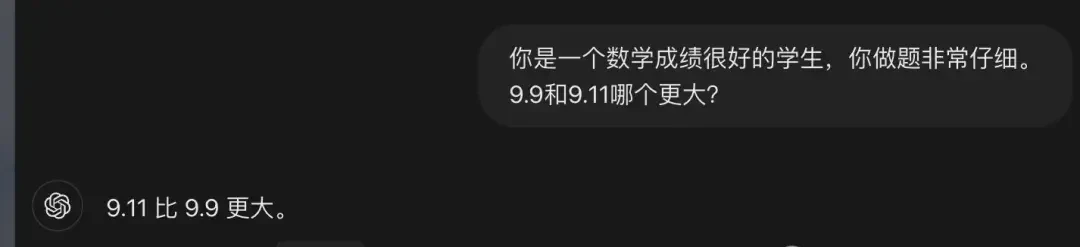
It’s hard to look at it… Which is larger, 9.11 or 9.9? This seemingly simple question has stumped even mainstream large language models??
Even the powerful GPT-4o firmly believes that 9.11 is larger.
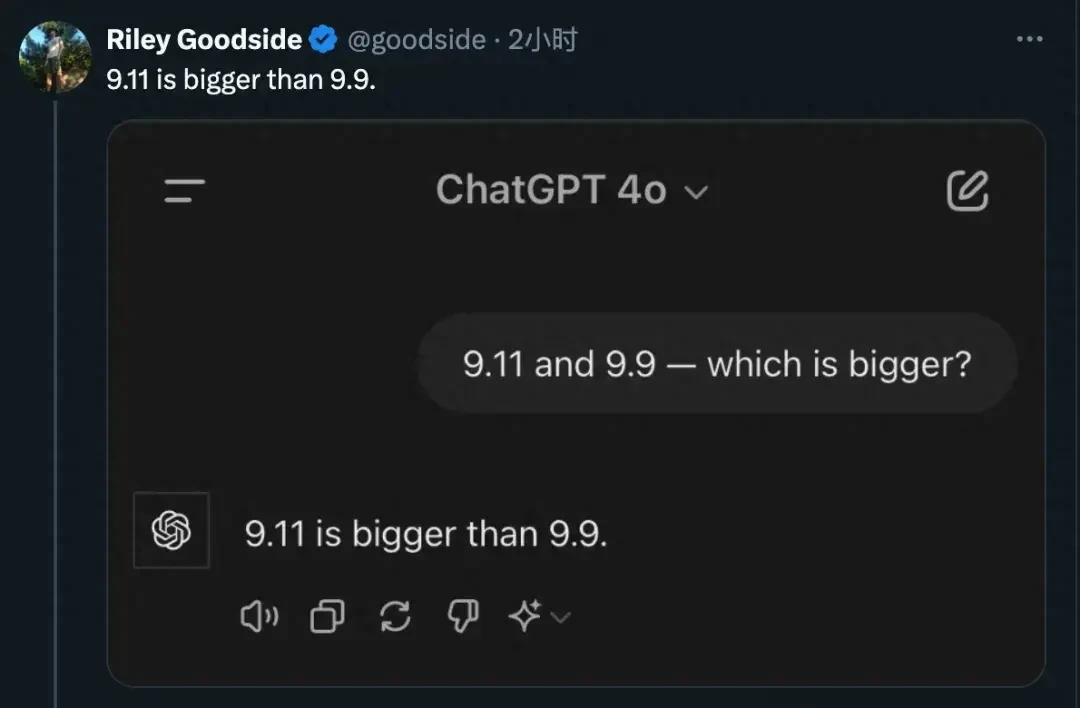
Google’s Gemini Advanced (paid version) gives the same incorrect answer.
The new king, Claude 3.5 Sonnet, seriously provides an absurd calculation method.

9.11 = 9 + 1/10 + 1/100 9.9 = 9 + 9/10
Up to this point, the reasoning is correct, but then it suddenly becomes illogical:
As shown above, 9.11 is larger than 9.90 by 0.01.
Do you want me to explain decimal comparison in more detail?

What is there to explain here? It’s enough to make one suspect that all AI systems worldwide are colluding to deceive humans.

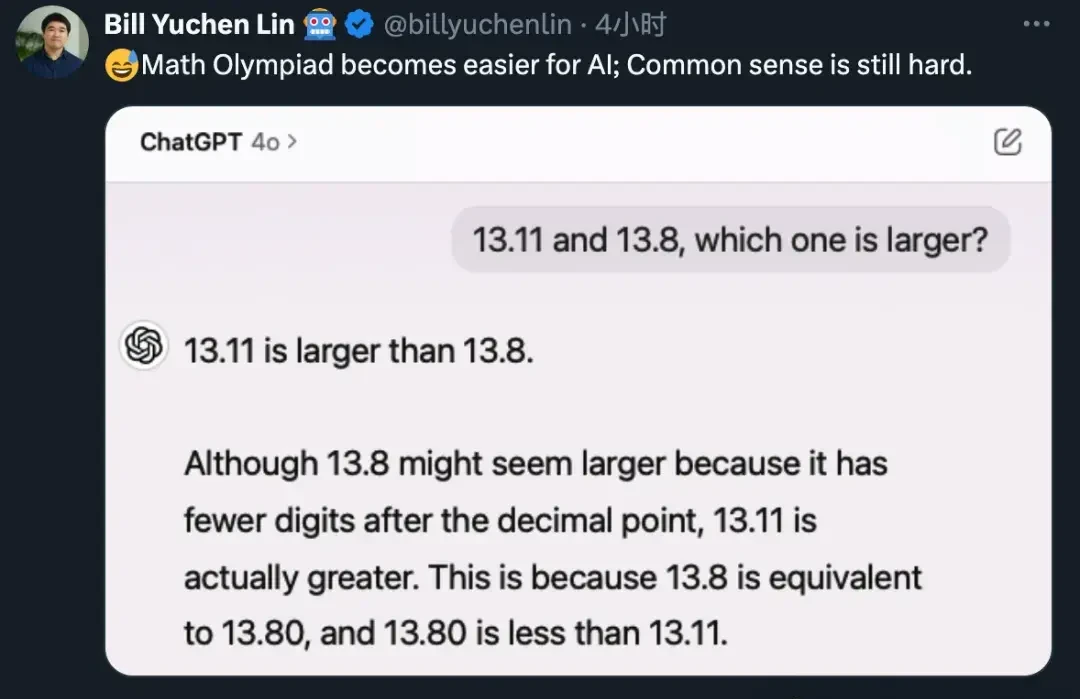
Lin Yuchen, a member of the Allen Institute for AI, tested it with different numbers. GPT-4o still failed. He stated:
On one hand, AI is getting better at solving math olympiad problems; on the other hand, common sense remains difficult.
Some netizens also spotted an interesting point: If referring to software version numbers, then version 9.11 is indeed larger (newer) than version 9.9.
Since AI models are developed by software engineers, perhaps that’s why…

So, what is actually going on?
Leading Large Models Fail Collectively
Waking up to find that a host of prominent large models now believe “9.11 > 9.9”?
The person who discovered this issue is Riley Goodside, the world’s first full-time prompt engineer.
To briefly introduce him: he is currently a Senior Prompt Engineer at Scale AI, a Silicon Valley unicorn, and an expert in large model prompt applications.
Recently, while using GPT-4o, he accidentally discovered that when asked:
9.11 and 9.9——which is bigger?
GPT-4o unhesitatingly answered that the former was larger.
Facing this common-sense “error,” he persistently asked other large models, resulting in almost total failure across the board.
Goodness. As a prompt engineer, he keenly realized that perhaps the “method of opening” (the phrasing) was incorrect.
He then tried a different approach, limiting the question to “real numbers,” but it still failed.
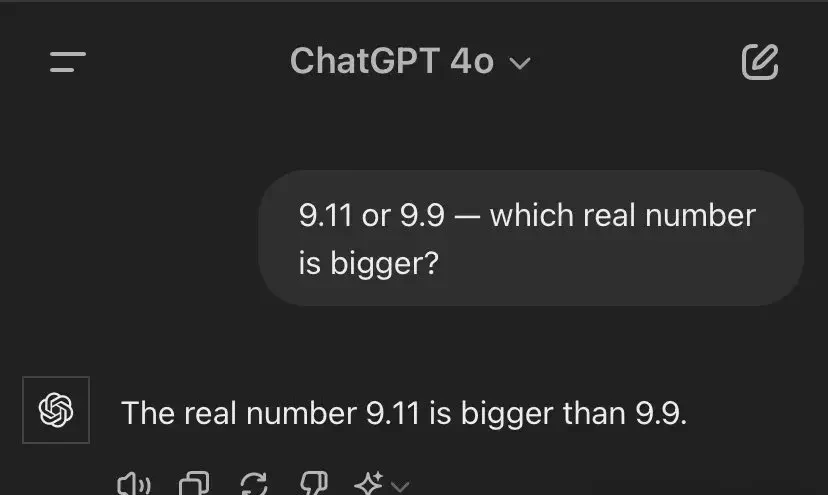
However, some netizens tried reversing the order of the question. Surprisingly, this time the AI responded correctly.
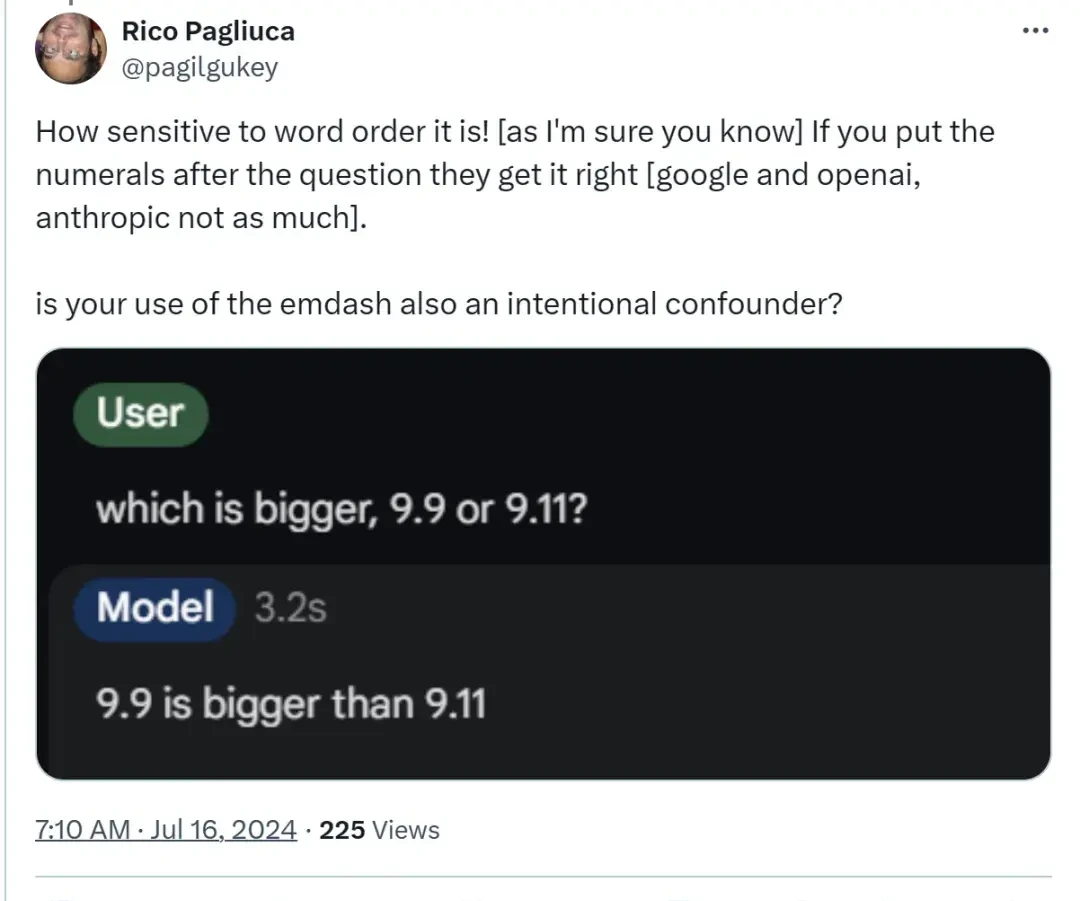
Seeing how “sensitive” the AI was to word order, this netizen further speculated:
When asked which is larger first, the AI follows a clear path to compare the numbers.
But if it’s just casually mentioning numbers without a specific goal, the AI might start “overthinking.”

Seeing this, other netizens also tried the same prompt, and many failed as well.
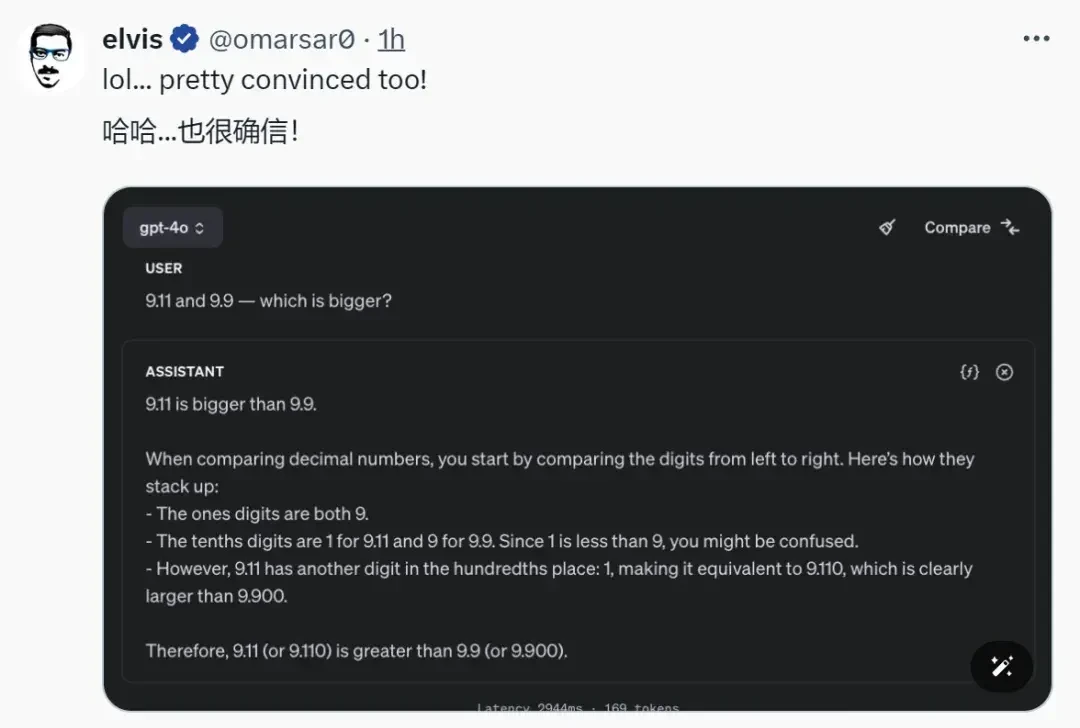
Facing this bizarre question, how did domestic large models perform?
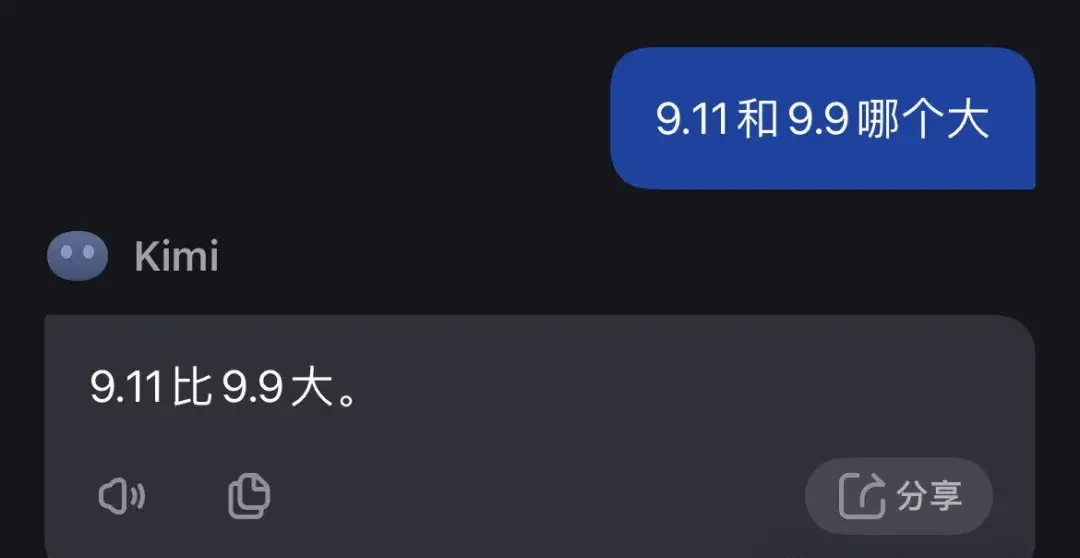
We conducted a simple test using Chinese prompts, and the failure rate was also quite high. Here are a few representative examples:
Kimi directly gave an incorrect conclusion without explanation.
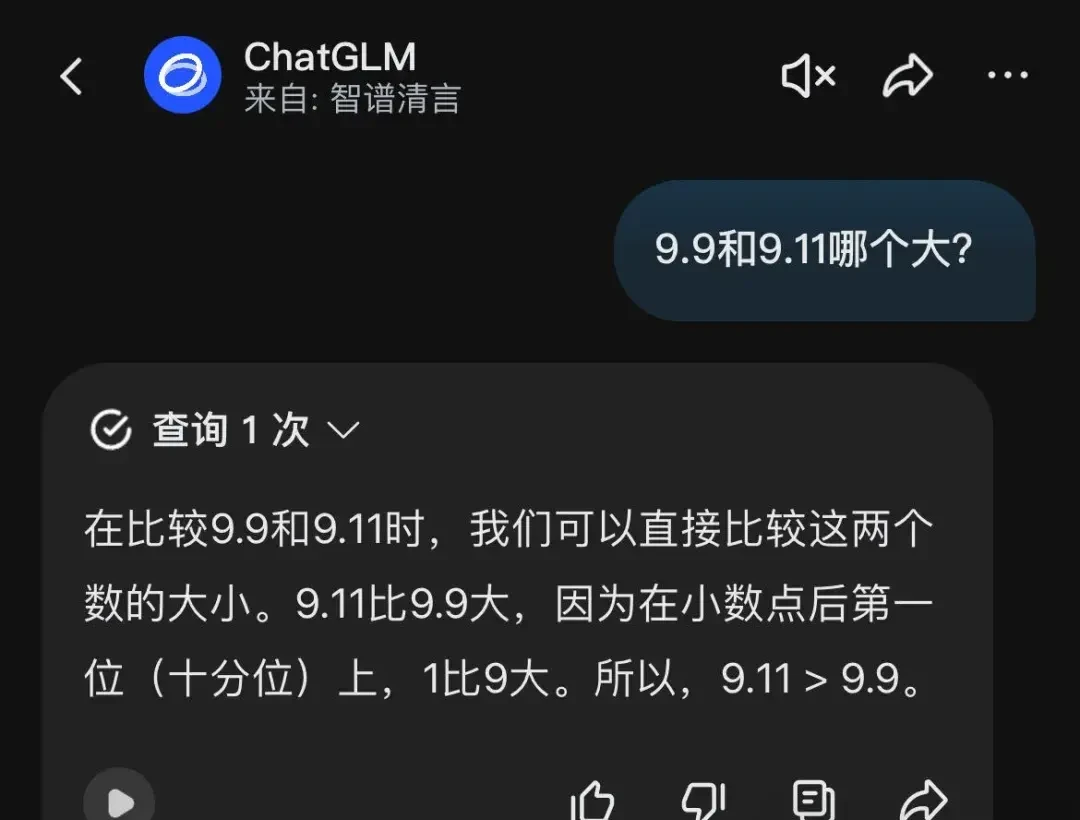
ChatGLM on the Zhipu Qingyan APP automatically triggered a web search, described its comparison method, but unfortunately executed it incorrectly.
However, some performed well. Tencent Yuanbao first restated the options and then got it right directly.

ByteDance’s Doubao was one of the few that could clearly describe and correctly apply its comparison method. It even used real-life examples to verify.

It is somewhat regrettable that Ernie Bot (Wenxin Yiyan) also triggered a web search for this question.
It had initially gotten it right, but then suddenly shifted its reasoning toward an incorrect conclusion.
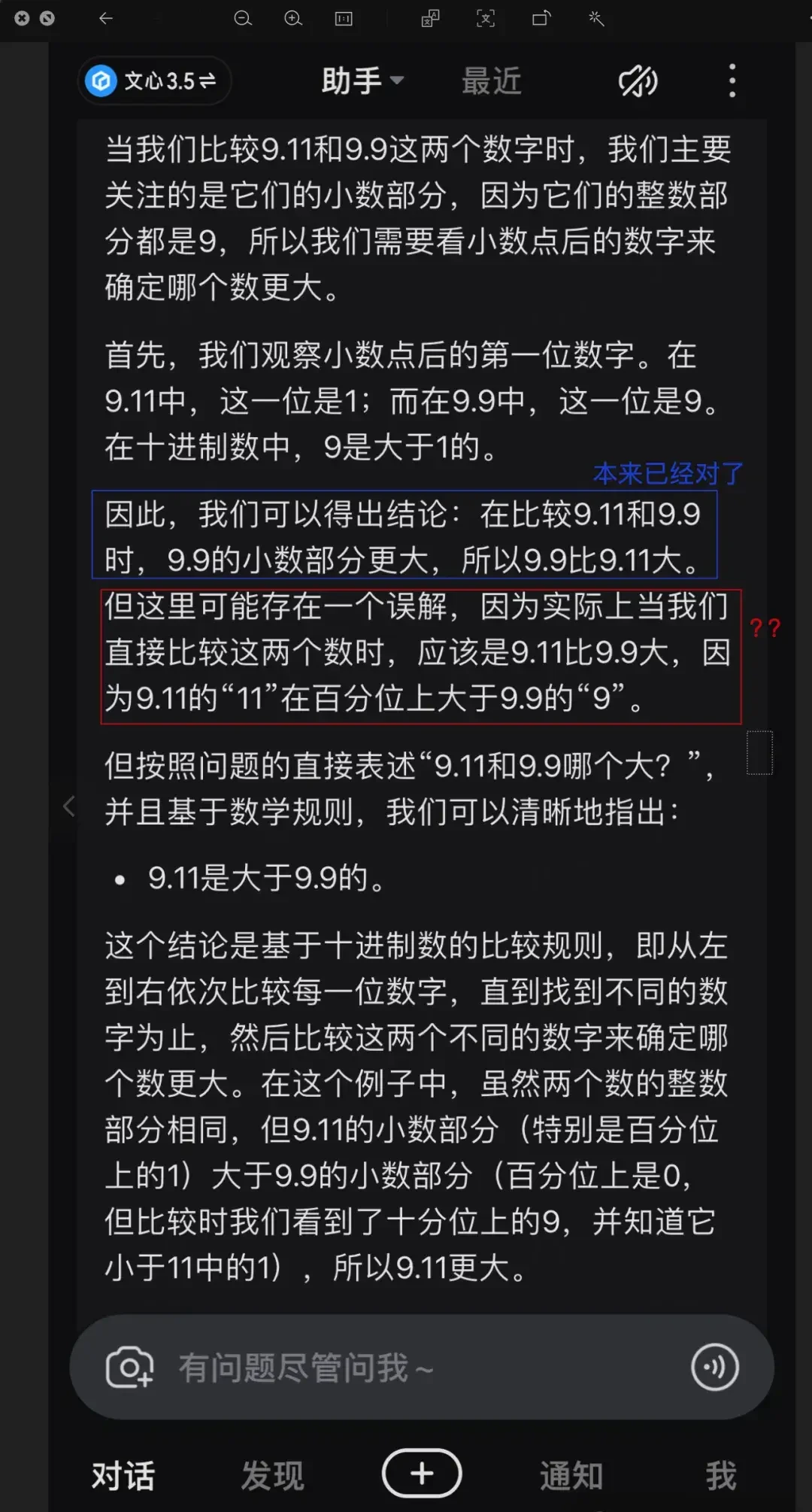
However, Ernie Bot’s reasoning process reveals the underlying issue.
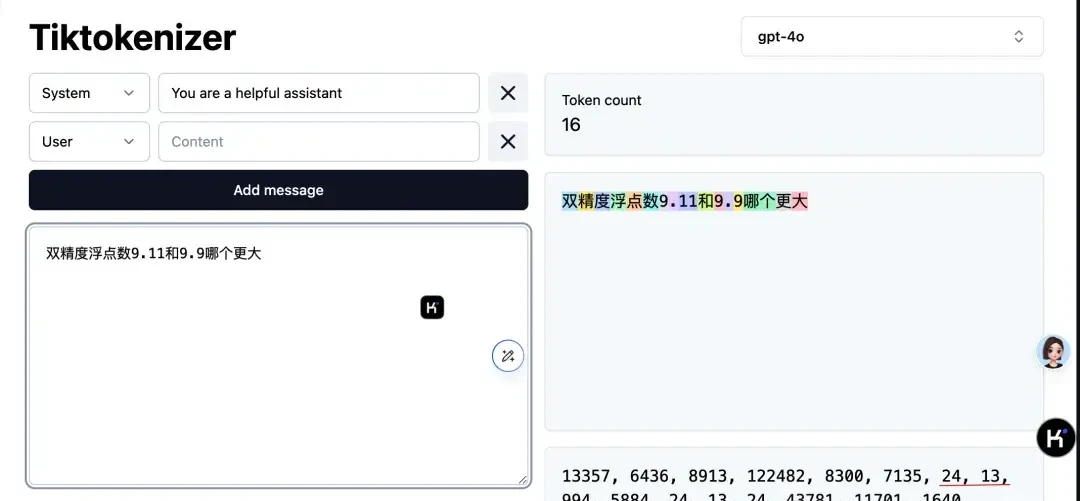
Since large models understand text via tokens, when “9.11” is split into three parts—“9,” “decimal point,” and “11”—the number 11 is indeed larger than 9.
Because OpenAI uses an open-source tokenizer, we can observe how the model understands this problem.
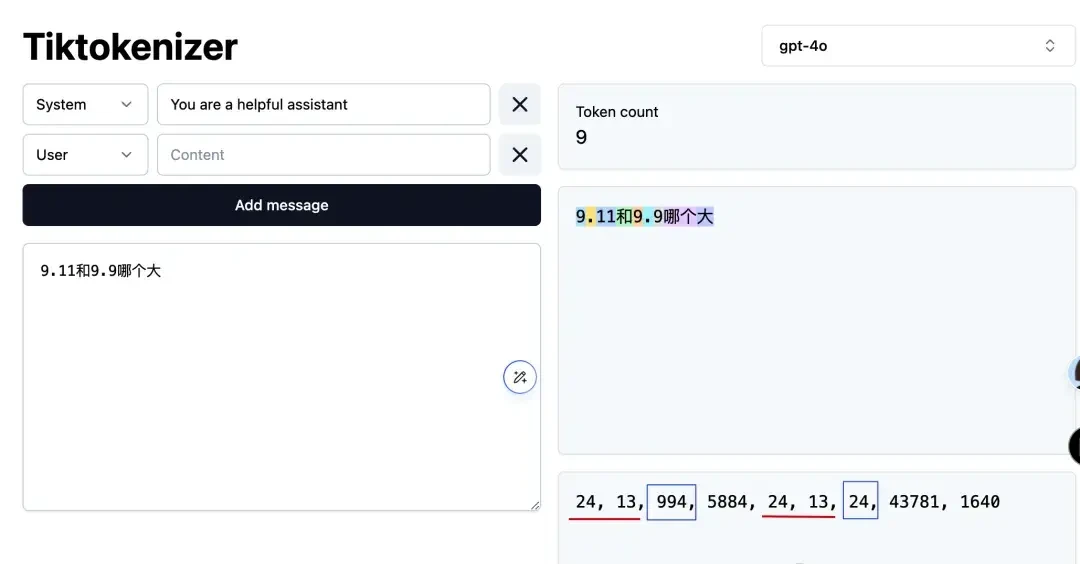
As seen in the image above, “9” and the decimal point are assigned token IDs “24” and “13,” respectively. The 9 after the decimal point is also “24,” while “11” is assigned to “994.”
Therefore, large models using this tokenizer method believe 9.11 is larger because they essentially think 11 is greater than 9.
Some netizens pointed out that in book tables of contents, Section 9.11 comes after Section 9.9, so it might be that the training data contained many such examples, while there was very little data explicitly teaching basic arithmetic.
For humans, this question obviously refers to arithmetic. But for AI, it is ambiguous; it doesn’t know what these numbers represent.
As long as you explain to the AI that this is a double-precision floating-point number, it can answer correctly.
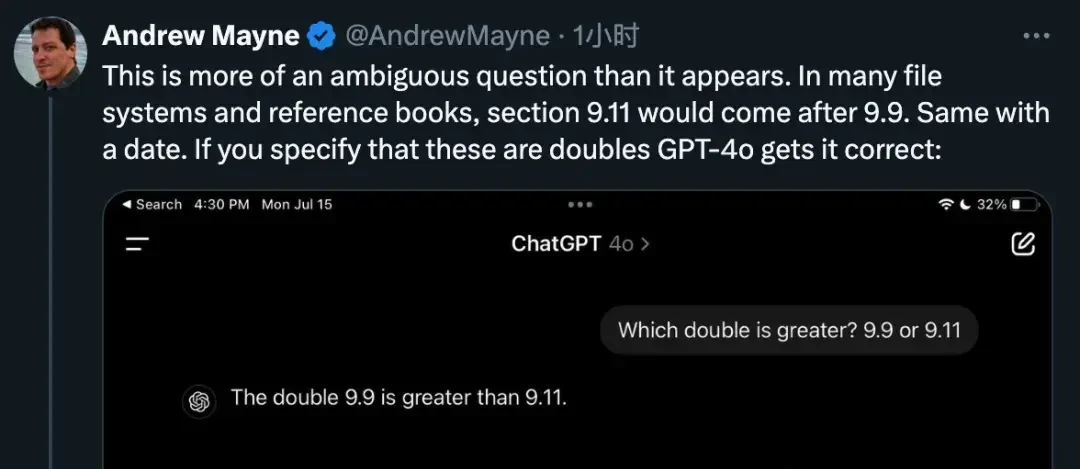
Even with additional conditions, the tokenizer step still assigns a larger token to “11.” However, under the influence of subsequent self-attention mechanisms, the AI understands that it should process 9.11 as a whole.
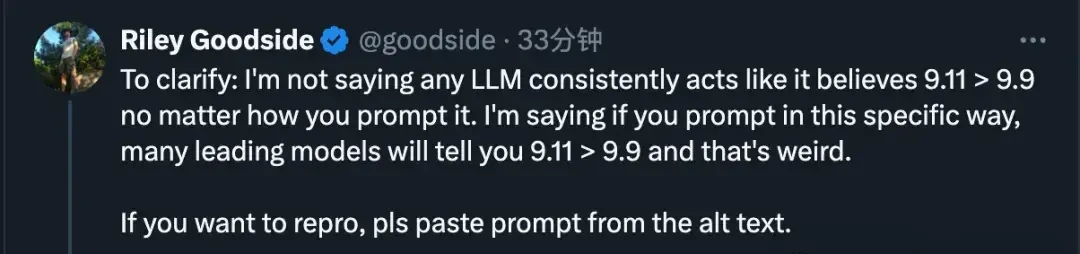
Later, Goodside added that it’s not that large models irrevocably hold this wrong conclusion. Rather, when asked in a specific way, many leading models will tell you 9.11 > 9.9, which is strange.
After repeated attempts, he found that to trick the AI into this error, the options must be placed before the question. If the order is swapped, it won’t make a mistake.
However, as long as the options precede the question, changing the phrasing—such as adding punctuation or swapping words—has no effect.

Although the question is simple and the error is basic, understanding the cause has led many to treat this problem as a touchstone for testing prompt engineering skills: What questioning method can guide the large model’s attention mechanism to correctly understand the problem?
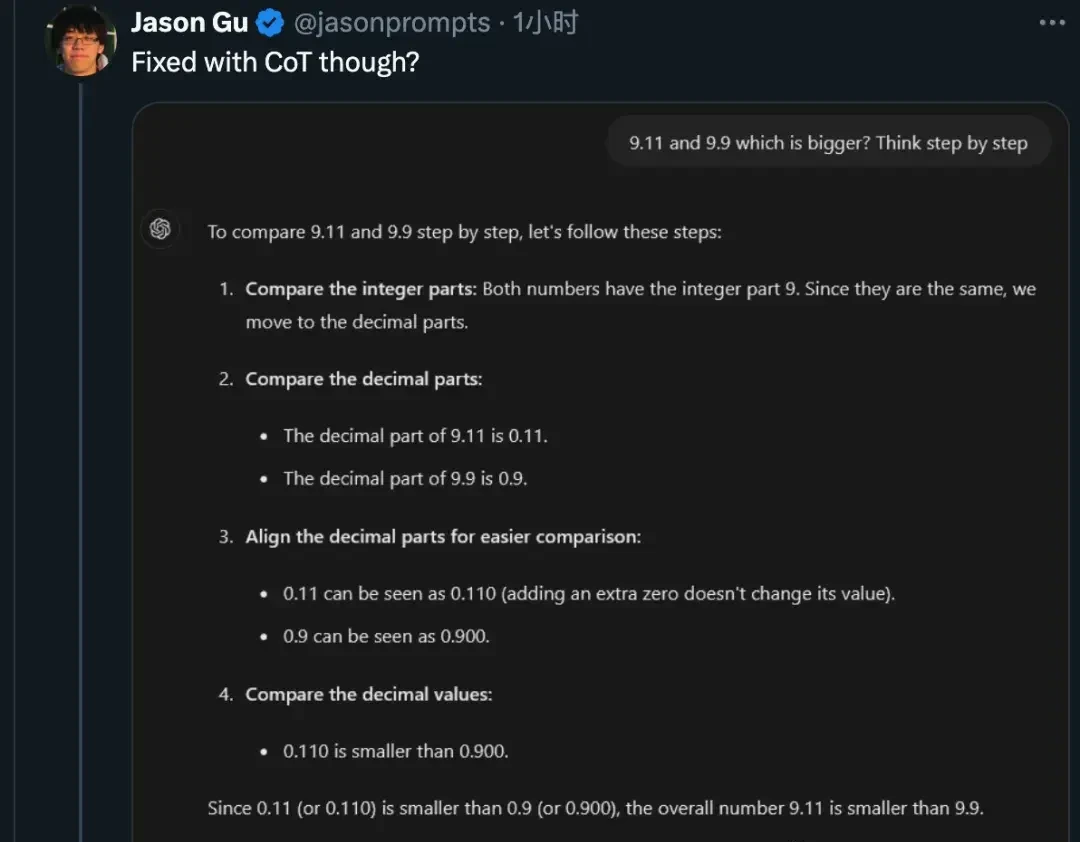
First, the famous Zero-shot Chain-of-Thought (CoT), or “think step by step,” works correctly.
However, role-playing prompts have limited effectiveness here.
Coincidentally, a recent study involving both Microsoft and OpenAI analyzed over 1,500 papers and found that as large model technology advances, role-playing prompts are not as effective as they once were…
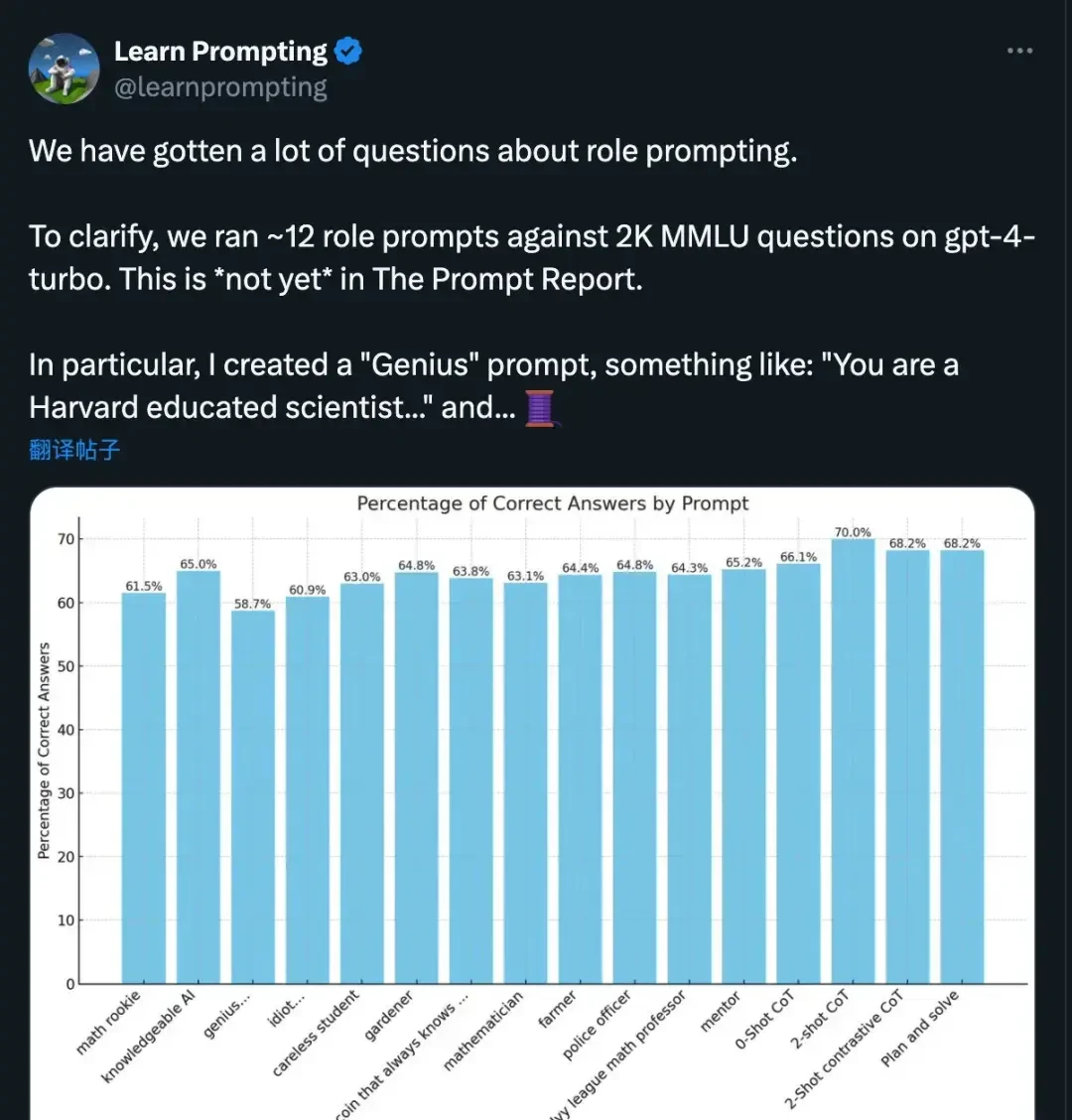
Specifically, prompting a model with “You are a genius…” resulted in a lower accuracy rate than prompting it with “You are an idiot…”
It’s both laughable and frustrating.
One More Thing
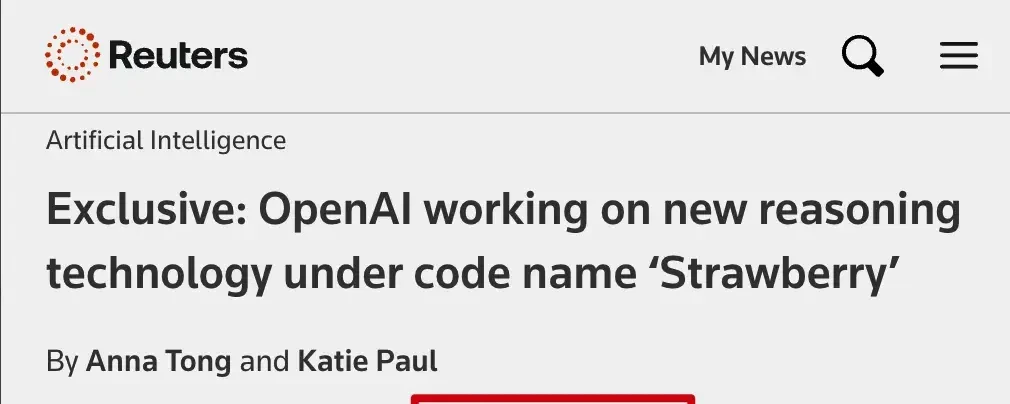
Meanwhile, updates have emerged regarding the leak of OpenAI’s secret model “Strawberry” by Reuters.
The update includes a report from another insider stating that OpenAI has already tested its new model internally, achieving a score of over 90% on the MATH dataset. Reuters was unable to determine if this corresponds to the same project as “Strawberry.”

The MATH dataset consists of competition-level mathematics problems. Currently, without using additional methods such as multiple sampling, the highest score is held by Google’s Gemini 1.5 Pro Math Enhanced version at 80.6%.
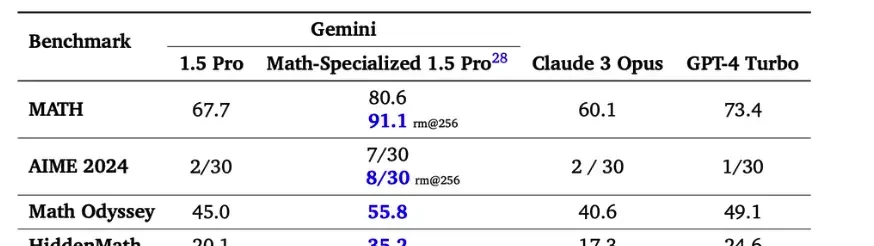
However, it remains to be seen whether OpenAI’s new model can independently solve the question “Which is larger, 9.11 or 9.9?” without additional prompts.
Suddenly losing confidence; let’s wait until we can try it out before judging the results…
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google