Qwen3.6 has just open-sourced Qwen3.6-35B-A3B.
This is somewhat disappointing, not for me personally, but for the many netizens who were anticipating the release of Qwen3.6-27B.
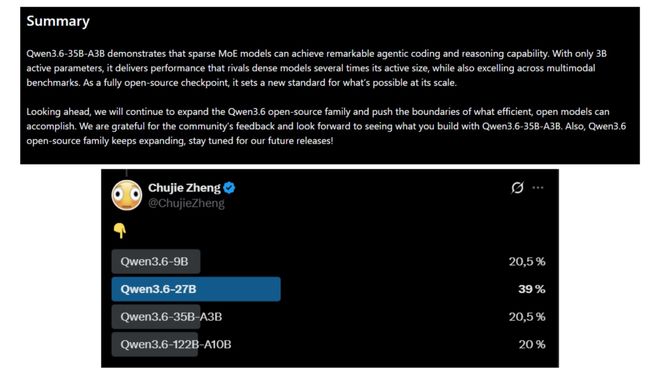
Overview
Qwen3.6-35B-A3B is a compact yet powerful model based on the Mixture of Experts (MoE) architecture: it has a total parameter count of 35 billion, but only activates 3 billion parameters during inference.
What does this mean? The computational resources required to run it are roughly equivalent to those needed for a 3-billion-parameter dense model, yet its performance rivals that of 27B or 30B dense large language models.
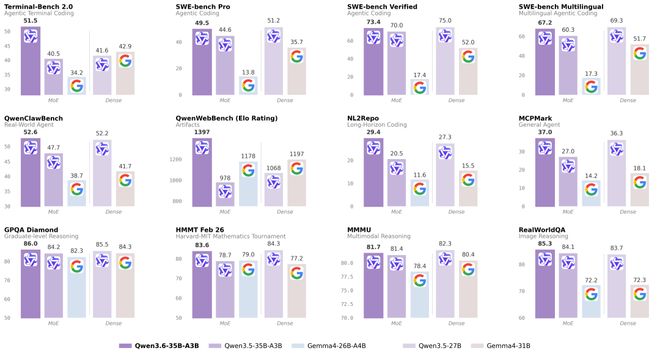
Comprehensive Evaluation Scores for Qwen3.6-35B-A3B
Key Highlights of This Open Source Release:
- Significant Improvement in Agentic Coding Capabilities: Front-end workflows and repository-level code reasoning have reached a new level.
- Thinking Preservation: A brand-new feature that retains historical reasoning chains across multi-turn conversations, reducing redundant thinking overhead in iterative development scenarios.
- Native Multimodality: It excels in both vision and language; it is not a patched-together solution but includes a built-in visual encoder.
- Ultra-Long Context Support: Natively supports 262,144 tokens, which can be extended to 1 million tokens when YaRN is enabled.
Architecture Deep Dive: How Does It Achieve 35B Total / 3B Activated Parameters?
Qwen3.6 employs a hybrid architecture that alternately stacks Gated DeltaNet (linear attention) and Gated Attention (standard attention). It is neither purely Transformer-based nor purely linear-attention-based, but rather a fusion of both.
This is combined with MoE (Mixture of Experts) layers:
- 256 experts, where only 8 routed experts + 1 shared expert are activated during each inference step.
- The model consists of 40 stacked layers with an hidden dimension of 2048.
The advantage of this architecture is that most experts remain “asleep” during inference, resulting in extremely low computational demands; however, the large total parameter count provides rich knowledge density. In short, the investment goes into training, while inference costs are minimized.
Performance Benchmarks: Agent Programming Has Truly Soared
Here are the core benchmark data points, comparing Qwen3.6-35B-A3B against peers of similar scale: Qwen3.5-35B-A3B (previous generation), Gemma4-31B, and Qwen3.5-27B (dense 27B).
| Benchmark | Qwen3.5-27B | Gemma4-31B | Qwen3.5-35BA3B | Qwen3.6-35BA3B |
|---|---|---|---|---|
| SWE-bench Verified | 75.0 | 52.0 | 70.0 | 73.4 |
| Terminal-Bench 2.0 | 41.6 | 42.9 | 40.5 | 51.5 |
| QwenWebBench (Front-end) | 1068 | 1197 | 978 | 1397 |
| Claw-Eval Avg | 64.3 | 48.5 | 65.4 | 68.7 |
Terminal-Bench scores jumped from 40.5 to 51.5, an increase of 11 percentage points.
QwenWebBench (front-end code generation) surged from 978 to 1397, leaving the previous generation far behind.
The metric I am most interested in is QwenWebBench—it evaluates practical front-end tasks such as generating web pages, mini-games, and data visualizations. This score indicates that Qwen3.6 has made a qualitative leap in scenarios like “generating an app from a single prompt.”
Multimodal capabilities are also strong: Visual question answering performance in spatial intelligence (RefCOCO: 92.0, ODInW13: 50.8) even surpasses Claude Sonnet 4.5, while document understanding and OCR tasks remain at SOTA levels.
Deployment
I am still downloading the model at a snail’s pace, so here are deployment guides for several inference engines in the meantime.
Model Address: modelscope.cn/models/Qwen/Qwen3.6-35B-A3B
Recommended Option 1: SGLang (High-throughput production scenarios)
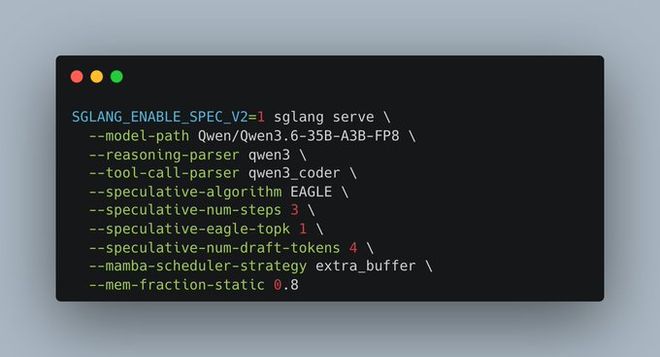
uv pip install sglang[all]To accelerate inference, you can enable MTP (Multi-Token Prediction)—see our MTP guide for Qwen3.6-35B-A3B:
export SGLANG_ENABLE_SPEC_V2=1
python -m sglang.launch_server \
--model-path Qwen/Qwen3.6-35B-A3B \
--port 8000 --tp-size 8 \
--reasoning-parser qwen3 \
--speculative-algorithm NEXTN \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4Recommended Option 2: vLLM
uv pip install vllm --torch-backend=autoIf you only need text inference and do not require visual capabilities, adding --language-model-only can free up VRAM from the visual encoder for the KV Cache, resulting in higher throughput.
Usage
The most important new feature is preserve_thinking, which is highly recommended to enable for Agent scenarios.
By default, the model retains only the reasoning process of the latest message per turn. After enabling preserve_thinking=True, reasoning chains from historical turns are retained and reused, which is particularly useful for multi-step tasks—reducing redundant thinking and improving KV Cache utilization.
from openai import OpenAI
client = OpenAI(
api_key="DASHSCOPE_API_KEY",
base_url="https://dashscope-intl.aliyuncs.com/compatible-mode/v1",
)Disabling the Chain of Thought (Non-thinking mode) is also simple, offering faster speeds for daily conversation scenarios:
extra_body={
"chat_template_kwargs": {"enable_thinking": False},
}❝ Note: Qwen3.6 no longer supports soft switching via
/thinkor/nothinkcommands; control must be handled via parameters.
Coding Agent Tool Integration
Qwen3.6-35B-A3B can directly integrate with three mainstream Coding Agents:
Option 1: Qwen Code (Recommended, optimized specifically for the Qwen series)
npm install -g @qwen-code/qwen-code@latest
qwen
# Run /auth inside to configure your API KeyOption 2: OpenClaw (Open source, supports self-deployment)
curl -fsSL https://molt.bot/install.sh | bash
export DASHSCOPE_API_KEY=
openclaw dashboardOption 3: Claude Code + Qwen API (A surprising combination)
Qwen supports the Anthropic API protocol, meaning you can wrap the Qwen model using Claude Code:
npm install -g @anthropic-ai/claude-code
export ANTHROPIC_MODEL="qwen3.6-flash"
export ANTHROPIC_SMALL_FAST_MODEL="qwen3.6-flash"
export ANTHROPIC_BASE_URL=https://dashscope-intl.aliyuncs.com/apps/anthropic
export ANTHROPIC_AUTH_TOKEN= This approach is quite interesting: it combines the UI experience of Claude Code with the model capabilities of Qwen, while API costs are billed through Alibaba Cloud, which is significantly cheaper than Anthropic.
Local Execution: Running on Mac / PC (Unsloth GGUF)
Unsloth has successfully implemented the GGUF quantized version of Qwen3.6-35B-A3B, making it fully feasible to run locally using llama.cpp.
They utilize their proprietary Dynamic 2.0 quantization scheme—which applies precision compensation to critical layers—yielding results significantly better than standard Q4 quantization.
Officially, it is stated that a Mac with 22GB of memory can run this model.
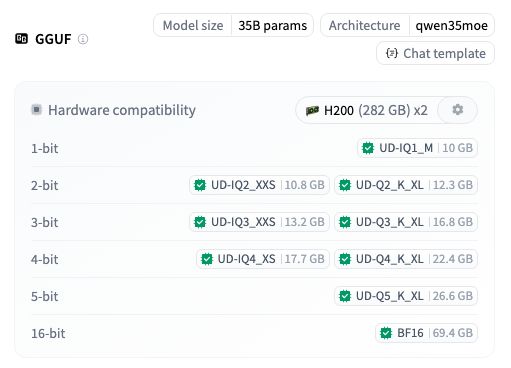
Memory Requirements Reference (RAM + VRAM combined):
| Quantization Precision | Required Memory |
|---|---|
| Q2 Extreme Compression | ~17 GB |
| Q4_K_XL (Recommended) | ~23 GB |
| Q5 | ~30 GB |
| Q6 | ~38 GB |
| BF16 Full Precision | ~70 GB |
❝ ⚠️ Important Note: Currently, the GGUF version of Qwen3.6 does not support Ollama because the visual encoder (mmproj) requires a separate file load, which Ollama cannot currently handle. Please use llama.cpp compatible backends (Unsloth Studio or llama-server).
Option 1: Unsloth Studio (GUI, beginner-friendly)
Install with one command; it automatically sets up the llama.cpp environment:
# macOS / Linux / WSL
curl -fsSL https://unsloth.ai/install.sh | shOpen your browser and visit http://localhost:8888, search for Qwen3.6, and download the corresponding quantized version. Parameters are configured automatically, and there is a toggle for chain-of-thought reasoning, making it extremely user-friendly for beginners.
Option 2: llama-server Command Line
Suitable for scenarios requiring custom parameters or integration with Agent tools:
./llama.cpp/llama-server \
--model unsloth/Qwen3.6-35B-A3B-GGUF/Qwen3.6-35B-A3B-UD-Q4_K_XL.ggufNote that both files must be downloaded: the main model .gguf and the visual encoder mmproj-F16.gguf. Neither can be omitted.
Once started, you can call it using an OpenAI-compatible API:
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8001/v1",
api_key="sk-no-key-required",
)Switching to Chain-of-Thought mode is also straightforward; simply add one line to the startup parameters:
# Disable chain of thought (faster, for daily conversation)
--chat-template-kwargs '{"enable_thinking":false}'After launching llama-server, you can similarly integrate it with Claude Code or Qwen Code, using your local quantized model as an Agent backend. This allows for fully offline operation without incurring any API costs.
Summary
Qwen3.6-35B-A3B is a highly compelling open-source MoE model:
- ✅ Only 3B activated parameters, resulting in extremely low inference costs; it can even run on personal GPUs.
- ✅ Significant improvements in Agent programming capabilities, with QwenWebBench performance far surpassing previous generations.
- ✅ Native multimodal support, with visual understanding capabilities comparable to Claude Sonnet 4.5.
- ✅ The new
preserve_thinkingfeature enhances multi-step Agent scenarios. - ✅ 262K native context window, expandable to 1 million tokens using YaRN.
- ⚠️ Soft switching via
/thinkand/nothinkis no longer supported; migration costs should be considered. - ⚠️ Full-precision deployment still requires multiple GPUs, but the Unsloth GGUF quantized version can run on a Mac with 22GB of memory.
- ⚠️ The GGUF version currently does not support Ollama; you must use
llama.cppor Unsloth Studio instead.
For those looking to deploy Coding Agents on their own servers, this is likely the most cost-effective open-source option available today.
Creating content like this takes effort. If you found this article useful, please consider following me. I’d appreciate your support: a like, share, and bookmark. Thanks for reading, and see you in the next post!
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google