The creative stack just got another layer of friction—and opportunity. When an enterprise like SenseTime open-sources a model that claims to outperform proprietary giants in complex visual reasoning, it shifts power from platform walled gardens back toward developers who can actually tweak the pipeline. This isn’t just about better scores; it’s about whether creators can trust these tools with their intellectual property when the underlying architecture is fully exposed.
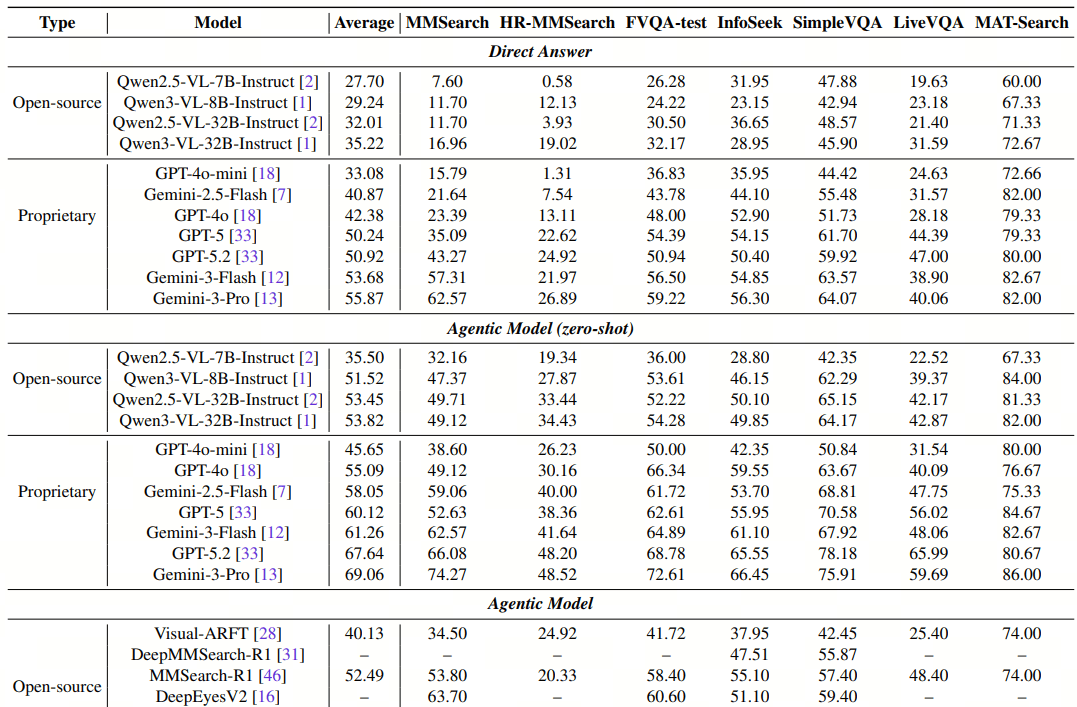
Today, SenseTime officially open-sourced its multimodal autonomous reasoning model, SenseNova-MARS (available in 8B and 32B versions). In core benchmarks for multimodal search and reasoning, it achieved a score of 69.74, surpassing Gemini-3-Pro (69.06) and GPT-5.2 (67.64).
SenseNova-MARS is the first Agentic VLM model to support dynamic visual reasoning and deep integration with image-text search. It can autonomously plan steps and invoke tools, effortlessly handling various complex tasks and endowing AI with true “execution capabilities.”
In benchmarks such as MMSearch, HR-MMSearch, FVQA, InfoSeek, SimpleVQA, and LiveVQA, SenseNova-MARS achieved State-of-the-Art (SOTA) results among open-source models, outperforming top closed-source models like Gemini-3.0-Pro and GPT-5.2. It leads comprehensively in two core areas: search reasoning and visual understanding. For more details, please refer to the technical report (https://arxiv.org/abs/2512.24330). Developers and users from all industries are welcome to test and experience the model.
An All-Around Champion: Autonomously Solving Complex Problems
SenseNova-MARS demonstrates a clear leading advantage in multiple multimodal search evaluations, achieving an average score of 69.74. This successfully surpasses Gemini-3-Pro’s 69.06 and GPT-5.2’s 67.64.
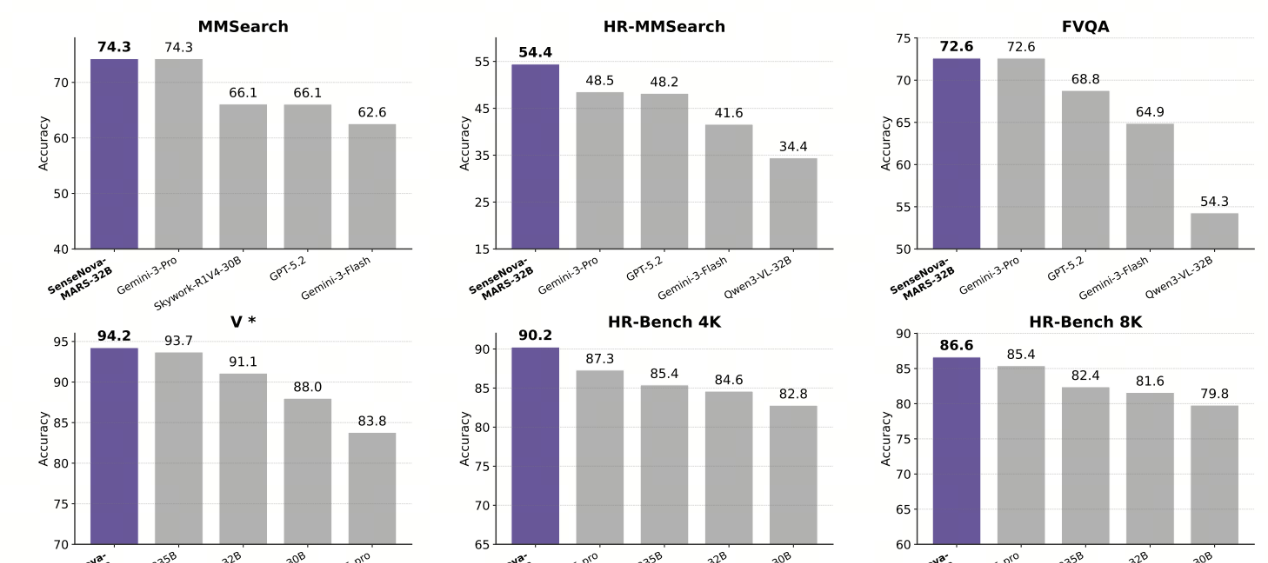
On the MMSearch leaderboard (the core evaluation for image-text search), the model topped the charts with a score of 74.27, exceeding GPT-5.2’s 66.08. In HR-MMSearch (high-definition detail search evaluation), it led with 54.43 points, significantly widening the gap with closed-source models.
The test questions for HR-MMSearch are akin to the “Olympics of the AI world”: they utilize 305 brand-new 4K ultra-high-definition images from 2025, ensuring that AI cannot rely on outdated knowledge to “cheat.” All questions target details occupying less than 5% of the image, such as small logos, tiny text, or minute objects, which require image cropping tools to see clearly. The tests cover eight major fields: sports, entertainment and culture, science and technology, business and finance, gaming, academic research, geography and travel, with 60% of questions requiring at least three different tools to answer.
In short, whether it is a knowledge-intensive task that requires “searching the entire web” or a fine-grained visual analysis demanding “sharp eyes,” SenseNova-MARS is currently the “all-around champion.”
Orchestrating Tools for Complex Queries
The real value here isn’t just seeing; it’s doing. SenseNova-MARS tackles scenarios that demand “multi-step reasoning + multi-tool collaboration,” a gap where traditional AI often stalls because they are forced to choose between text search or image viewing, not both simultaneously. When a task requires zooming in on details, identifying objects, and then checking background info, these models usually hit a wall.

I followed the release notes closely: the model autonomously invokes image cropping and text/image search tools to complete closed-loop solutions without human intervention. Take a complex query like identifying a tiny logo on racing gear, querying the company’s founding year, matching the driver’s birth date, and calculating the difference. SenseNova-MARS handles this chain of operations independently.
I think automated tool chaining reduces manual copy-pasting for researchers. For creators, creators lose control when AI autonomously crops their images without consent.

In practical applications, the model identifies corporate logos from photos of products or industry summits. It quickly gathers information about companies, including time, quantity, and parameters, which assists in analyzing industry conditions. This moves beyond simple recognition into active data synthesis for business intelligence.
On licensing, commercial use of cropped assets raises immediate licensing questions. I think workflow friction increases if models hallucinate tool outputs during search.

From race photos, it identifies logos, people, and other in-frame information to trace background details about the competition or personnel. This helps quickly supplement important context that might otherwise require hours of manual digging. The ability to handle ultra-long-step multimodal reasoning tasks involving more than three tool invocations is particularly notable.

The system automatically crops and analyzes details, searches for relevant research data, validates hypotheses, and draws key conclusions. With this “autonomous thinking + multi-tool collaboration,” it solves complex tasks involving detail recognition, information retrieval, and logical reasoning to improve work efficiency. The specific capabilities include:
- Image Cropping: Precisely focuses on minute details in images. Even details occupying less than 5%—such as a tiny logo on a racer’s suit or slogans in the stands of race photos—can be clearly analyzed by cropping and zooming in.
- Image Search: Automatically matches relevant information the moment it sees an object, person, or scene—for example, identifying a racer’s identity or the model number of a niche device.
- Text Search: Quickly captures precise information. Whether it is a company’s founding year, a person’s birth date, or the latest industry data, it can be retrieved in seconds.
Building Intuition Through Rigorous Training
SenseTime’s SenseNova-MARS doesn’t just learn; it practices. The team calls their approach “teaching according to aptitude,” a method designed to solve the chronic shortage of high-quality training data for cross-modal, multi-hop search reasoning. I followed the release notes closely, and what stood out was their move away from passive learning toward active, agent-driven synthesis.
Phase 1: Building Foundations with Synthetic Hard Cases
The core innovation here is an automated data synthesis engine powered by multimodal agents. Instead of scraping generic web data, SenseTime uses fine-grained visual anchors and multi-hop deep associative retrieval to dynamically mine logic across web entities. They construct high-complexity reasoning chains that mimic real-world detective work. Crucially, they introduce closed-loop self-consistency verification to scrub out hallucinated data. This ensures the resulting Q&A pairs have rigorous logical chains and high knowledge density.
The AI is taught using “high-difficulty cases” annotated with specific tool usage and steps. These are the “hard bones” picked from massive datasets, ensuring the model encounters complex scenarios immediately rather than starting with easy wins. It’s a curriculum designed to force the AI to learn basic detective logic before tackling broader tasks.
Phase 2: Reinforcement Learning with Stability Guards
Once the foundation is laid, SenseTime employs Reinforcement Learning (RL) to simulate experience accumulation. The AI receives rewards for correct decisions—such as choosing the right tool or step—and adjusts its strategy upon errors. However, RL in multi-tool agents often suffers from instability. To counter this, the research team integrated a “stabilizer” called the BN-GSPO algorithm.
This dual-stage normalization mechanism smooths out optimization fluctuations caused by diverse dynamic tool invocation return distributions. It ensures consistency in learning signal distribution, effectively solving convergence challenges that typically plague cross-modal multi-step agent training. The result is an AI that cultivates “tool-use intuition,” knowing not just which tools to use, but how to organically combine their results under varying circumstances.
For creators, open-sourcing the data means creators can audit for bias in those synthetic reasoning chains. On licensing, fine-grained visual anchors may raise the bar for image-based content provenance verification. I think complex multi-hop logic could disrupt workflows relying on simple, direct search results.
Full Open Source: Model, Code, and Data
SenseTime has fully open-sourced SenseNova-MARS, including the model weights, codebase, and datasets. This transparency allows the community to inspect the “intuition” building process directly. You can download everything via Hugging Face or clone the repository on GitHub.
GitHub Repository:
https://github.com/OpenSenseNova/SenseNova-MARS
Model Repositories:
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google