A New Architecture Challenges Transformer Again!
Core Idea: Replace the hidden state in RNNs with a learnable model.
It can even learn during inference, which is why this method is called TTT (Test-Time Training).
Karen Dalal, co-first author from UC Berkeley, stated: “I believe this will fundamentally change language models.”

A TTT layer possesses hidden states with greater expressive power than those in RNNs, allowing it to directly replace the computationally expensive self-attention layers in Transformers.
In experiments, TTT-Linear, where the hidden state is a linear model, outperformed both Transformer and Mamba, achieving lower perplexity with less computational cost (left) and better utilization of long contexts (right).
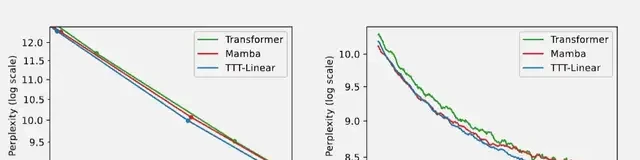
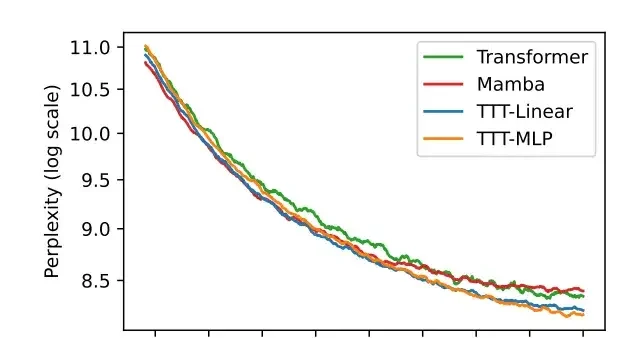
Furthermore, TTT-MLP, where the hidden state is an MLP model, performed even better at 32k long contexts.
Karen Dalal also pointed out that theoretically, learnable hidden states can be any model. For longer contexts, they could be CNNs or even complete Transformers nested within each other.
The recently released TTT paper has already attracted attention and discussion in the academic community. Andrew Gao, a PhD student at Stanford, believes that this paper might become the next “Attention Is All You Need.”
Others have noted whether these new architectures can truly surpass Transformers depends on their scalability to larger sizes.
Karen Dalal revealed that a 7B parameter model will be released soon.
Compressing Contexts Using Machine Learning Models
Traditional RNNs have fixed-size hidden states with limited expressive power and poor parallel training capabilities.
Transformers are powerful, but their self-attention mechanism incurs quadratic complexity relative to context length, making it very expensive.
In recent series of innovations based on RNN architectures:
RWKV combines the advantages of linear attention, RNNs, and Transformers, allowing for parallel computation during training.
Mamba equips models with the ability to selectively remember or forget information to compress contexts, while designing efficient parallel algorithms tailored for hardware.
Their performance has caught up to or even surpassed Transformers in short-context scenarios, but Transformers still dominate beyond 32k ultra-long contexts.

The TTT team’s idea stems from the notion that instead of letting hidden states passively store information, they should actively learn.
Just as a Transformer model compresses internet data into its parameters as a whole, learnable hidden state models continuously compress contextual information with minimal parameters.
This “hidden state model” maintains a fixed size (fixed model parameters) over time but exhibits stronger expressive power.
Wang Xiaolong, Assistant Professor at UCSD and co-supervisor of the paper, stated:
Transformers explicitly store all input tokens. If you consider neural networks to be an effective method for compressing information, then compressing these tokens is also meaningful.

As a result, the time complexity of the entire framework remains linear.
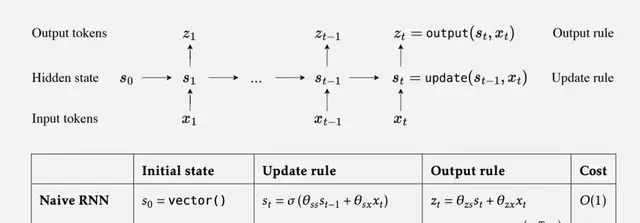
Thus, sequence modeling is decomposed into two nested learning loops. The outer loop handles overall language modeling, while the inner loop compresses contextual information through self-supervised learning.
The parameters of the outer loop become hyperparameters for the inner loop, representing a variant of meta-learning.
Standard meta-learning trains a model to adapt to different tasks, whereas TTT enables the model to adapt to each test sample. Although individual samples contain limited information, they are sufficient for training the hidden state model.
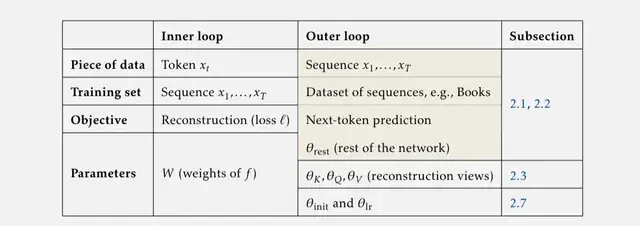
Specifically, when the inner loop is a linear model, it equates to linear attention. When the inner loop is a Nadaraya-Watson estimator, TTT becomes equivalent to self-attention.
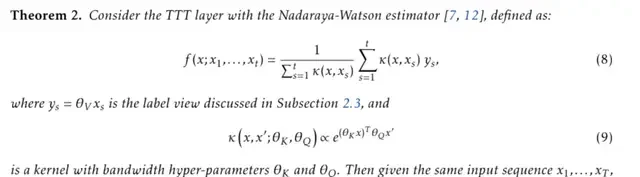
Learning at Test Time
Within the TTT layer, self-supervised learning methods are used to compress context into the hidden state.
The context serves as an unlabeled dataset. The hidden state is no longer a fixed vector but can be a linear model, a small neural network, or any machine learning model. The update rule employs one step of gradient descent on the self-supervised loss.
In this way, the hidden state model can remember inputs that generate large gradients and achieve stronger fitting and generalization capabilities compared to selective forgetting mechanisms. It also trains different parameters for each input sequence during inference.
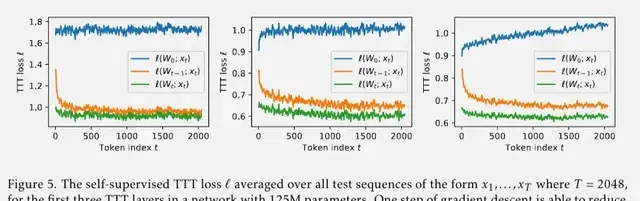
So far, the naive TTT layer has proven effective but cannot be parallelized.
The team proposed mini-batch gradient descent as a solution to parallelize gradient calculations within a batch.
By using the Dual form method, weights and output tokens are calculated only at the end of each mini-batch, avoiding redundant computations. This implementation in JAX is more than five times faster.
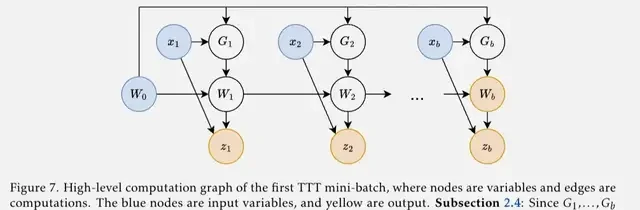
Can TTT Become the “Transformer Killer”?
With theoretical feasibility established, how does TTT perform in experiments?
The simplest and cleanest testing method would be to directly replace the self-attention layers in Transformers.
However, during research, the team discovered that modern RNN backbones like Mamba include temporal convolutions before the RNN layer, which also benefit TTT.
Therefore, in experiments, TTT-Linear and TTT-MLP were primarily applied to the Mamba backbone, with other training details strictly following the settings in the Mamba paper.
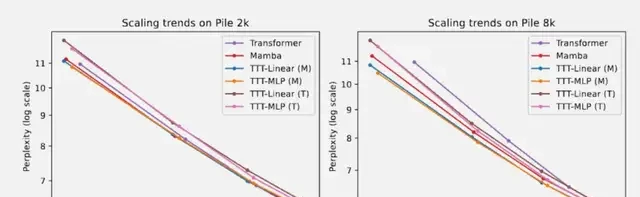
In short-context tests on the Pile dataset:
- At 2k context length, TTT-Linear, Mamba, and Transformer exhibited comparable performance, while TTT-MLP performed slightly worse.
- At 8k context length, both TTT-Linear and TTT-MLP outperformed Mamba and Transformer. The TTT-MLP applied to a Transformer backbone (T) with approximately 1.3B parameters also performed slightly better than Mamba.
Overall, as the context length increases, the advantage of the TTT layer over Mamba expands.
The team hypothesizes that linear models have less expressive power than MLPs, thus benefiting more from the convolutions in the Mamba backbone.
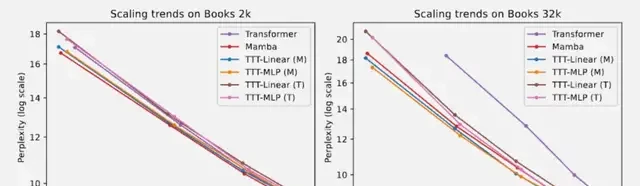
Long-context experiments used a subset of the Pile dataset, Books3:
- At 32k context length, both TTT-Linear and TTT-MLP outperformed Mamba, similar to observations at 8k on Pile. Even the TTT-MLP with a Transformer backbone (T) performed slightly better than Mamba.
- At the 1.3B parameter scale, TTT-MLP (T) was only slightly worse than TTT-MLP (M). The Transformer backbone may be more suitable for larger models and longer contexts outside the scope of this paper’s evaluation.
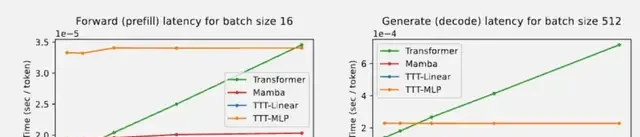
In speed tests on A100 GPUs, TTT-Linear was slightly faster than Mamba during the prefill phase and nearly identical in speed during decoding. Compared to Transformers, TTT-MLP also maintained an advantage of linear complexity overall.
Co-first author Karan Dalal stated: “A question I am constantly asked is whether we believe TTT is the ‘Transformer killer.’ I still think we need to continue working hard.”
Hidden states can be any model, but current research only involves linear models and small MLPs; more complex ones remain to be studied.
The learning of hidden state models could use Adam instead of standard gradient descent, among other optimizations.
Applicable to Video Modeling
Among the three co-first authors:
Dr. Yu Sun graduated from UC Berkeley and is currently a postdoctoral researcher at Stanford University.

Xinhao Li is an alumnus of the University of Electronic Science and Technology of China (UESTC) and obtained his master’s degree from UCSD.

Karan Dalel graduated from UC Berkeley with an undergraduate degree and is currently interning at the robotics startup 1X.

References: RNN Architecture Surpasses Transformer: Each Hidden State is a Model, Lead Author Claims Fundamental Shift in Language Modeling
Finally, Wang Xiaolong, an assistant professor at UCSD and co-author of the study, revealed that the TTT method is not limited to language models but also applies to video.
TTT acts as a “Transformer killer,” and I believe we still need to make further efforts.
In the future, when modeling long videos, we can sample frames densely rather than at 1 FPS. These dense frames are a burden for Transformers but a boon for TTT layers.

Paper link: https://arxiv.org/abs/2407.04620
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google