If you are running Qwen3.6-35B-A3B locally, the easiest free speed boost is often MTP (Multi-Token Prediction)—speculative decoding built into the model weights, not a separate draft model.
This guide explains what MTP does, when it helps, and the exact SGLang settings that pair with the 35B-A3B MoE checkpoint.
What Is MTP?
Multi-Token Prediction trains the model to guess several future tokens at once. At inference time, a lightweight draft head proposes multiple candidate tokens; the main model verifies them in parallel. Accepted drafts become output without running a full decode step for every single token.
That is different from classic autoregressive decoding, which generates one token per forward pass.
MTP became widely known through DeepSeek-V3 and similar architectures. Qwen3.6 ships dedicated MTP weights (mtp.safetensors) for both the 35B-A3B MoE and 27B dense variants, so you can turn on speculative decoding without downloading a second model.
Why It Matters for Qwen3.6-35B-A3B
Qwen3.6-35B-A3B already activates only ~3B parameters per step (MoE). MTP adds another layer of efficiency on top:
| Without MTP | With MTP (typical) |
|---|---|
| 1 token verified per decode step | Several tokens accepted per step when drafts match |
| Lower VRAM overhead | Slightly higher VRAM for draft buffers |
| Predictable latency | Best for interactive chat, agents, and coding loops |
| Simplest config | Requires correct SGLang flags + env var |
For agentic coding or chat, MTP often cuts time-to-first-token clusters and improves tokens per second at batch size 1—the case most home labs care about.
Companion guides: Full 35B-A3B deployment · 27B vs 35B-A3B choice
How Speculative Decoding Works (30-Second Version)
- Draft: MTP head proposes up to N tokens ahead.
- Verify: The main model checks those proposals in one batched pass.
- Accept: Matching prefixes are emitted; mismatches are discarded and decoding continues from the first error.
SGLang exposes this through --speculative-algorithm NEXTN for Qwen3.6 (NEXTN is the integrated MTP path—do not point at a separate draft checkpoint).
Enable MTP on SGLang (Recommended)
1. Set the environment variable (required)
Without this, SGLang may treat MTP incorrectly and attempt to load a second full model as a draft—often causing OOM:
export SGLANG_ENABLE_SPEC_V2=12. Launch Qwen3.6-35B-A3B with NEXTN
uv pip install "sglang[all]"
SGLANG_ENABLE_SPEC_V2=1 python -m sglang.launch_server \
--model-path Qwen/Qwen3.6-35B-A3B \
--port 8000 \
--tp-size 8 \
--reasoning-parser qwen3 \
--speculative-algorithm NEXTN \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4For FP8 weights on a single large GPU:
SGLANG_ENABLE_SPEC_V2=1 python -m sglang.launch_server \
--model-path Qwen/Qwen3.6-35B-A3B-FP8 \
--port 8000 \
--tp-size 1 \
--reasoning-parser qwen3 \
--tool-call-parser qwen3_coder \
--speculative-algorithm NEXTN \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4 \
--mem-fraction-static 0.8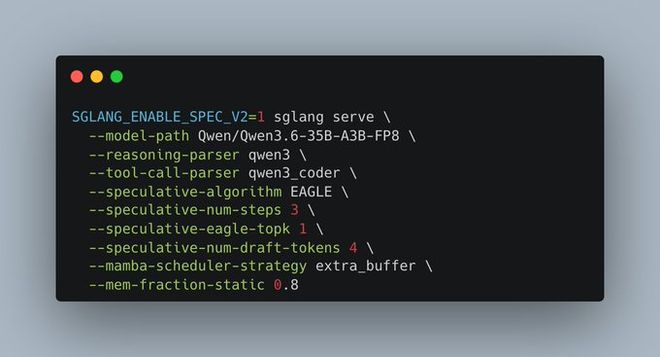
Flag cheat sheet
| Flag | Typical value | Role |
|---|---|---|
--speculative-algorithm | NEXTN | Use built-in Qwen3.6 MTP head |
--speculative-num-steps | 3 | Draft depth; higher = more aggressive |
--speculative-eagle-topk | 1 | Branching factor for draft candidates |
--speculative-num-draft-tokens | 4 | Max draft tokens per verification round |
--reasoning-parser | qwen3 | Split thinking vs answer for hybrid reasoning |
Tuning Recipes (Latency vs Throughput)
Think in terms of batch size and acceptance rate:
| Profile | Steps | Draft tokens | Best for |
|---|---|---|---|
| Low latency | 3 | 4 | Single-user chat, coding agents (bs=1) |
| Balanced | 1 | 2 | Small multi-user or moderate batch |
| Max throughput | off | — | Saturated server where verify cost dominates |
If acceptance is low (random or highly creative text), MTP adds verify overhead without much gain—turn it off for that workload.
When Not to Use MTP
- VRAM is already tight: Draft buffers need headroom; prefer FP8 or lower
--mem-fraction-staticfirst. - Very long context at high batch: Verify passes scale with running requests; profile before enabling aggressive steps.
- llama.cpp / GGUF local runs: MTP/NEXTN is a server-side SGLang (or vLLM) feature today; Unsloth GGUF paths in our deployment guide do not expose the same MTP switch.
- You forgot
SGLANG_ENABLE_SPEC_V2: Fix the env var before chasing OOM errors.
vLLM and Other Engines
vLLM has been adding MTP-style speculative decoding for Qwen-family models via JSON config (e.g. method: mtp, num_speculative_tokens: 2). Ecosystem support moves quickly—check the vLLM release notes for your exact Qwen3.6 checkpoint before production.
For day-zero Qwen3.6 features (thinking parser, tool calls, NEXTN), SGLang remains the reference path in May 2026.
Quick Checklist
- Deploy Qwen3.6-35B-A3B with enough TP / FP8 headroom.
- Export
SGLANG_ENABLE_SPEC_V2=1. - Add
--speculative-algorithm NEXTNand start with steps=3, draft-tokens=4. - Benchmark tokens/s at batch size 1 with thinking on/off.
- If VRAM spikes, reduce draft tokens or disable MTP before reducing context.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google