No H100s needed: Three Apple computers can power a 400B-parameter large language model.
The key behind this achievement is an open-source distributed AI inference framework on GitHub, which has already garnered 2.5k stars.
Using this framework, users can build their own AI computing clusters in minutes using everyday devices like iPhones and iPads.
The framework is named exo. Unlike other distributed inference frameworks, it employs a peer-to-peer (P2P) connection method, allowing devices to automatically join the cluster once connected to the network.
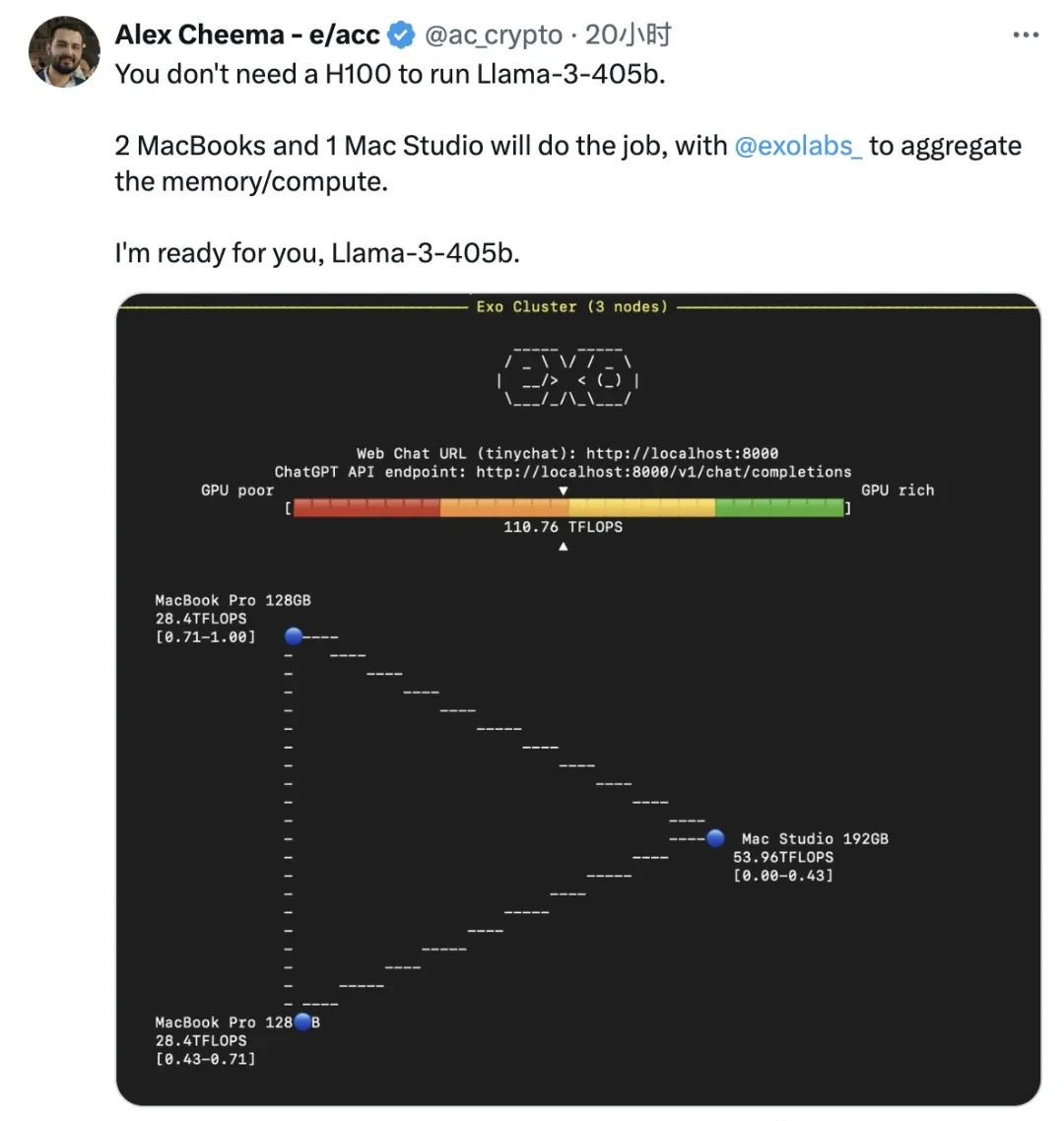
A developer used the exo framework to connect two MacBook Pros and one Mac Studio, achieving a computing speed of 110 TFLOPS.
The same developer stated that they are ready for the upcoming Llama-3-405B model.
The exo official team has also announced that support for Llama-3-405B will be provided on day zero (the first day of release).

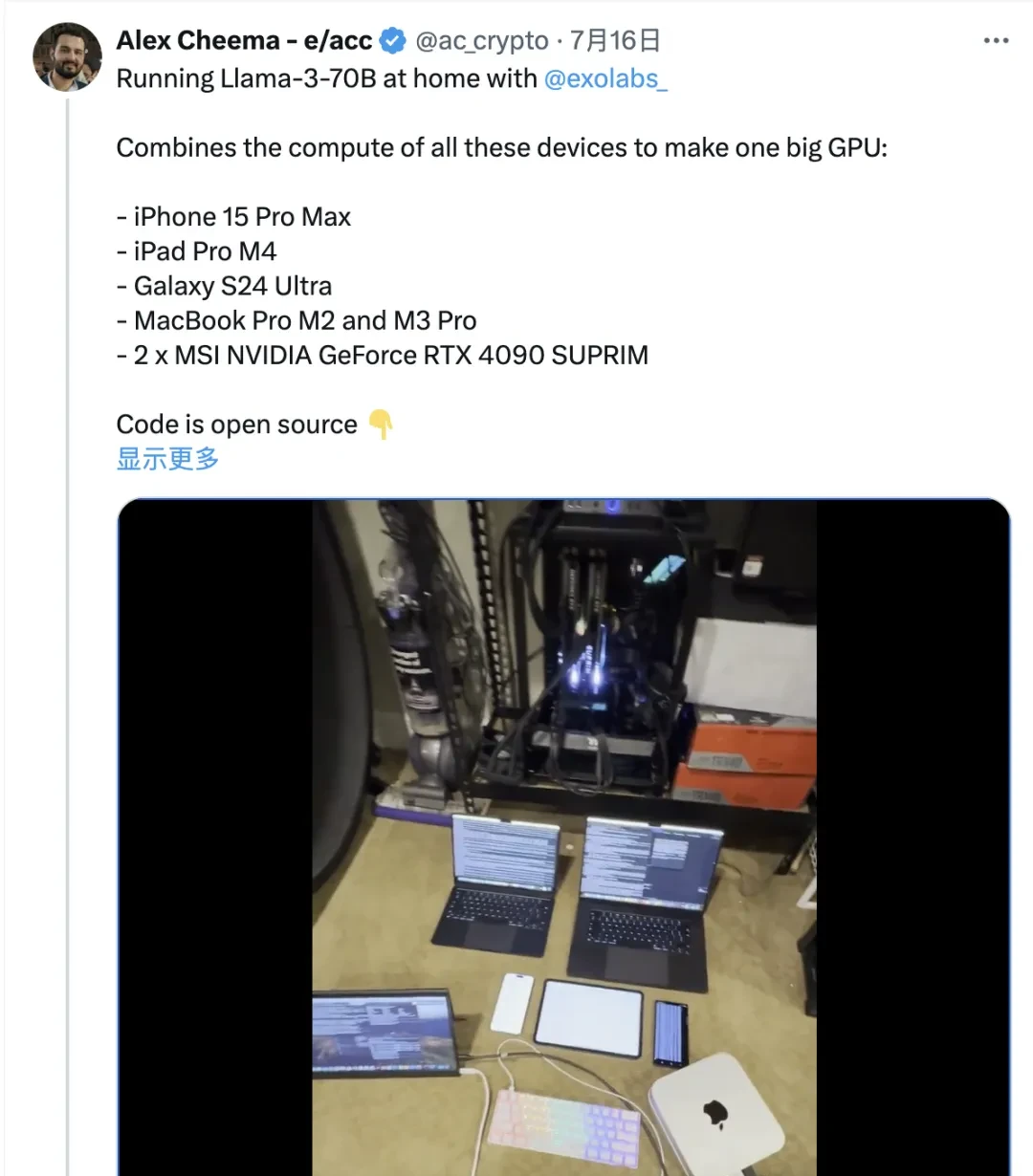
Moreover, it is not just computers; exo allows devices such as iPhones and iPads to join the local computing network, with even Apple Watches being capable of contributing.

With version iterations, the exo framework is no longer limited to Apple devices (initially supporting only MLX). Users have successfully integrated Android phones and RTX 4090 graphics cards into the cluster.
Configuration Completed in as Little as 60 Seconds
Unlike other distributed inference frameworks, exo does not use a master-worker architecture but instead connects devices via peer-to-peer (P2P) networking.
As long as devices are connected to the same local area network (LAN), they can automatically join exo’s computing network to run models.
When partitioning models across devices, exo supports different sharding strategies, with the default being ring memory-weighted partitioning.
This approach runs inference in a ring topology, where each device executes multiple model layers, with the specific number proportional to the device’s memory capacity.
Furthermore, the entire process requires almost no manual configuration. After installation and startup, the system automatically connects to devices running on the LAN, with Bluetooth connectivity planned for future updates.
In a video demonstration by the author, configuration was completed in about 60 seconds on two new MacBook Pros.
It can be seen that around the 60-second mark, the program had already begun running in the background.
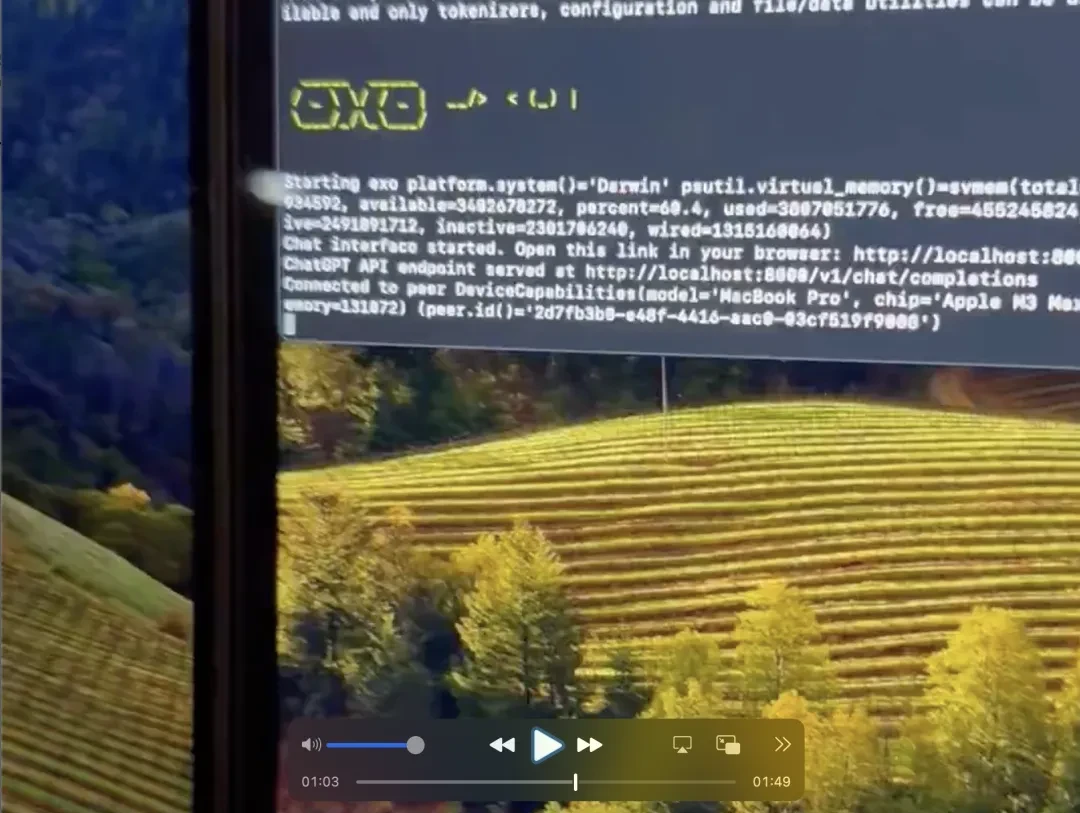
Additionally, from the image above, it is evident that exo supports a graphical user interface called Tiny Chat, as well as an API compatible with OpenAI.
However, such operations can only be performed on the tail node within the cluster.

Currently, exo supports Apple’s MLX framework and the open-source machine learning framework tinygrad. Adaptation for llama.cpp is also underway.
A drawback is that due to iOS implementation updates lagging behind Python, several issues have arisen with the mobile app. The author has temporarily taken down the iPhone and iPad versions of exo; those who wish to try it can contact the author via email.
Netizens: Is It Really That Useful?
The concept of running large language models on local devices sparked widespread discussion on Hacker News.
The advantages of localized operation include better privacy protection, offline access to models, and support for personalized customization.

Some pointed out that building a cluster using existing devices for large model computation has lower long-term costs compared to cloud services.

However, regarding the specific project exo, many expressed doubts.
First, some netizens noted that the computing power of existing older devices is orders of magnitude lower than that of professional service providers. While it might be fun for curiosity’s sake, achieving top-tier performance at a comparable cost to large platforms is impossible.

Others pointed out that the devices used in the author’s demonstration were high-end hardware. A Mac device with 32GB of memory might cost over $2,000, a price tag that could instead buy two RTX 3090 graphics cards.
They even argued that since Apple is involved, the term “affordable” hardly applies.

This raises another question: Which devices does the exo framework support? Is it exclusive to Apple?
Netizens asked more directly, inquiring about Raspberry Pi compatibility.
The author replied that theoretically, it is possible, though not yet tested; testing will be the next step.

Beyond the computing power of the devices themselves, some added that network transmission speed bottlenecks could also limit cluster performance.
The framework’s author personally addressed this concern:
The data transmitted within exo consists of small activation vectors, not entire model weights.
For the Llama-3-8B model, activation vectors are approximately 10KB; for Llama-3-70B, they are about 32KB.
Local network latency is typically very low (<5ms) and does not significantly impact performance.

The author stated that since the framework currently supports tinygrad, it theoretically supports all devices capable of running tinygrad, even though testing has primarily been conducted on Macs.
The framework is still in an experimental stage, with the future goal of making it as simple to use as Dropbox (a cloud storage service).

By the way, the exo official team has listed some current shortcomings they plan to address and has offered public bounties. Those who resolve these issues will receive rewards ranging from $100 to $500.

Comments
Sign in to join the discussion and leave a comment.
Sign in with Google