Earlier coverage of DeepSeek-V4 focused on Flash-model smoke tests on dual H20 GPUs and why vLLM deployments are so finicky. This piece takes a different angle: why the V4 release is hard to serve, and how SGLang shipped day-zero support.
What Changed in V4
DeepSeek released two variants at once:
| Variant | Total params | Active params | Single-node floor |
|---|---|---|---|
| DeepSeek-V4-Flash | 284B | 13B | B200 / GB200 / GB300 / 4× H200 |
| DeepSeek-V4-Pro | 1.6T | 49B | 8× B200 / 8× GB200 (2 nodes) / 4× GB300 / 8× H200 (FP4) |
Both Instruct checkpoints use FP4 MoE expert weights plus FP8 attention/dense layers. One weight bundle runs across FP4-capable Hopper, Blackwell, AMD, and NPU hardware under the MIT license, with 1M context and 32T+ pretraining tokens.
The architectural stack has three major pieces:
- Hybrid sparse attention (CSA + HCA): Every layer combines a 128-token sliding window (SWA) with one of two compression paths—C4 (4:1 compression + top-512 sparsity) or C128 (128:1 compression + dense). At 1M context, V4-Pro needs only 27% of V3.2 FLOPs per token and roughly 10% of the KV cache.
- mHC (manifold-constrained hyper-connections): Residual paths become a mixture of parallel branches with Sinkhorn-normalized weights, improving gradient flow and representation quality.
- Native FP4 expert weights: MoE experts run on Blackwell FP4 tensor cores, reducing decode bandwidth bottlenecks on small batches.
V4 also ships a single-layer MTP head for speculative decoding, plus three reasoning modes: Non-think (fast answers), Think High (chain-of-thought), and Think Max (maximum reasoning; ≥384K context recommended).
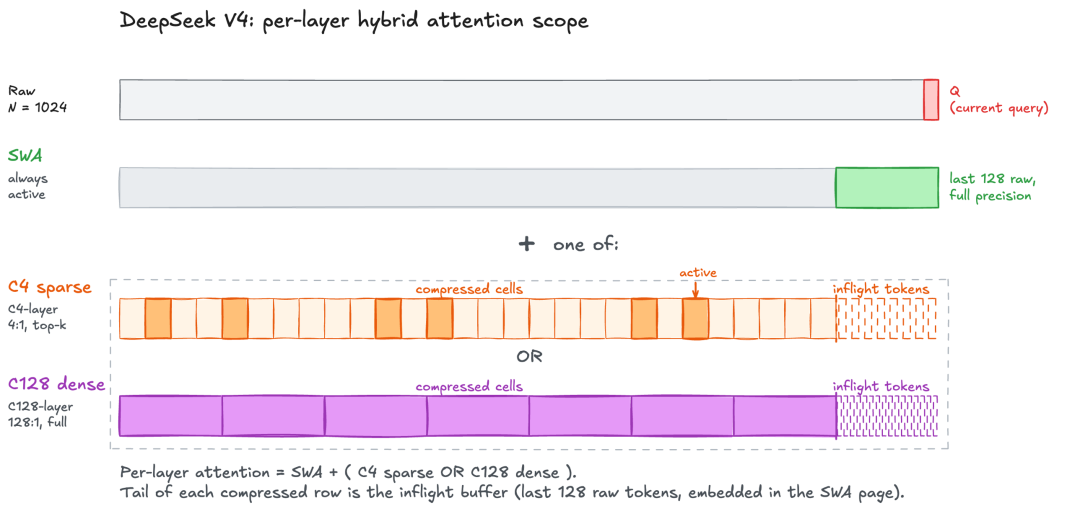
Hybrid attention scope per V4 layer (example with N=1024).
What SGLang Built Under the Hood
The painful part of hybrid attention is three heterogeneous KV pools plus two compressed-state pools that must stay consistent across prefill, decode, and speculative passes. Classic prefix-cache assumptions no longer hold.
ShadowRadix: prefix cache for hybrid attention
SGLang indexes virtual full-token slots in a radix tree, then projects them into physical pools (SWA / C4 / C128). Compressed-state ring buffers nest inside SWA page indices with address swa_page * ring_size + pos % ring_size. When an SWA page is freed, the ring invalidates automatically—no extra bookkeeping.
Each node tracks full_lock_ref (source + C4/C128 shadows) and swa_lock_ref (sliding window only). When the SWA count hits zero, SWA slots are tombstoned while compressed shadows remain reusable on the tree. A 10K-token request therefore keeps only 128 SWA tokens plus full C4/C128 compression—that compressed KV is what gets reused.
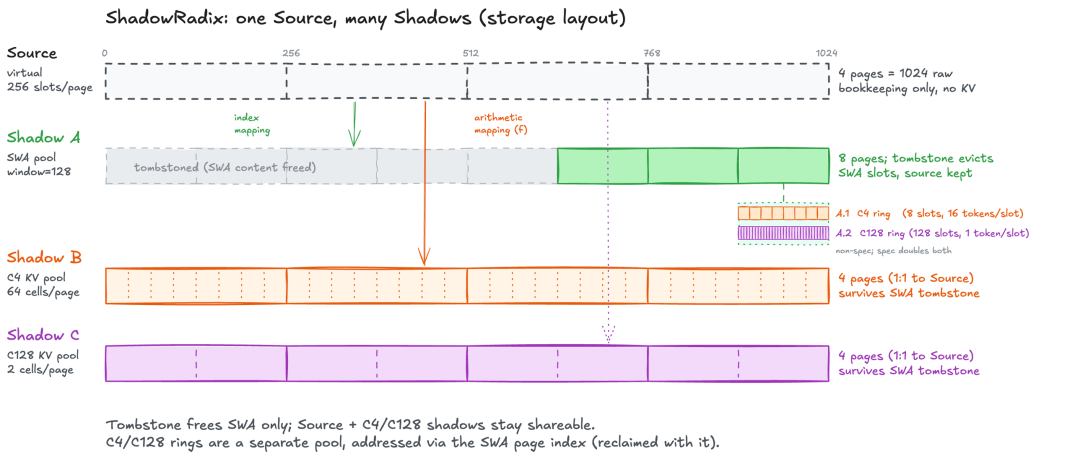
ShadowRadix storage layout.
Speculative decoding adds a subtle bug: draft tokens land in the ring before verification; rejected drafts can overwrite live slots on retry. SGLang doubles ring size under spec mode (C4: 8→16, C128: 128→256), so EAGLE works out of the box.
HiSparse: offload inactive KV to CPU
C4 layers activate only a small top-k of compressed positions each step—most KV is cold at any moment. HiSparse mirrors the C4 pool on CPU, keeps a small GPU working set, and asynchronously pages data each step with LRU eviction. On dual B200 with 200K input / 20K output, peak throughput improves up to 3×.
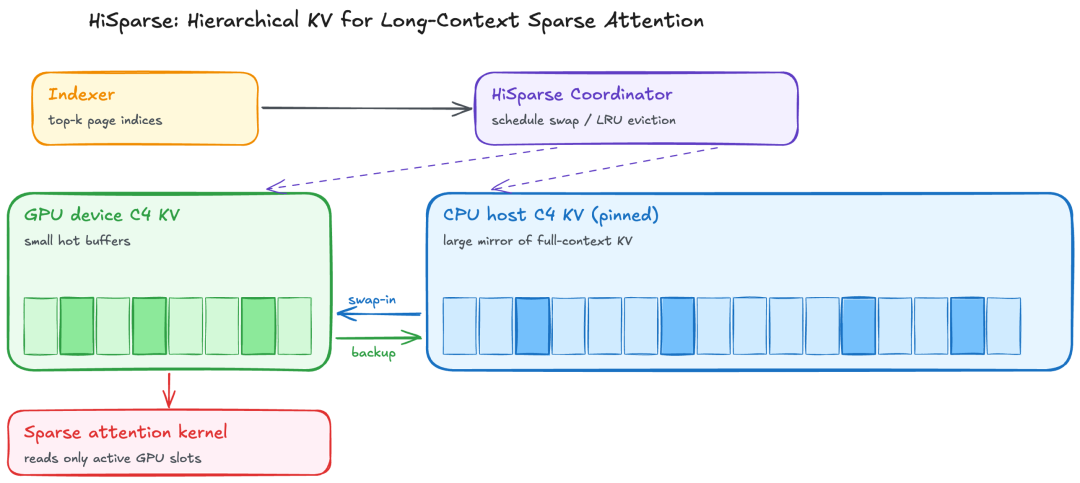
HiSparse architecture and peak throughput gains.
MTP speculative decoding with in-graph metadata
Hybrid attention metadata is heavy—SWA page indices, shadow maps, compressor/indexer plans, per-pool write positions. Preparing it eagerly on the scheduler thread kills speculative launch overhead.
SGLang embeds metadata preparation inside CUDA Graphs. Each replay copies raw batch state into fixed buffers; indexing arithmetic runs in device kernels. Combined with CPU-side overlap scheduling, speculative startup overhead drops sharply.
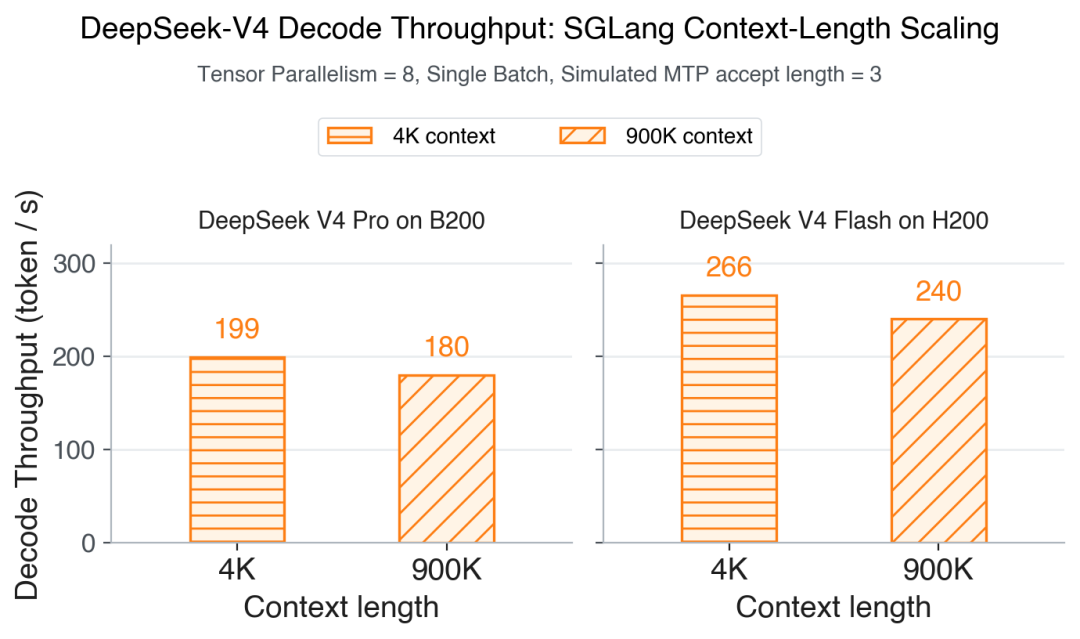
Decode throughput across context lengths.
ShadowRadix + in-graph spec metadata push SGLang decode throughput from 4K tokens through ~900K, near the 1M window. On B200, throughput falls from 199 to 180 tok/s; on H200, from 266 to 240—under 10% drop on both. That flat curve is rare for long-context serving.
Kernel-level work
Other notable integrations:
- FlashMLA extensions: SWA and extra attention (C4/C128) in one kernel call with shared metadata.
- Flash Compressor: Compresses five HBM round trips to one on-chip pass (5→2), reaching ~80% peak H200 bandwidth—10×+ over naive PyTorch pipelines.
- Lightning TopK: At 1M context, the indexer selects top-512 from 256K candidates in ~15µs via cluster-of-8 radix select (vs 100µs+ naive).
- FlashInfer TRTLLM-Gen MoE: MXFP8 activations × MXFP4 experts on Blackwell FP4 cores.
- DeepGEMM Mega MoE: Fuses EP dispatch, first FP8×FP4 GEMM, SwiGLU, second GEMM, and EP combine with overlapped NVLink.
- TileLang mHC kernels (split-K): Recovers pre-GEMM bottlenecks on low-latency decode.
- DP/TP/CP attention, DeepEP MoE, PD disaggregation: Full parallel and disaggregated serving options.
How to Deploy
SGLang publishes per-platform Docker images:
| Hardware | Image |
|---|---|
| NVIDIA B300 | lmsysorg/sglang:deepseek-v4-b300 |
| NVIDIA B200 | lmsysorg/sglang:deepseek-v4-blackwell |
| NVIDIA GB200/GB300 | lmsysorg/sglang:deepseek-v4-grace-blackwell |
| NVIDIA H200 | lmsysorg/sglang:deepseek-v4-hopper |
Minimal launch template:
docker run --gpus all \
--shm-size 32g \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--env "HF_TOKEN=<your-hf-token>" \
--ipc=host \
lmsysorg/sglang:deepseek-v4-blackwell \
sglang serve <use args below>Use the official interactive command generator for exact flags:

https://docs.sglang.io/cookbook/autoregressive/DeepSeek/DeepSeek-V4#3-1-basic-configuration
Three main recipes:
low-latency: MTP steps=3, draft-tokens=4—best at batch size 1.balanced: MTP steps=1, draft-tokens=2—better at high batch.max-throughput: MTP off—when verify cost dominates at saturation.
Specialized options: cp (prefill context parallelism for long context) and pd-disagg (prefill/decode disaggregation).
After launch, call the standard OpenAI-compatible endpoint:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-ai/DeepSeek-V4-Flash",
"messages": [{"role": "user", "content": "What is 15% of 240?"}]
}'Add the deepseek-v4 reasoning parser to split reasoning_content and content; use the deepseekv4 tool parser for structured tool calls.
Production Pitfalls
- DeepEP dispatch buffer: Require
max-running-requests × MTP_draft_tokens ≤ SGLANG_DEEPEP_NUM_MAX_DISPATCH_TOKENS_PER_RANK. Violations corrupt buffers under steady load; defaults are conservative—tune upward after smoke tests. - Hopper (H200) paths: Original FP4 checkpoints use Marlin w4a16 MoE (TP only; full Pro fits one node). For more parallelism, use SGLang FP8 conversions (
sgl-project/DeepSeek-V4-Flash-FP8/Pro-FP8). - PD-Disagg on H200:
docker runneeds--privileged --ulimit memlock=-1(or IB device +IPC_LOCK); otherwise Mooncake falls back to TCP and large checkpoints may corrupt KV transfers. - Base models: Set
SGLANG_FIX_DSV4_BASE_MODEL_LOAD=1. - GB300 cross-pod NVLink: If Mooncake reports
nvlink_transport.cpp:497 Requested address ... not found!, addMC_FORCE_MNNVL=1 NCCL_MNNVL_ENABLE=1 NCCL_CUMEM_ENABLE=1on both prefill and decode pods.
For implementation details, see sgl-project/sglang#23600—from V4Config registration through hybrid-attention kernels.
Takeaways
DeepSeek pushed aggressive architecture to make 1M context affordable—27% FLOPs and ~10% KV cache versus V3.2 at scale. The cost: inference engines must rebuild KV/cache/attention paths. SGLang’s day-zero stack—ShadowRadix, HiSparse, in-graph spec metadata, and new kernels—is systems engineering, not a patch set.
LMSYS day-zero charts show SGLang leading another open engine at 30K context single-batch decode, though rivals were still tuning MTP and long-context configs. SGLang’s own curves matter more: V4-Pro on B200 stays near-flat from 4K to 900K; V4-Flash on H200 drops less than 10%—the kind of stability that makes long context deployable in production.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google