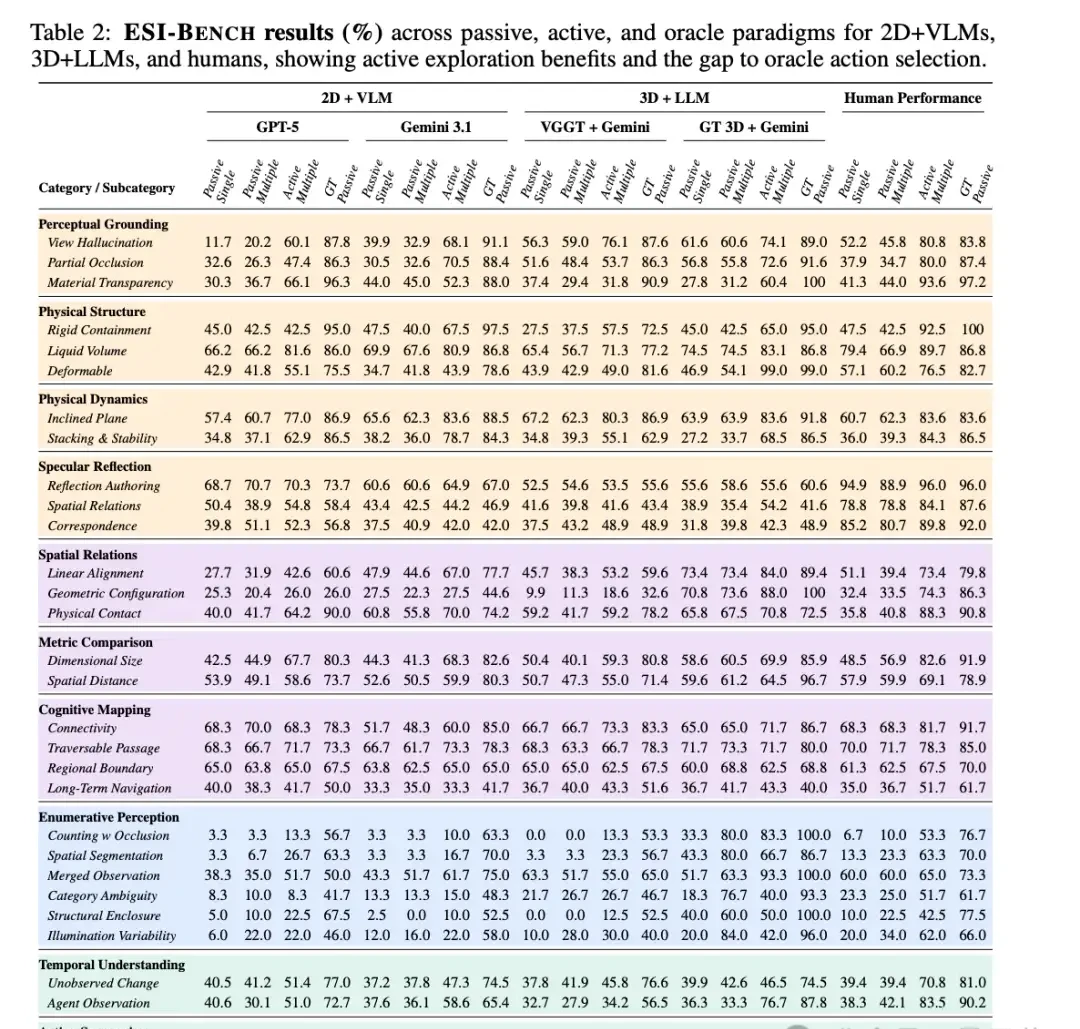
This is the primary experimental results chart, showing the accuracy of various tasks under three paradigms in ESI-Bench: passive perception, active exploration, and Oracle. It covers 2D+VLM, 3D+LLM, and human baselines.
There are three core conclusions.
First, perception is not the bottleneck; action is.
The good news is that active exploration is indeed effective. Without additional instructions, agents spontaneously emerged with various spatial strategies.
For example, moving behind an object to observe it (move-behind), switching to a top-down perspective (top-down), picking up objects (pick-up), or pouring out liquids to verify contents (pour-out).

In the “partial occlusion” task, Gemini 3.1’s accuracy skyrocketed from 14.6% to 95.1% when provided with the optimal viewing angle.
This indicates that the models’ inherent perceptual capabilities are strong; given the right perspective, they can understand what they see.
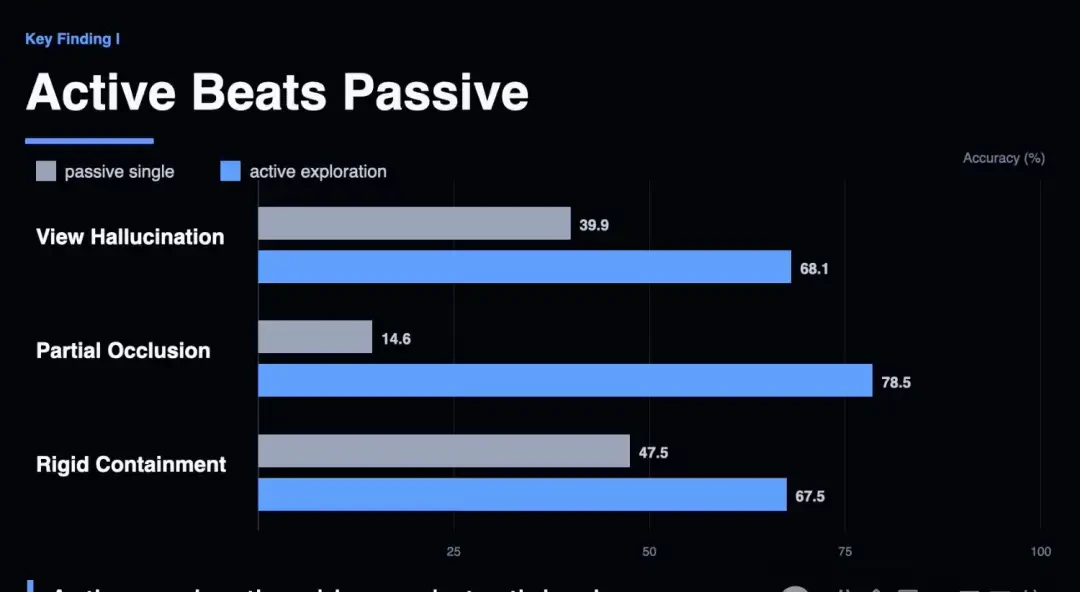
However, the problem lies in the fact that models cannot find that correct perspective on their own.
A worse issue is that passive multi-view strategies are not only ineffective but harmful.
Showing GPT-5 several random-angle images reduced its accuracy on spatial distance tasks from 53.9% to 49.1%. The more pictures it saw, the lower its score became.
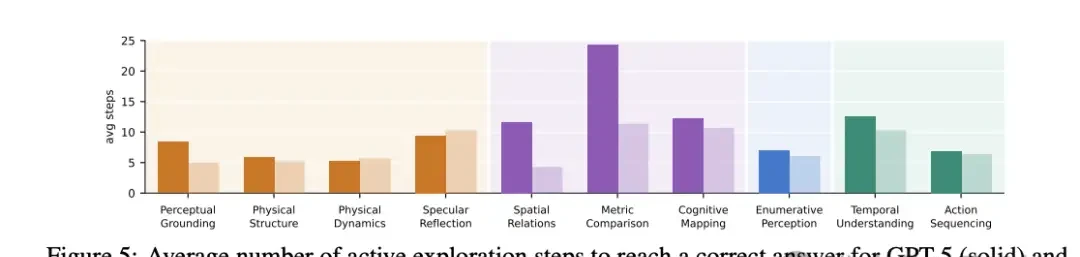
△ Average steps required for GPT-5 and Gemini 3.1 to reach the correct answer during active exploration
The team named this phenomenon “Action Blindness,” where a poor action leads to a poor perspective, which triggers even worse actions, creating an irreversible cascade of failures.
In structural enclosure tasks, the gap between active exploration strategies and the “God’s eye view” is as high as 49.7%.
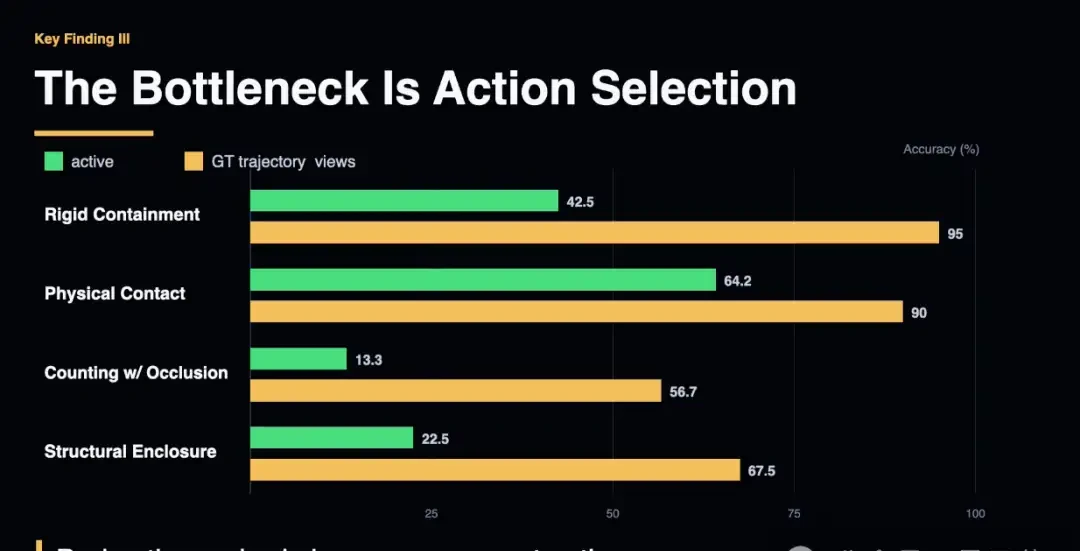
In other words, the bottleneck in spatial intelligence is not that visual models are weak enough; rather, action strategies are nearly non-existent.
Second, 3D reconstruction is not a panacea; imperfect 3D is worse than 2D.
Since passive 2D image viewing doesn’t work well, what about 3D? This is the approach taken by many current embodied AI teams: first reconstructing the 3D scene, then performing reasoning on the scene map.
The results showed that if provided with ground-truth 3D (perfect geometry from a God’s eye view), performance is indeed strong.
In material transparency tasks, Gemini scored 44.0% in its 2D version and 60.4% in its 3D version, an improvement of 16.4 percentage points. In tasks requiring precise depth information, 3D grounding has a natural advantage.
But what about real-world reconstruction? The team used the current state-of-the-art VGGT model for scene reconstruction and fed the results into reasoning models.
The results were dismal: in geometric configuration tasks, the 2D baseline scored 27.5%, while the scene map reconstructed by VGGT scored only 9.9%.
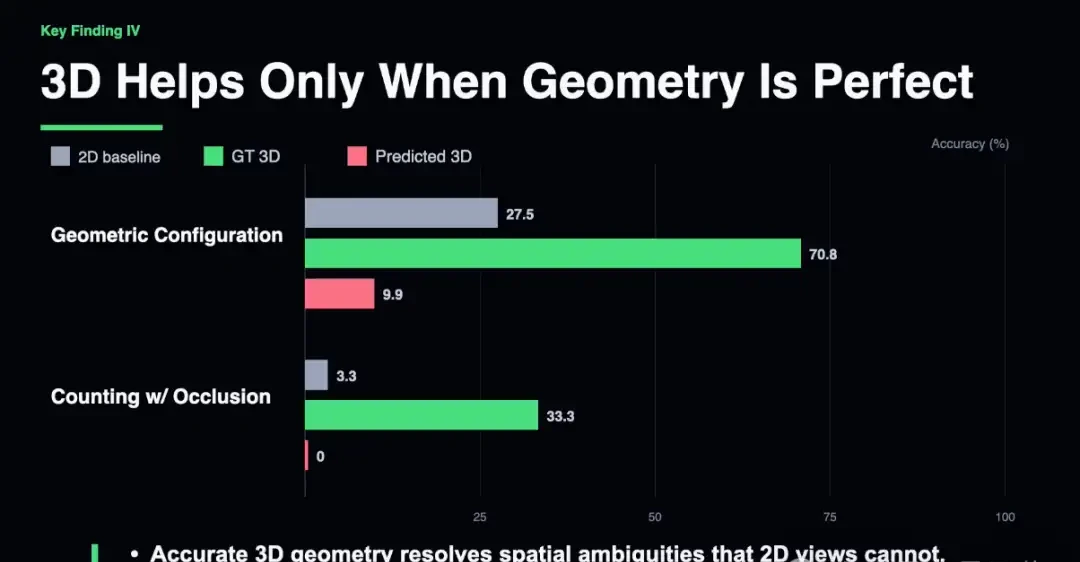
This indicates that imperfect 3D is not a neutral failure; it is a negative one. Geometric artifacts, errors in occlusion completion, and depth estimation biases encode distorted information into scene maps, effectively feeding “toxic” inputs to the reasoning model.
In contrast, while 2D provides less information, at least it remains undistorted. If 3D reconstruction quality is subpar, it performs worse than 2D.
Third, metacognitive defects: Models do not know if they have seen enough.
The paper also includes a set of comparative experiments exploring the gap between agents’ and humans’ spatial reasoning capabilities.
The results revealed that although there is a perceptual gap between humans and models, this gap may be smaller than commonly believed.
In some categories, the model’s passive performance can even match or surpass human performance.
Under real trajectory conditions, Gemini achieved 88.4% accuracy in partial occlusion tasks, compared to 87.4% for humans; GPT-5 reached 96.3% in material transparency tasks, while humans scored 97.2%.
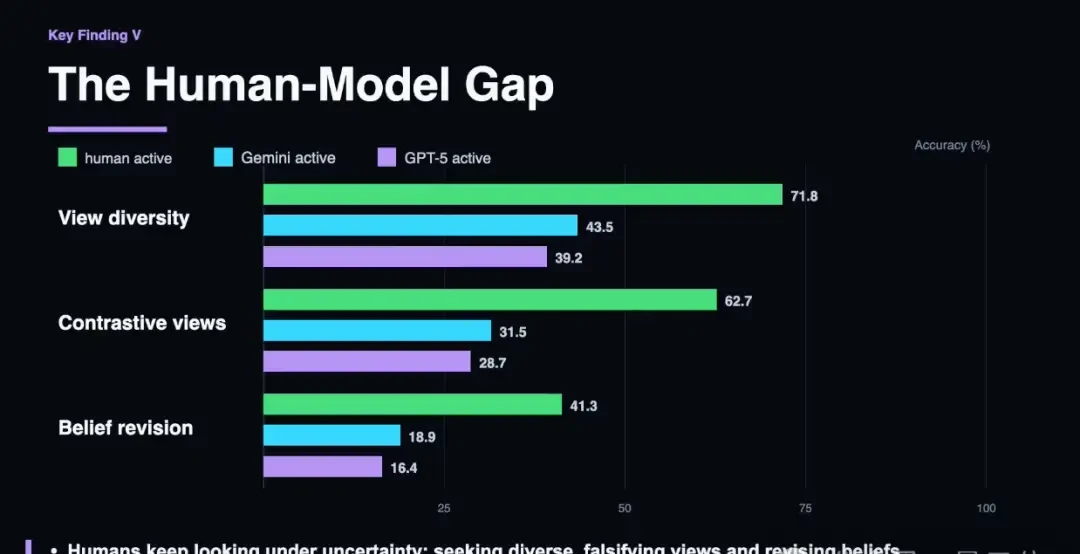
However, in active exploration scenarios, the gap widens significantly.
Humans outperform models due to clear observation goals and stopping criteria, with their active exploration performance closely mirroring their passive performance under real trajectories.
For instance, in physical contact tasks, human accuracy was 88.3%, while GPT-5 scored only 64.2%; in material transparency tasks, humans achieved 93.6% accuracy, whereas Gemini 3.1 scored just 52.3%.
By analyzing the exploration trajectories of models and humans, the team found that humans exhibit stronger cognitive caution: they gather more observations before making judgments, actively seek perspectives that might falsify current hypotheses, and lower their confidence in ambiguous situations.
Models, on the other hand, stop exploring too early. Even when evidence is ambiguous, they make high-confidence judgments after only a few steps, leading to spatial hallucinations contrary to the scene’s actual state.

The models’ overconfidence is exacerbated by directional biases in action selection: instead of probing orthogonal angles or seeking perspectives that could overturn initial impressions, models repeatedly move in the same direction, accumulating redundant information rather than effective observations.
The team characterizes this as a metacognitive defect: the model does not know what it does not know.
It lacks an innate “skepticism mechanism,” unable to assess whether current information is sufficient or adjust beliefs based on contradictory evidence.
This issue differs fundamentally from perceptual capabilities and represents a more foundational challenge that cannot be solved merely by stronger visual encoders or additional exploration steps.
Paper Authors
Finally, let’s introduce the team behind this work.

The first author is Yining Hong.
Yining Hong is a postdoctoral researcher at Stanford University, advised by Professor Yejin Choi. She also receives close guidance from Professors Leonidas Guibas, Jiajun Wu, and Fei-Fei Li.

She earned her Ph.D. in Computer Science from UCLA and completed her undergraduate studies in the Department of Electronic Engineering at Shanghai Jiao Tong University.
Additionally, she is a professional musician who regularly tours with her band. She also served as the Social Chair for CVPR 2026, where she was responsible for organizing the conference reception and musical performances.
Jiageng Liu is a Ph.D. student in the Mobility Lab at UCLA.
He completed his undergraduate studies at Zhejiang University’s Zhu Kezhen Honors College and the Turing Class of the School of Computer Science and Technology, earning a bachelor’s degree in Artificial Intelligence.
Han Yin is an undergraduate student at Tsinghua University majoring in Computer Science and Technology, currently interning at Stanford University.

Stanford professors Fei-Fei Li, Jiajun Wu, and Yejin Choi also appear on the author list.


Additionally, Professor Manling Li from Northwestern University and Professor Leonidas Guibas from Stanford University are among the contributors.
References
- ESI-Bench: Towards Embodied Spatial Intelligence that Closes the Perception-Action Loop — Spatial intelligence unfolds through a perception-action loop: agents act to acquire observations, and reason about how observations vary as a function of action. Rather than passively processing what is seen, they actively engage with their environment.
- esi bench.github — esi-bench.github.io/