With just an Image Tokenizer, Llama can also perform image generation, and its results surpass those of diffusion models.
Researchers from the University of Hong Kong and ByteDance have proposed an image generation method based on the autoregressive model Llama.
The model has already been open-sourced and has garnered nearly 900 stars on GitHub.
After the emergence of diffusion models, they replaced autoregressive methods and became the mainstream technical approach for image generation for a time.
However, on the ImageNet benchmark, LlamaGen proposed by the authors outperforms diffusion models such as LDM and DiT.
This finding proves that the most primitive autoregressive model architecture can also achieve highly competitive image generation performance.

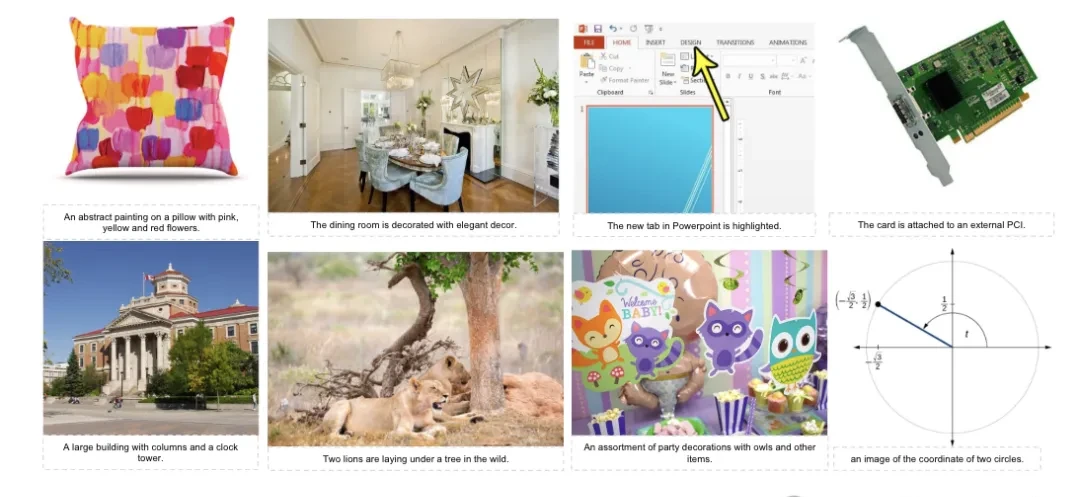
△ LlamaGen image generation examples: the first row shows class-conditioned generation, and the second row shows text-to-image generation.
So, how is image generation based on autoregressive models, or specifically based on Llama, achieved?
Image Generation Using Autoregressive Models
The authors note that the open-source community’s impression of using autoregressive models for image generation largely remains at the FID score of around 15 achieved by VQ-GAN on the ImageNet benchmark in 2020.
However, ViT-VQGAN had already reached an FID of approximately 3.0 as early as 2021, and models like DALL-E 1 and Parti demonstrated significant potential in text-to-image generation.
Since these works were not open-sourced, the research team set its goal to release an open-source version of a base autoregressive image generation model.
Regarding existing advanced image generation models, the authors summarize three key design elements for their success:
- Image Compressors/Tokenizers
- Scalable Image Generation Models
- High-Quality Training Data
Consequently, the authors adopted the same CNN architecture as VQ-GAN to convert continuous images into discrete tokens.
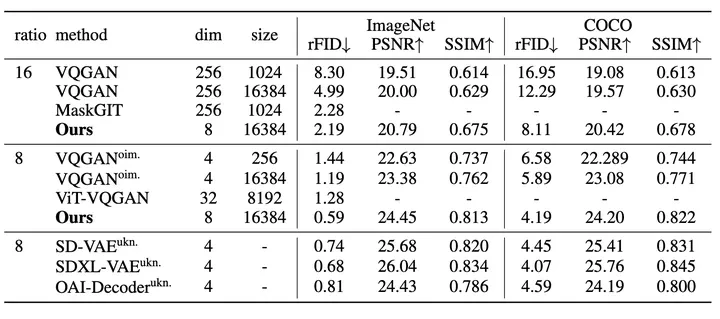
Compared to the 2020 VQ-GAN, the authors have gained deeper insights into the Image Tokenizer:
An excellent tokenizer requires a larger codebook size and lower codebook vector dimension. Meanwhile, better image reconstruction necessitates a greater number of tokens.
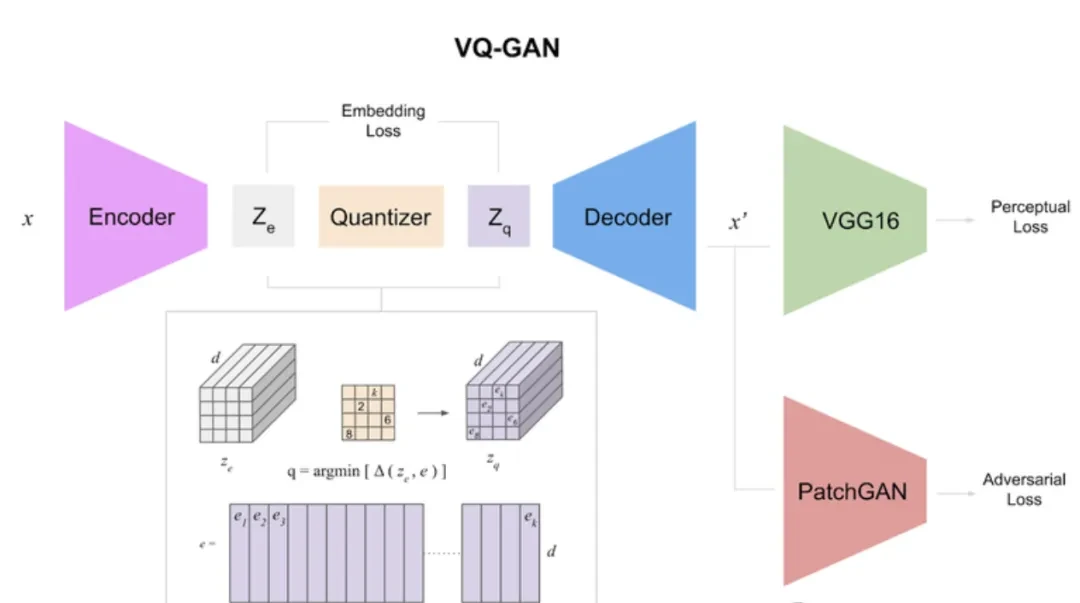
△ VQ-GAN architecture (not part of this project).
In terms of architecture, LlamaGen is primarily based on the Llama language model, incorporating Pre-Normalization using RMSNorm, SwiGLU, and RoPE.
Although some commonly used techniques in image generation (such as AdaLN) could potentially further improve performance, the authors kept the architecture identical to that of the Llama language model as much as possible.
For class-conditional and text-conditional (text-to-image) models, the authors adopted a simple implementation:
Class or text embeddings are used directly as starting tokens, with subsequent image tokens generated using the next-token prediction paradigm.
The training process is divided into two stages.
In the first stage, the model is trained on a 50-million subset of LAION-COCO, with an image resolution of 256×256.
The original LAION-COCO dataset contains 600 million image-text pairs. The authors filtered these images using effective image URLs, aesthetic scores, watermark scores, CLIP text-image similarity scores, and image size.
In the second stage, the model is fine-tuned on 10 million internal high-aesthetic-quality images, with an image resolution of 512×512.
The text descriptions for these aesthetic images were generated by LLaVA.

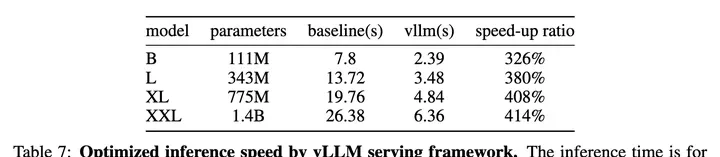
During the deployment phase, image generation models based on native autoregressive architectures can seamlessly utilize existing LLM deployment frameworks, such as vLLM. This is a major advantage of unified model architectures.
Furthermore, deployment via the vLLM framework provides LlamaGen with a 326%-414% speedup.
Performance Comparable to Diffusion Models
So, how does the model developed by the authors actually perform?
First, the retrained Image Tokenizer outperforms previous tokenizers on ImageNet and COCO, including VQGAN, ViT-VQGAN, and MaskGIT.
Importantly, the tokenizer based on discrete representations performs on par with those based on continuous representations (such as the SD VAE widely used in diffusion models), indicating that discrete representations for image quantization are no longer a major bottleneck for image reconstruction.
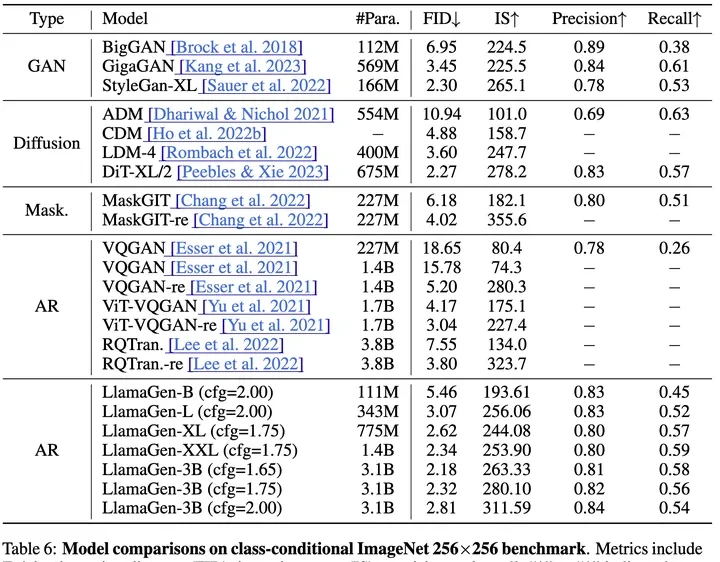
In actual generation, on the ImageNet test set, LlamaGen demonstrated strong competitiveness across metrics such as FID, IS, Precision, and Recall.
Notably, the LlamaGen-3B model outperforms popular diffusion models like LDM and DiT. This suggests that even the most basic autoregressive model architecture has the potential to serve as a foundation for advanced image generation systems.
Additionally, compared to previous autoregressive models, LlamaGen surpasses earlier models across various parameter scales.
The authors attribute this success to the improved Image Tokenizer and the better scalability of the Llama architecture.
In text-to-image generation, after the first stage of training, the model essentially possesses image-text alignment capabilities, but the visual quality of the generated images needs improvement.
The second stage of training significantly enhanced the visual quality of the generated images. The authors believe this improvement stems from two aspects:
- The second stage used high-quality aesthetic images;
- The image resolution in the first stage was 256×256, while in the second stage it was 512×512. Higher image resolutions lead to better visual effects.

When provided with longer text inputs, LlamaGen can also generate images that combine both image-text alignment and high visual quality.
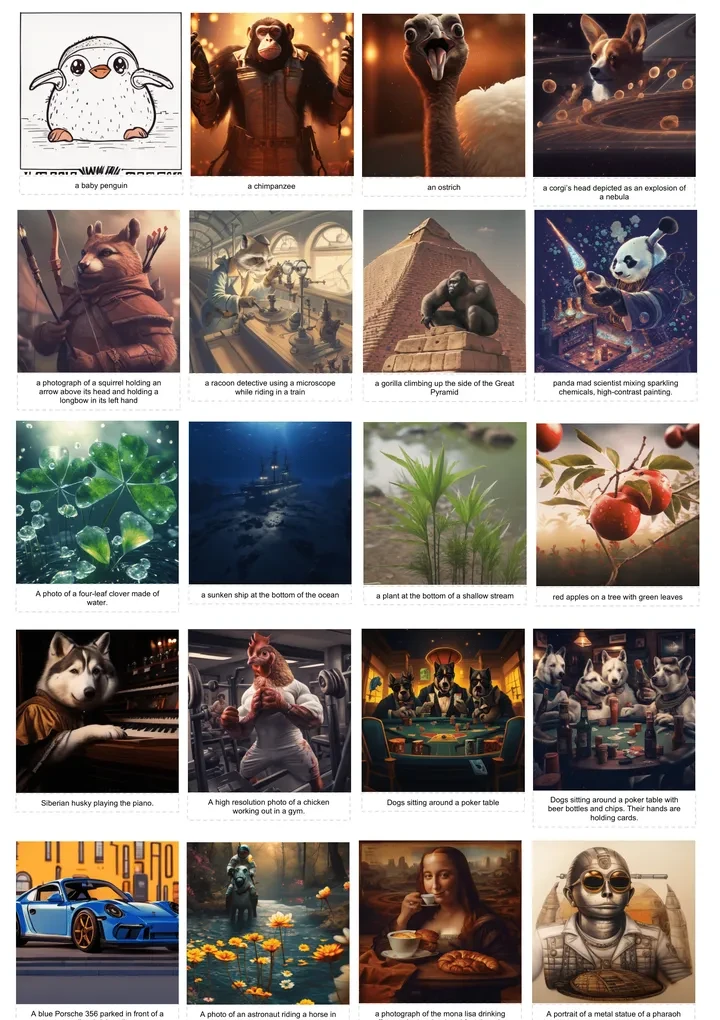
However, the authors acknowledge that if compared to the development trajectory of diffusion models, current LlamaGen is only at the stage equivalent to Stable Diffusion v1. Future improvement directions include SDXL (higher resolution, more aspect ratios), ControlNet (greater controllability), and Sora (video generation).
From the perspective of multimodal large models, it has been proven feasible for autoregressive models to handle both understanding and generation tasks separately. The next step is joint training within a single model.
The project is currently open-sourced and supports online demos. Interested parties are encouraged to try it out.
Online Demo:
https://huggingface.co/spaces/FoundationVision/LlamaGen
Paper:
https://arxiv.org/abs/2406.06525
Project Homepage:
https://peizesun.github.io/llamagen/
GitHub:
https://github.com/FoundationVision/LlamaGen
Hugging Face:
https://huggingface.co/FoundationVision/LlamaGen
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google