Transformers are powerful and effective, yet they exhibit certain limitations when processing time series data. Issues such as high computational complexity and inefficiency in handling long sequences remain significant challenges.
In this era of data-driven decision-making, time series forecasting has become an indispensable component across numerous fields.
To address these challenges, Ant Group and Tsinghua University have jointly introduced TimeMixer, a pure MLP (Multi-Layer Perceptron) architecture model that comprehensively outperforms Transformer models in both performance and efficiency for time series forecasting.

By combining the decomposition of temporal trends and periodic characteristics with a multi-scale hybrid design, the model not only significantly enhances forecasting performance for both short- and long-term horizons but also achieves near-linear efficiency through its pure MLP architecture.
How did they achieve this?
Pure MLP Architecture Outperforms Transformers
The TimeMixer model employs a multi-scale hybrid architecture designed to address complex temporal variations in time series forecasting.
Primarily built on a fully MLP (Multi-Layer Perceptron) architecture, the model consists of two main components: Past Decomposable Mixing (PDM), which handles decomposable mixing from past data, and Future Multipredictor Mixing (FMM), which manages future multi-predictor mixing. This structure effectively leverages multi-scale sequence information.
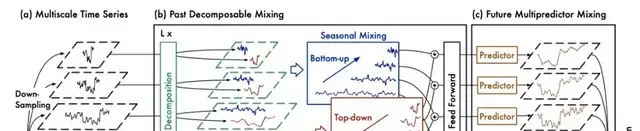
The PDM module is responsible for extracting historical information and separately mixing seasonal and trend components across different scales.
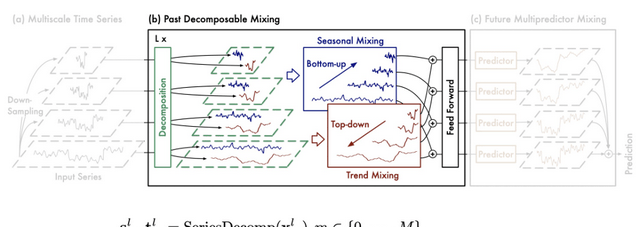
Driven by seasonal and trend mixing, PDM progressively aggregates detailed seasonal information from fine to coarse scales. It utilizes prior knowledge at coarser scales to deeply mine macroscopic trend information, ultimately achieving multi-scale mixing in the extraction of past information.
FMM is a collection of multiple predictors. Each predictor operates based on past information at different scales, enabling FMM to integrate complementary forecasting functions from mixed multi-scale sequences.

Experimental Results
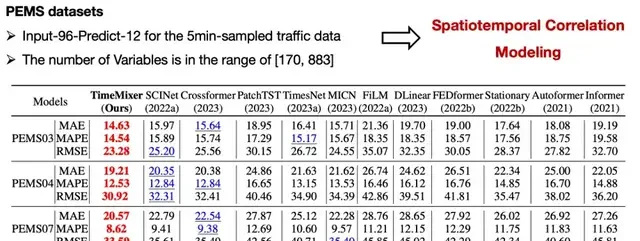
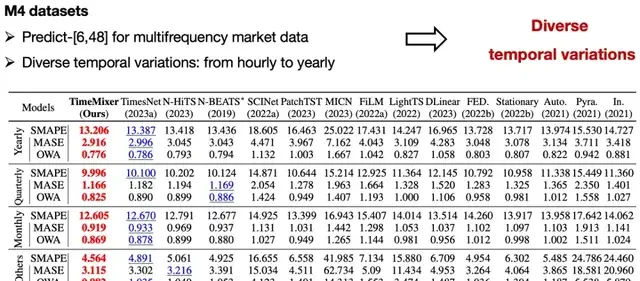
To validate the performance of TimeMixer, the team conducted experiments on 18 benchmark datasets covering long-term forecasting, short-term forecasting, multivariate time series forecasting, and spatiotemporal graph structures. These datasets include applications such as power load forecasting, meteorological data prediction, and stock price forecasting.
Experimental results indicate that TimeMixer comprehensively outperforms current state-of-the-art Transformer models across multiple metrics:
Forecasting Accuracy: On all tested datasets, TimeMixer demonstrated higher forecasting accuracy. For instance, in power load forecasting, TimeMixer reduced the Mean Absolute Error (MAE) by approximately 15% and the Root Mean Square Error (RMSE) by about 12% compared to Transformer models.
Computational Efficiency: Benefiting from the efficient computational characteristics of MLP structures, TimeMixer significantly outperforms Transformer models in both training and inference times. Experimental data shows that under identical hardware conditions, TimeMixer reduced training time by approximately 30% and inference time by about 25%.
Model Interpretability: By introducing Past Decomposable Mixing and Future Multipredictor Mixing techniques, TimeMixer better explains the contribution of information across different temporal scales, making the model’s decision-making process more transparent and easier to understand.
Generalization Ability: Tested on various types of datasets, TimeMixer exhibited strong generalization capabilities, adapting well to different data distributions and features. This suggests broad applicability in practical scenarios.
Long-Term Forecasting: To ensure fair comparison, experiments were conducted using standardized parameters, adjusting input lengths, batch sizes, and training epochs. Additionally, given that many research results stem from hyperparameter optimization, this study also includes results from comprehensive parameter searches.

Short-Term Forecasting: Multivariate Data
Short-Term Forecasting: Univariate Data
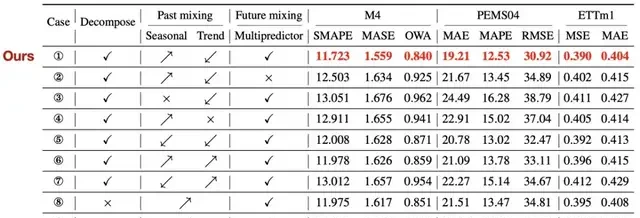
Ablation Studies: To verify the effectiveness of each component in TimeMixer, detailed ablation studies were conducted on all 18 experimental benchmarks, examining every possible design variation within the Past-Decomposable-Mixing and Future-Multipredictor-Mixing modules.
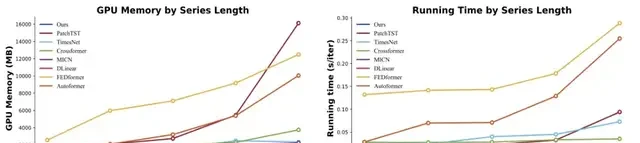
Model Efficiency: The team compared the runtime memory and time during the training phase with state-of-the-art models. TimeMixer consistently demonstrated excellent efficiency in terms of GPU memory usage and runtime across various sequence lengths (ranging from 192 to 3072), while maintaining consistent state-of-the-art performance for both long-term and short-term forecasting tasks.
Notably, as a deep learning model, TimeMixer exhibits efficiency results comparable to fully linear models. This positions TimeMixer as a promising solution in scenarios requiring high model efficiency.
In summary, TimeMixer brings new perspectives to the field of time series forecasting and demonstrates the potential of pure MLP structures in complex tasks.
Looking ahead, with the introduction of more optimization techniques and application scenarios, it is believed that TimeMixer will further drive the development of time series forecasting technology, delivering greater value across various industries.
This project was supported by NextEvo, the AI innovation R&D department under Ant Group’s Intelligent Engine Division.
Ant Group’s NextEvo Optimization Intelligence Team focuses on intelligent decision-making technologies that combine operations research optimization, time series forecasting, and predictive optimization. The team’s work covers the R&D of algorithmic technologies, platform services, and solutions.
Paper Link:
https://arxiv.org/abs/2405.14616v1
Code Repository:
https://github.com/kwuking/TimeMixer
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google