Kaiming He’s New Team Effort Arrives After Joining MIT as Associate Professor!

Enabling autoregressive models to abandon vector quantization in favor of continuous values for image generation. By borrowing concepts from diffusion models, the team proposes Diffusion Loss.

Since joining MIT, Kaiming He had participated in several other computer vision papers, but these were collaborations with teams such as that of MIT Professor Wojciech Matusik.
This time, however, Kaiming He is leading the team himself, and a familiar name appears among the participants:
Mingyang Deng, an IMO (International Mathematical Olympiad) and IOI (International Olympiad in Informatics) double gold medalist, known in the competitive programming community as “Guai Shen” (Obedient God).

Mingyang Deng is currently an undergraduate at MIT. Based on his enrollment timeline, he is likely a senior this year. Consequently, many netizens speculate that if he continues to pursue a PhD at MIT, he may join Kaiming He’s team.
Here is a detailed introduction to what this paper investigates.
Borrowing from Diffusion Models: A Major Overhaul of Autoregressive Generation
The traditional view holds that autoregressive models for image generation typically involve Vector Quantization (VQ). For instance, the first version of DALL·E used the classic VQ-VAE method.
However, the team observed that the essence of autoregressive generation is predicting the next token based on previous values, which actually has no necessary connection to whether those values are discrete or continuous.
The key lies in modeling the probability distribution of tokens; as long as this distribution can be measured by a loss function and used to sample from it, it works.
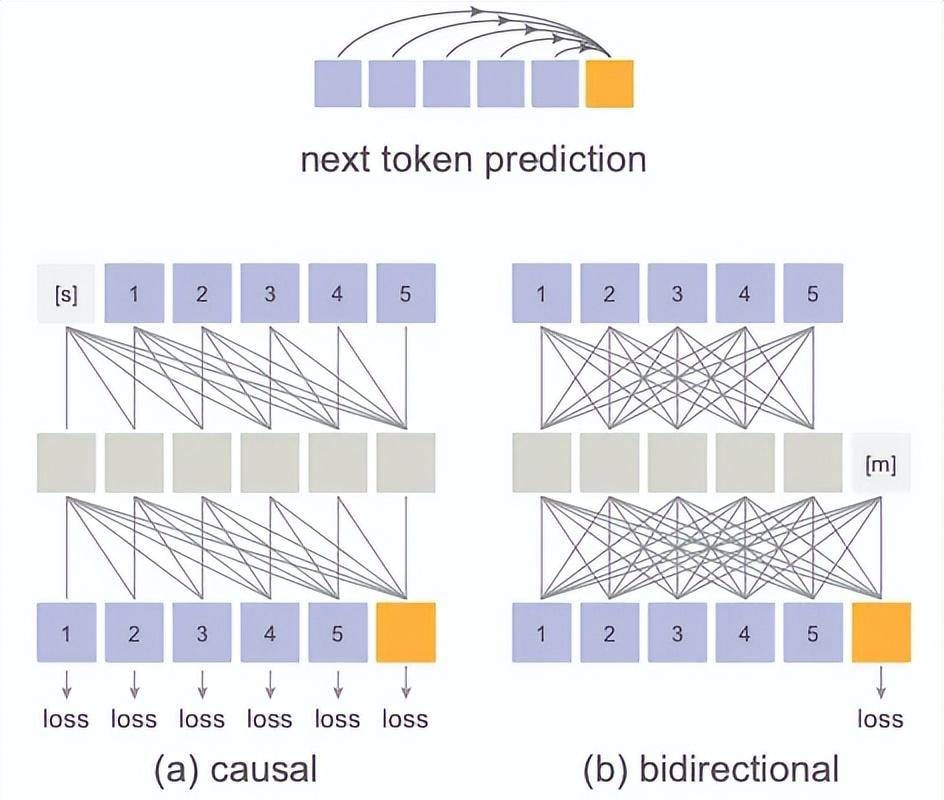
Furthermore, from another perspective, vector quantization methods bring a series of troubles:
- They require a discrete token vocabulary and carefully designed quantization objective functions. Training is difficult and highly sensitive to gradient approximation strategies.
- Quantization errors lead to information loss, resulting in degraded image reconstruction quality.
- Discrete tokens are suitable for modeling categorical distributions, which imposes limitations on expressive power.
So, what is a better alternative?
The Kaiming He team decided to modify the loss function. Drawing inspiration from the recently popular diffusion models, they proposed Diffusion Loss, eliminating the need for discrete tokenizers.
This makes it feasible to apply autoregressive models in continuous value spaces for image generation.

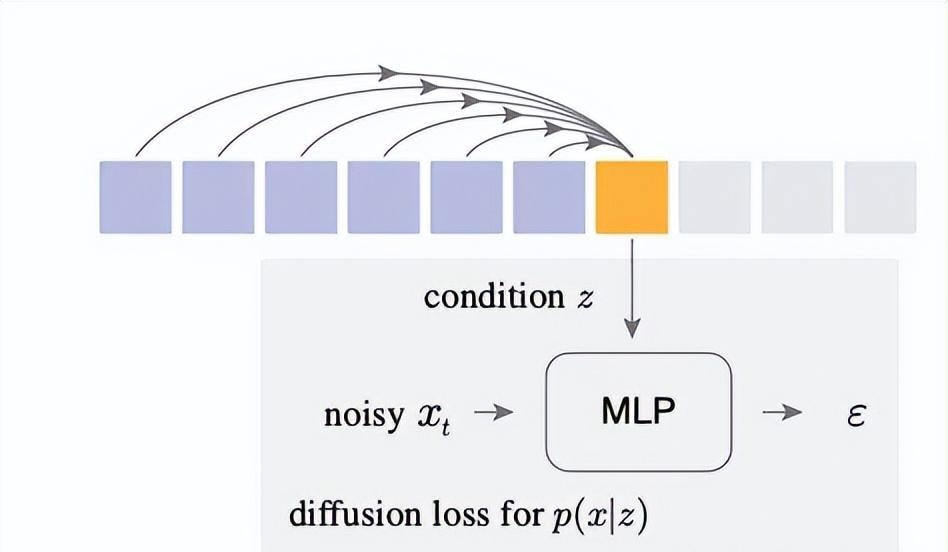
Specifically, it allows the autoregressive model to output a latent variable $z$ as a condition to train a small denoising MLP network.
Through the reverse diffusion process, this small network learns how to sample and generate continuous value tokens $x$ based on $z$. The diffusion process naturally models arbitrarily complex distributions, thus avoiding the limitations of categorical distributions.
This denoising network and the autoregressive model are trained end-to-end jointly. The chain rule directly propagates the loss back to the autoregressive model, enabling it to learn how to output the optimal conditional $z$.
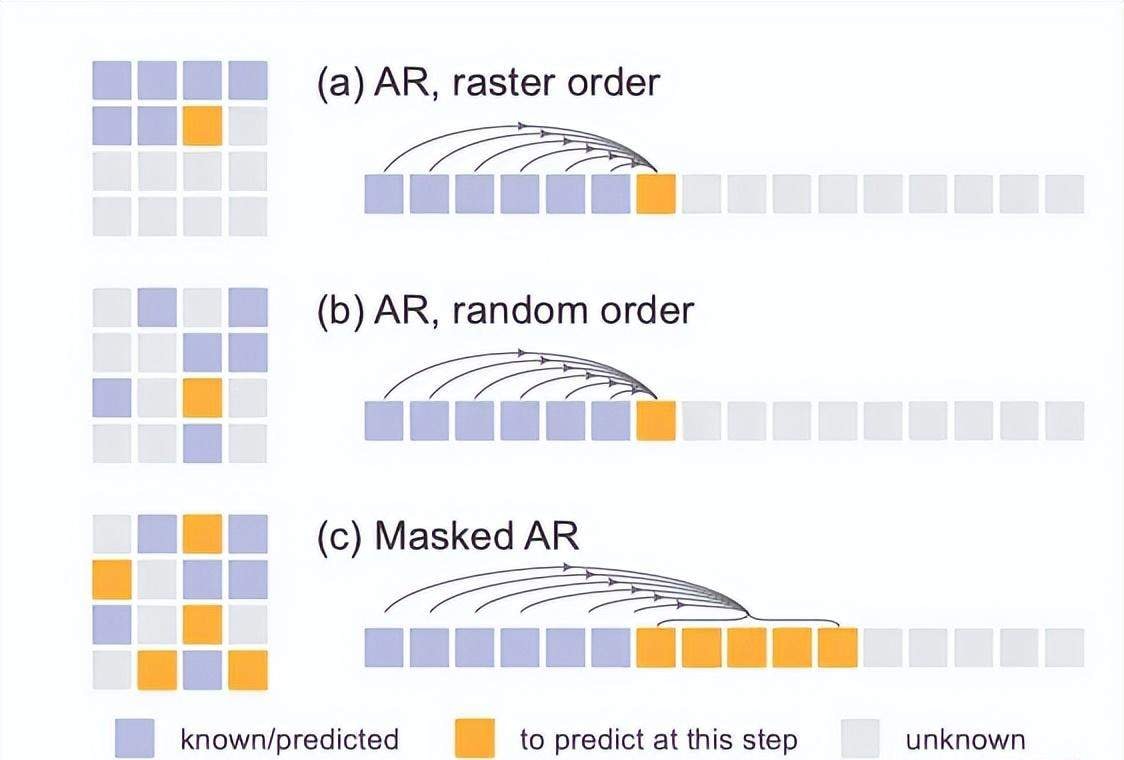
Another highlight of this work is its applicability to various variants of autoregressive models. It unifies standard Autoregressive (AR), randomly ordered AR, and the masked methods favored by Kaiming He.
The Masked Auto-Regressive (MAR) model can predict multiple tokens simultaneously at any random positions while working perfectly with diffusion loss.
Within this unified framework, all variants either predict token-by-token or predict a batch of tokens in parallel. Essentially, they are all predicting unknown tokens based on known ones, constituting generalized autoregressive models. Therefore, diffusion loss is applicable to all of them.
By eliminating vector quantization, the image generation model trained by the team achieved powerful results while enjoying the speed advantages of sequence modeling.
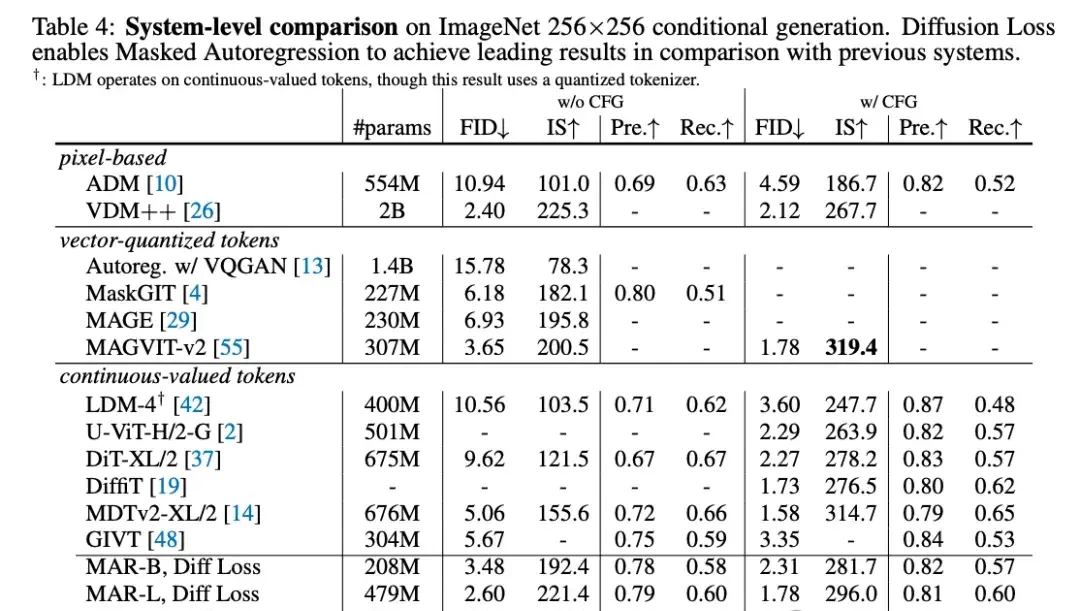
The paper conducted extensive experiments on various AR and MAR variants. The results indicate that diffusion loss provides a stable 2-3x improvement over cross-entropy loss.
It holds its own against other leading models; small models achieve an FID score of 1.98, while large models set a new State-of-the-Art (SOTA) record of 1.55.
Moreover, it generates 256×256 images very quickly, taking less than 0.3 seconds per image. This is due to the inherent speed of autoregressive generation, which requires far fewer sampling steps than diffusion models, combined with the fact that the denoising network is small.
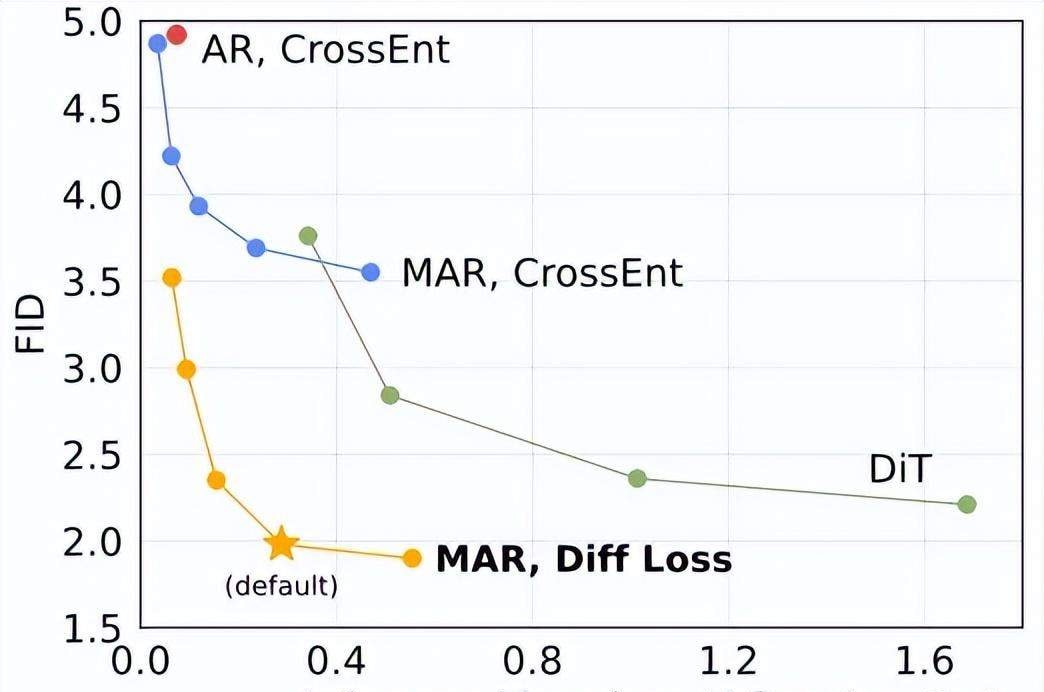
To summarize, this work models the correlations between tokens via autoregression and pairs it with a diffusion process to model the distribution of each token.
This differs from standard latent space diffusion models that use a single large diffusion model to model the joint distribution of all tokens. Instead, it performs local diffusion, demonstrating significant potential in terms of effect, speed, and flexibility.
Of course, there is still room for further exploration with this method. The team notes that performance on certain complex geometric understanding tasks needs improvement.
Who Is in Kaiming He’s Team?
Finally, let’s introduce the team members who are joining or may join Kaiming He’s research group soon.
Tianhong Li, an alumnus of Tsinghua University’s Yao Class and a current MIT PhD student, will join Kaiming He’s group in September 2024 as a postdoctoral researcher.

Mingyang Deng, currently an undergraduate majoring in Mathematics and Computer Science at MIT.
He won a gold medal at the IMO in his freshman year of high school and a gold medal at the IOI in his senior year. He is one of the few double gold medalists in the competition community and was the third person in IOI history to achieve a perfect score.
Mingyang Deng’s current research focus is machine learning, particularly understanding and advancing generative foundation models, including diffusion models and large language models.
However, his personal website does not yet reveal his next steps.
One More Thing
Kaiming He’s job talk at MIT attracted significant attention. He mentioned that his future work direction would be AI for Science, sparking heated discussions within the industry.

Now, Kaiming He’s first paper in the AI for Science (AI4S) direction has arrived: Reinforcement Learning + Quantum Physics.
Applying Transformer models to dynamic heterogeneous quantum resource scheduling problems, utilizing self-attention mechanisms to process sequence information of qubit pairs. They trained reinforcement learning agents in a probabilistic environment to provide dynamic, real-time scheduling guidance, ultimately significantly improving quantum system performance—more than three times better than rule-based methods.

In this way, Kaiming He has not neglected either his renowned field of Computer Vision or his exploration of new domains such as AI for Science. Two flowers blooming simultaneously.
Paper:
https://arxiv.org/abs/2406.11838
References
- Tianhong Li
- Mingyang Deng — lambertae.github.io/
- Dynamic Inhomogeneous Quantum Resource Scheduling with Reinforcement Learning — A central challenge in quantum information science and technology is achieving real-time estimation and feedforward control of quantum systems. This challenge is compounded by the inherent inhomogeneity of quantum resources.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google