Vision-language models (such as GPT-4o and DALL-E 3) typically possess billions of parameters, and their model weights are not publicly available. This makes traditional white-box optimization methods, such as backpropagation, difficult to implement.
So, is there a more streamlined optimization method?
Recently, a research team from Carnegie Mellon University (CMU) proposed an innovative “black-box optimization” strategy to address this issue:
By using large language models (LLMs) to automatically adjust natural language prompts, they enabled vision-language models to achieve better performance in downstream tasks such as text-to-image generation and visual recognition.
This method not only avoids accessing internal model parameters but also significantly enhances the flexibility and speed of optimization, allowing users without technical backgrounds to easily improve model performance.
The research has been accepted by CVPR 2024.

How Does It Work?
Most vision-language models (such as DALL-E 3 and GPT-4o) do not release their model weights or feature embeddings, rendering traditional optimization methods that rely on backpropagation inapplicable.
However, these models typically provide users with natural language interfaces, making it possible to improve model performance by optimizing prompts.
Nevertheless, traditional prompt engineering relies heavily on the experience and prior knowledge of engineers.
For example, to enhance the visual recognition capabilities of the CLIP model, OpenAI spent a year collecting dozens of effective prompt templates (such as “A good photo of a [class]”).
Similarly, when using text-to-image models like DALL-E 3 and Stable Diffusion, users often need to master numerous prompting techniques to generate satisfactory results.
So, is there an alternative to human prompt engineers?
Yes. The CMU team proposed a new strategy: using large language models like ChatGPT to automatically optimize prompts.
Just as prompt engineers refine prompts based on feedback, the CMU method leverages positive and negative feedback from ChatGPT to adjust prompts more efficiently. The specific process is illustrated below:
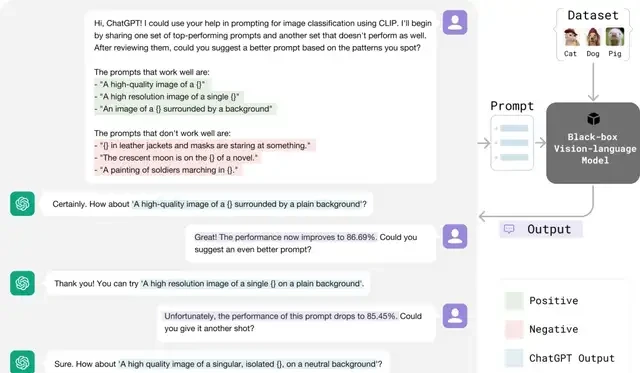
This optimization process is similar to the “hill-climbing” strategy in machine learning. The difference lies in the fact that large language models can automatically analyze prompt performance and identify the optimal direction for improvement based on positive and negative feedback.
The research team utilized this characteristic to optimize prompts more efficiently. This process can be summarized in the following steps:

- Prompt Initialization: Collect a batch of unoptimized initial prompts.
- Prompt Ranking: Score the performance of current prompts, retaining high-scoring ones and replacing low-scoring ones.
- Generate New Prompts: Use large language models to generate new candidate prompts based on the performance of existing ones.
After multiple iterations, the prompt with the highest score is returned as the optimized result.
Experimental Results
Through this method, the CMU team achieved state-of-the-art accuracy across several few-shot visual recognition datasets without human prompt engineers, even outperforming traditional white-box prompt optimization methods (such as CoOp).
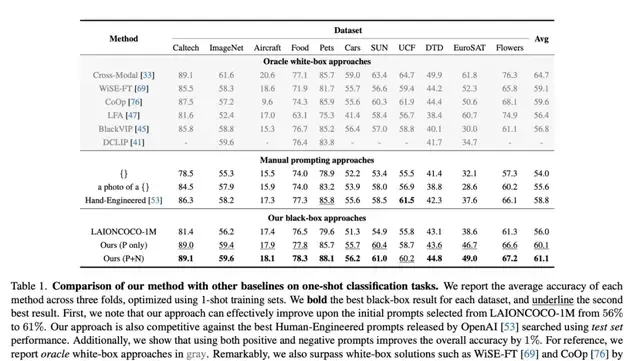
Furthermore, without needing to understand the dataset content, this method automatically captured visual characteristics of downstream tasks and incorporated them into prompts, yielding better results.
For instance, in food recognition tasks, ChatGPT automatically adjusted the prompt to focus on recognizing “diverse cuisines and ingredients,” thereby enhancing model performance.

The research team also demonstrated that prompts optimized via ChatGPT black-box optimization are not only applicable to single model architectures but can also generalize across different architectures (such as ResNet and ViT), outperforming white-box optimized prompts on various models.

These experiments prove that large language models can extract implicit “gradient” directions from prompt performance feedback, enabling model optimization without backpropagation.
Application in Text-to-Image Tasks
The CMU team further explored the potential of this method in generative tasks.
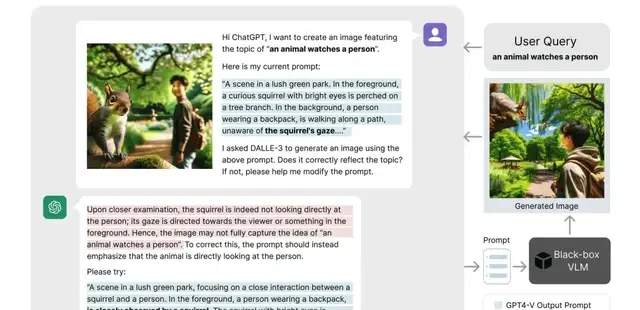
In text-to-image (T2I) generation tasks, ChatGPT can automatically optimize prompts to generate high-quality images that better align with user needs.
For example, for an input description such as “an animal looking at a person,” the system can improve the accuracy of the generated image through iterative prompt optimization.
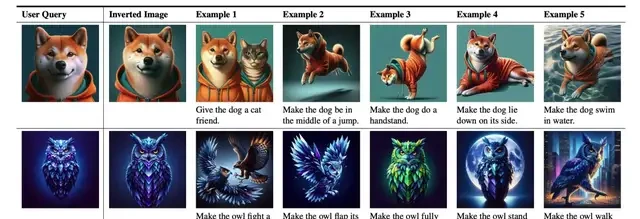
Additionally, this method is applicable to Prompt Inversion.
Prompt inversion is a technique that reverse-engineers the input prompts for generative models based on existing images. Simply put, it generates text descriptions (prompts) from an image that can reproduce its characteristics.
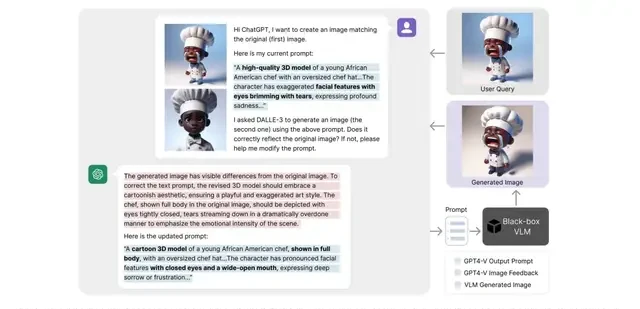
The research team tested this method on complex text-to-image tasks, and the results showed that it significantly improved user satisfaction with just three rounds of prompt optimization.

Furthermore, the team noted that prompt inversion can help users quickly customize specific image effects, such as “make this dog stand up” or “change the background to a night scene,” thereby generating images that meet specific requirements.
The CMU team stated that the proposed black-box optimization paradigm breaks through the limitations of traditional model tuning. It performs excellently in image classification and generation tasks and demonstrates broad application potential.
This method does not require access to model weights; it achieves precise optimization solely through “text gradients,” offering strong scalability.
In the future, black-box optimization is expected to be applied to complex dynamic scenarios such as real-time monitoring, autonomous driving, and smart healthcare, providing more flexible and efficient solutions for tuning multimodal models.
Team Introduction
The first author of the paper, Shihong Liu, is a graduate of Carnegie Mellon University and formerly a researcher at the Robotics Institute.
He currently works at Amazon in North America, where he is responsible for computing in large-scale distributed systems and the development of AI agents driven by large language models.

△ Shihong Liu
The co-first author, Zhiqiu Lin, is a doctoral student at Carnegie Mellon University, focusing on the automatic evaluation and optimization of vision-language large models.
Zhiqiu Lin has published over ten papers in top conferences such as CVPR, NeurIPS, ICML, and ECCV, and has received nominations for Best Paper Awards and Best Short Paper Awards.

△ Zhiqiu Lin
Professor Deva Ramanan is an internationally renowned scholar in the field of computer vision and currently serves as a professor at Carnegie Mellon University.

△ Professor Deva Ramanan
His research covers computer vision, machine learning, and artificial intelligence. He has received numerous top academic honors, including the David Marr Award in 2009, the PASCAL VOC Lifetime Achievement Award in 2010, the IEEE PAMI Young Researcher Award in 2012, recognition as one of “Ten Outstanding Scientists” by Popular Science in 2012, election as a Kavli Fellow of the U.S. National Academy of Sciences in 2013, the Longuet-Higgins Prize in both 2018 and 2024, and the Koenderink Award for his representative work (such as the COCO dataset).
Additionally, his papers have received multiple Best Paper nominations and honors at CVPR, ECCV, and ICCV. His research has had a profound impact on applications such as visual recognition, autonomous driving, and human-computer interaction, making him one of the most influential scientists in the field.
CVPR’24 Paper Link:
https://arxiv.org/abs/2309.05950
Paper Code:
https://github.com/shihongl1998/LLM-as-a-blackbox-optimizer
Project Website:
https://llm-can-optimize-vlm.github.io
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google