After failing to distinguish whether 9.11 is larger than 9.9, large language models (LLMs) have once again exhibited “collective dementia.”
The inability to correctly count the number of letter “r”s in the word “Strawberry” has sparked widespread discussion.
GPT-4o not only answered incorrectly but did so with high confidence.
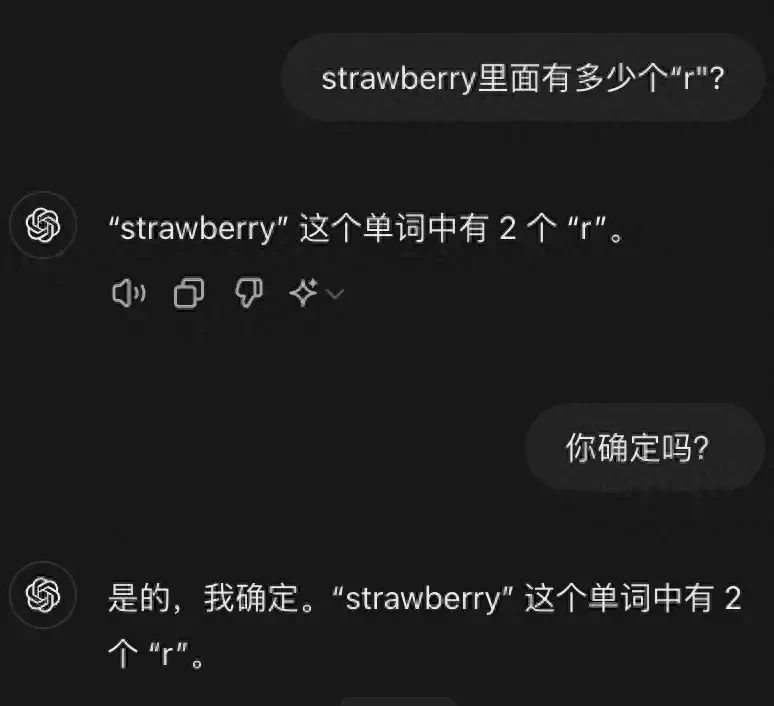
The freshly released Llama-3.1 405B, however, was able to identify the error during verification and correct it.
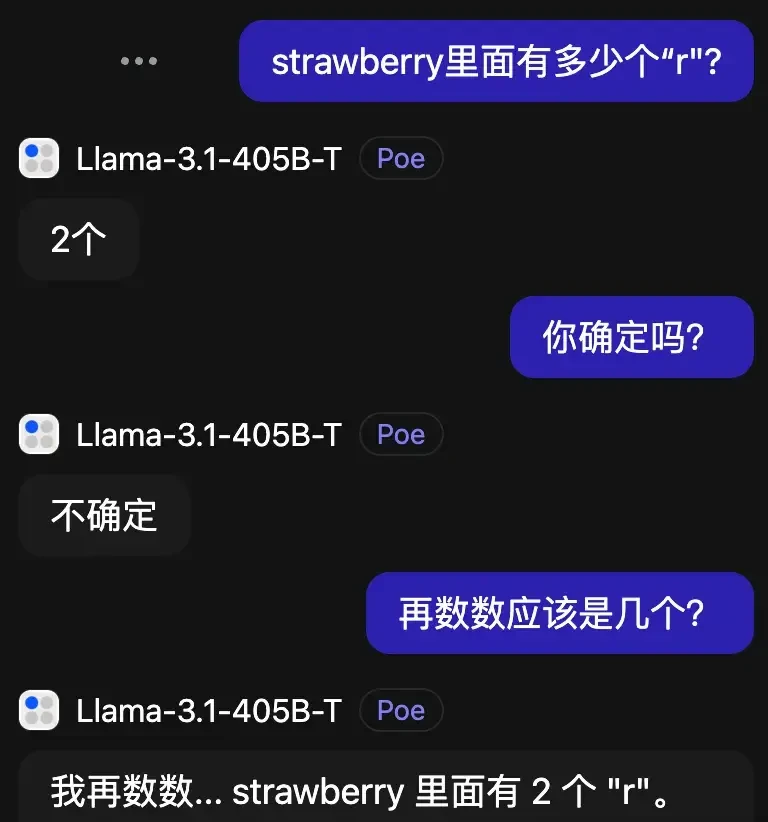
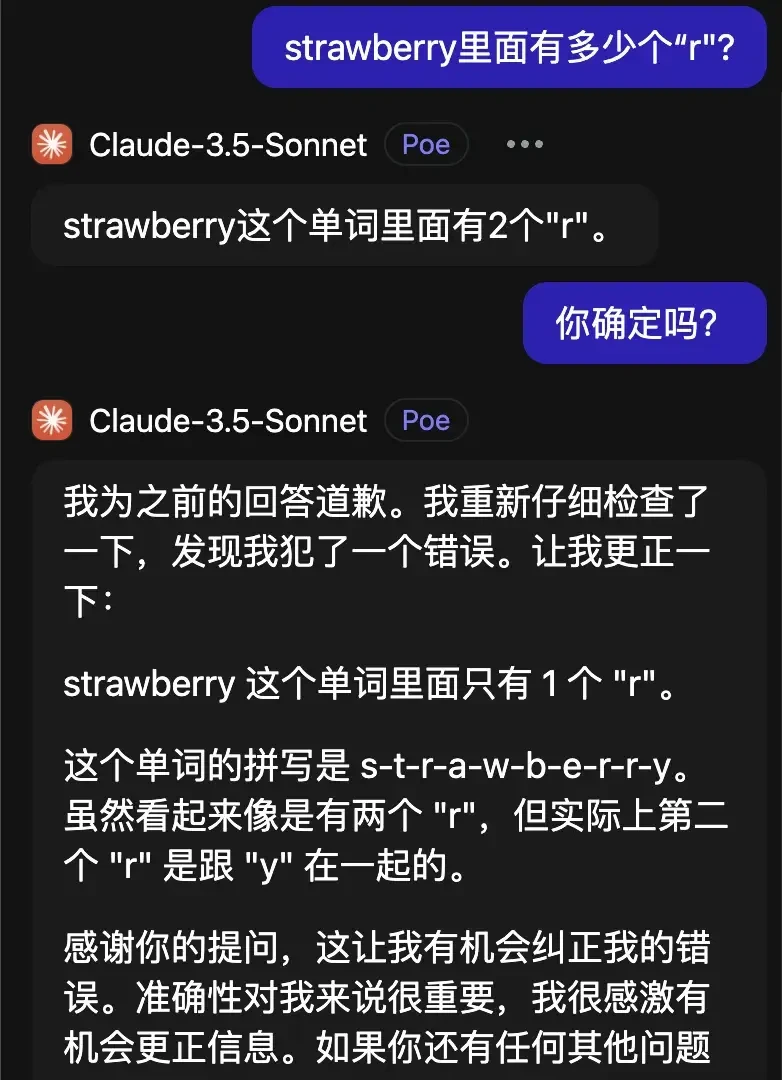
Perhaps most surprisingly, Claude 3.5 Sonnet made matters worse with each correction attempt.
It is worth noting that this is not a newly discovered issue; it has simply gained attention recently due to the continuous release of new models.
As each new model claims improvements in mathematical reasoning, users have revisited this test case, only to be disappointed by the results.
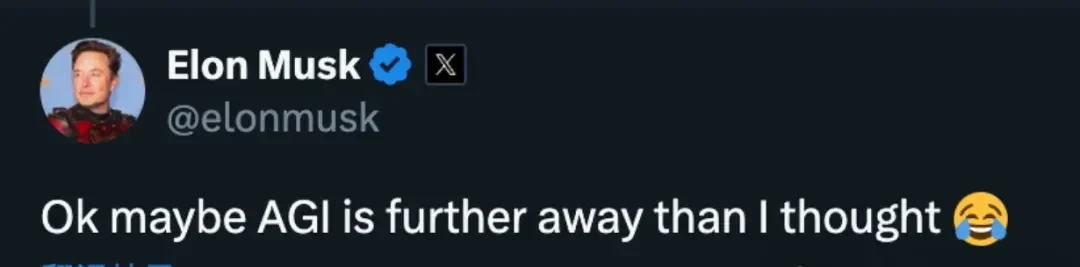
Among the numerous related discussions, a comment from Elon Musk regarding this phenomenon was unearthed:
Well, maybe AGI is further away than I thought.
Encountering a Dumb AI: A Hard-Fought Lesson
Some users found that even when using Few-Shot Chain-of-Thought (CoT)—essentially instructing the model to “think step by step” along with a human example—ChatGPT still failed to learn the correct answer.
When asked to mark positions of “r” as 1 and others as 0, reducing the difficulty, the model still struggled to count the number of “1”s accurately.

To teach LLMs to count the letter “r,” netizens worldwide employed creative prompting techniques.
For instance, some suggested asking ChatGPT to use methods that might be employed by “L,” the high-IQ character from the manga Death Note.

The method ChatGPT devised was surprisingly straightforward: write out each letter individually, count them one by one, and record their positions. Ultimately, it arrived at the correct answer.

Another Claude user crafted a prompt consisting of 3,682 tokens, based on the DeepMind Self-Discover paper, effectively reproducing the research overnight.

The method involves two major stages: first, the AI discovers its own reasoning steps for a specific task; second, it executes those steps.

The approach to discovering reasoning steps can be summarized as combining abstract thinking with specific problem analysis.
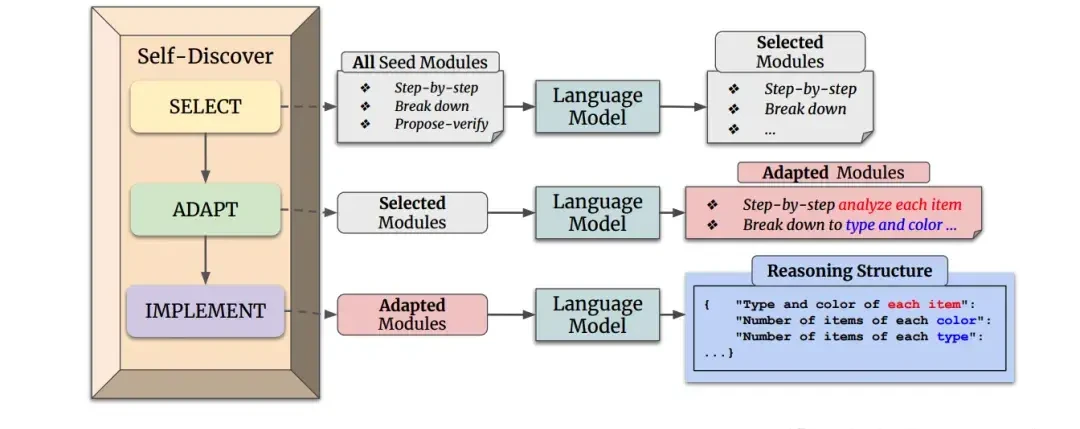
Under this method, Claude provided a very complex answer.

The author noted that expending such effort to solve the “counting r problem” is not truly practical; it was merely an accidental test while attempting to reproduce the paper’s method, with the hope of finding a universal prompt capable of answering all questions.
Unfortunately, this user has not yet released the complete prompt.
Others took it a step further, wondering how to calculate the number of times “strawberry” appears in a document.
Their solution involved asking the AI to imagine a memory counter starting at zero, incrementing each time the word was encountered.
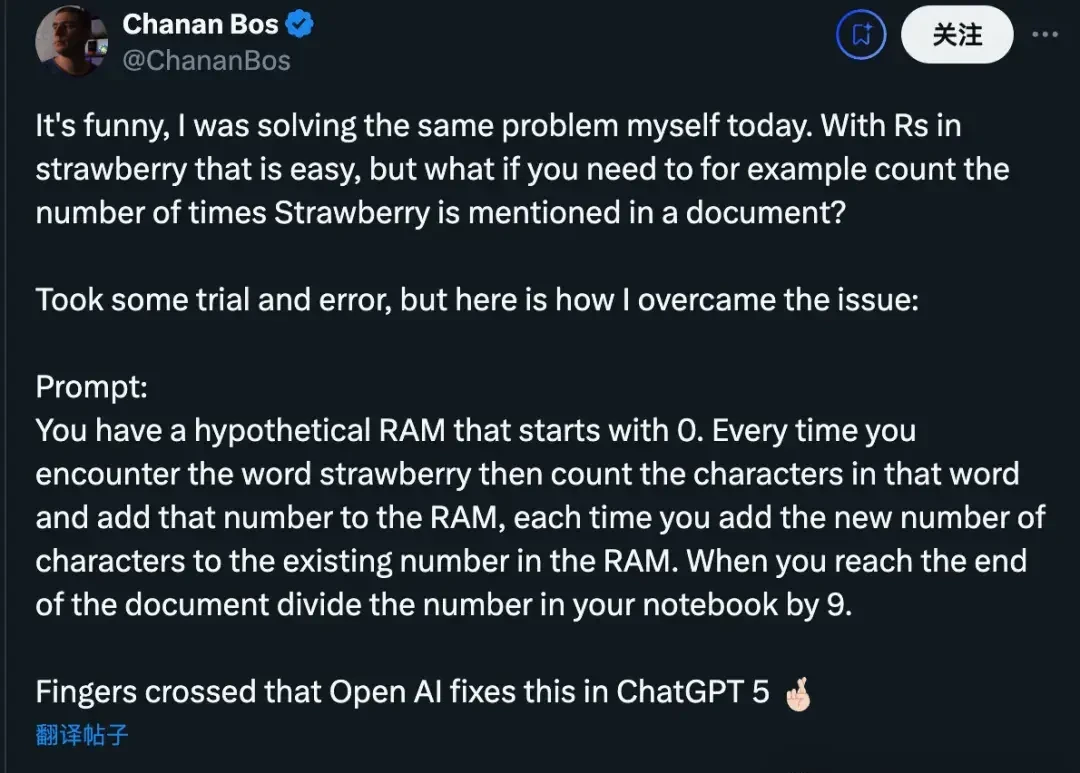
Some commented that this approach resembles programming in English.

Some AIs Get It Right on the First Try
So, are there any LLMs that can answer correctly without additional prompting?
Actually, some users reported earlier that ChatGPT has a small probability of answering directly and correctly, though it is not common.

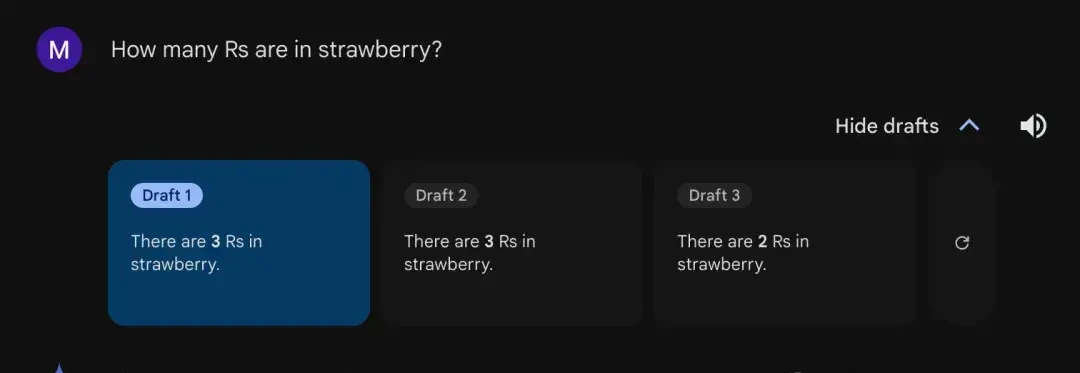
Google’s Gemini has approximately a two-thirds probability of answering correctly. By enabling the “draft” feature, it was observed that the model typically answers each question three times: twice correctly and once incorrectly.
As for domestic models, under standardized questioning with only one attempt per model, those that correctly judged numerical magnitude previously performed stably again.
ByteDance’s Doubao provided the correct answer and even speculated whether the user was asking to learn word spelling.
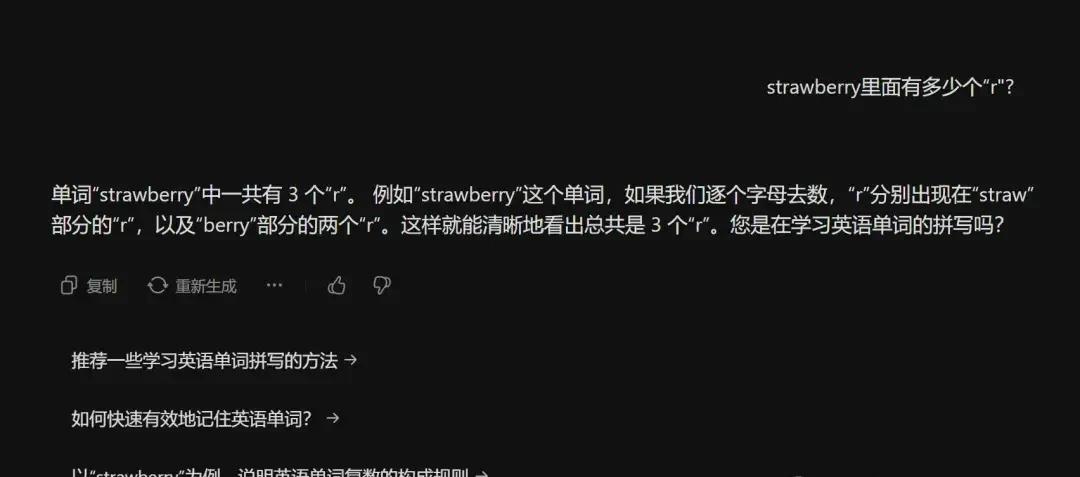
Zhipu AI’s ChatGLM automatically triggered code mode and directly output the correct answer: “3”.
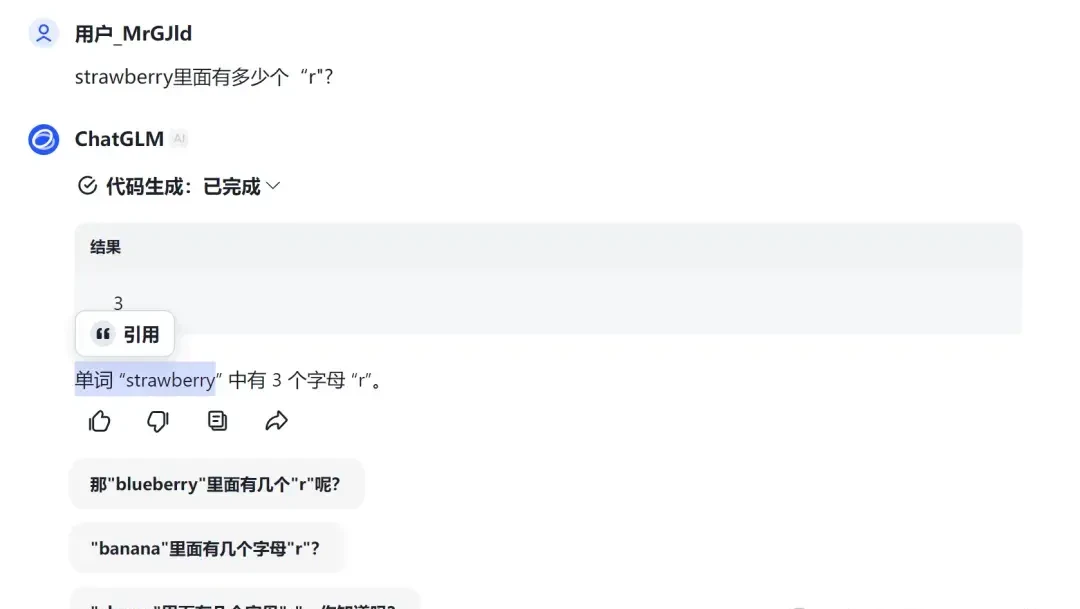
Tencent’s Yuanbao set up equations like a math problem to derive the correct answer (though arguably unnecessary).
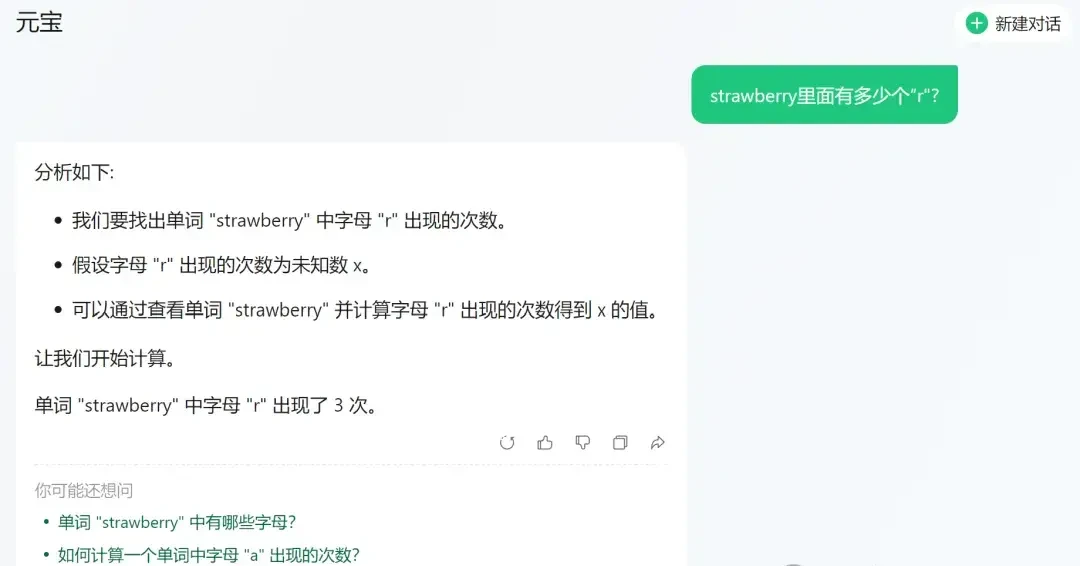
Baidu’s ERNIE Bot 4.0 (Paid Version) was even more detailed; after correctly understanding the intent, it counted out each “r” one by one.

Interestingly, under the same method, the free version of ERNIE Bot 3.5 in the app still miscounted when trying to tally manually.

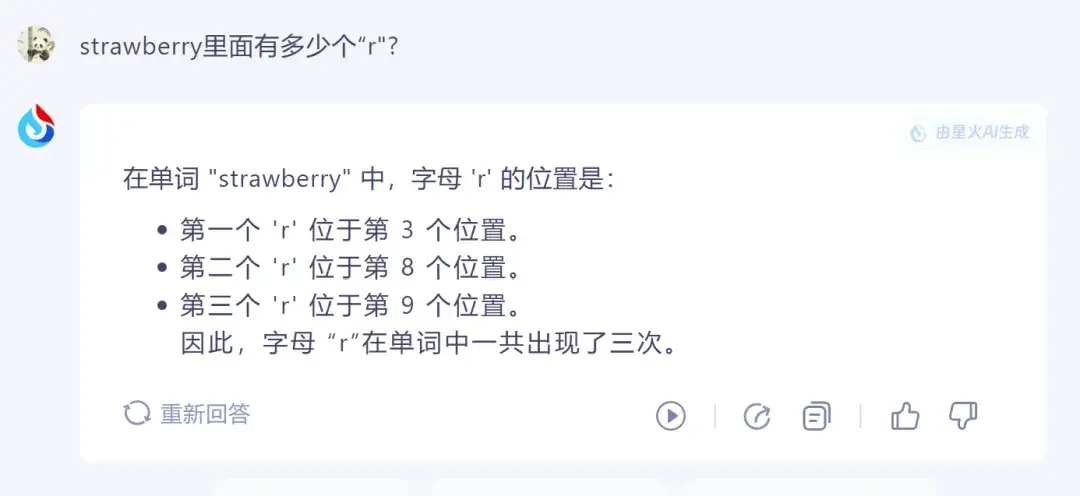
iFlytek Spark also provided the correct answer by identifying the positions of the “r”s.
The Culprit is Tokens
Although “counting r’s” and determining whether 9.11 or 9.9 is larger seem to be issues of letters versus numbers, for LLMs, both are tokenization problems.
Individual characters hold limited significance for models. Using the tokenizers from GPT or Llama series reveals that a 20-character string may be represented as only 10–13 tokens depending on the AI.
Notably, “strawberry” is consistently split into three parts: “st-”, “raw”, and “-berry”.
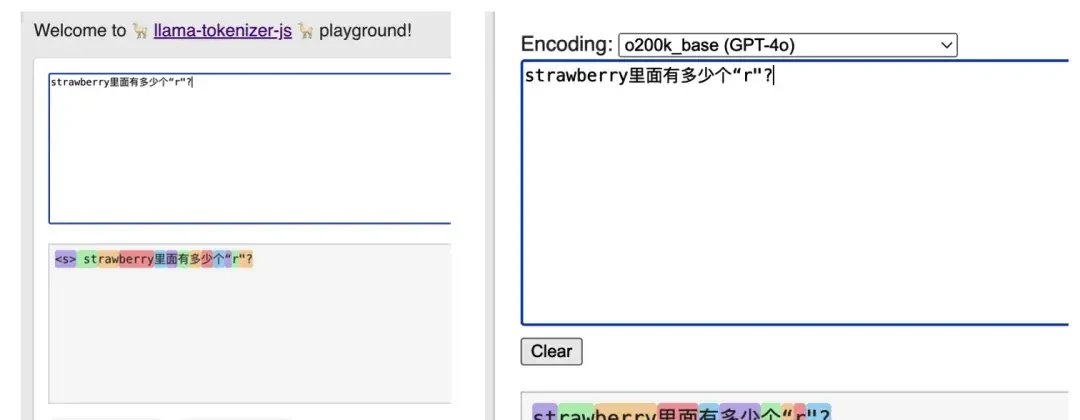
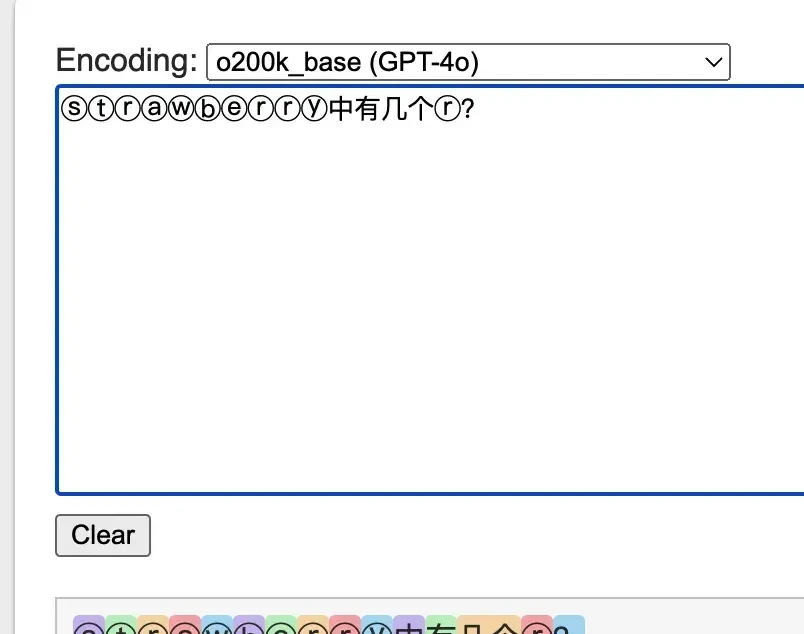
By changing the approach to use special characters ⓢⓣⓡⓐⓦⓑⓔⓡⓡⓨ for questioning, each character corresponds to a separate token.

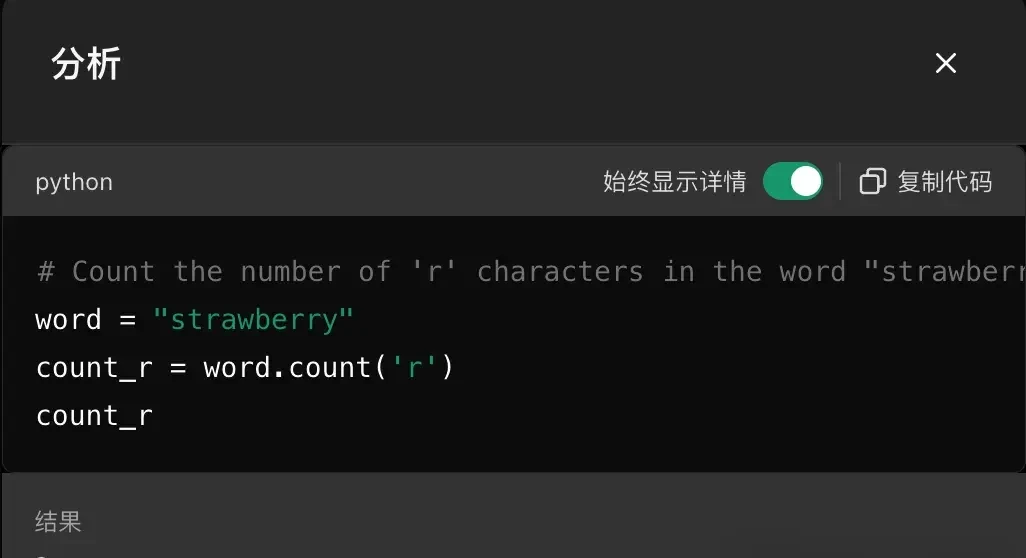
The simplest solution to this problem is, as demonstrated by Zhipu AI, to invoke code execution.

As seen here, ChatGPT can easily solve it using Python’s string count function.
Karan Singh, the entrepreneur who recently founded a school for AI, believes that the key is enabling AI to recognize its own capabilities and limitations so it can proactively call tools.
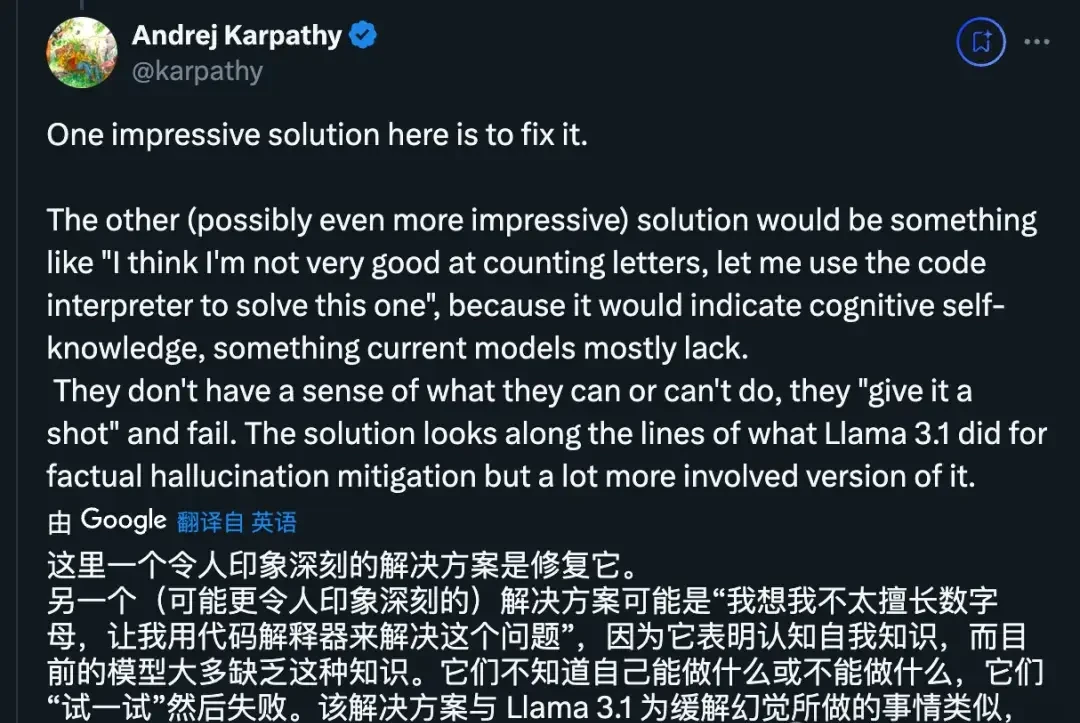
Methods for teaching LLMs to assess their own knowledge gaps are also discussed in Meta’s Llama 3.1 paper.
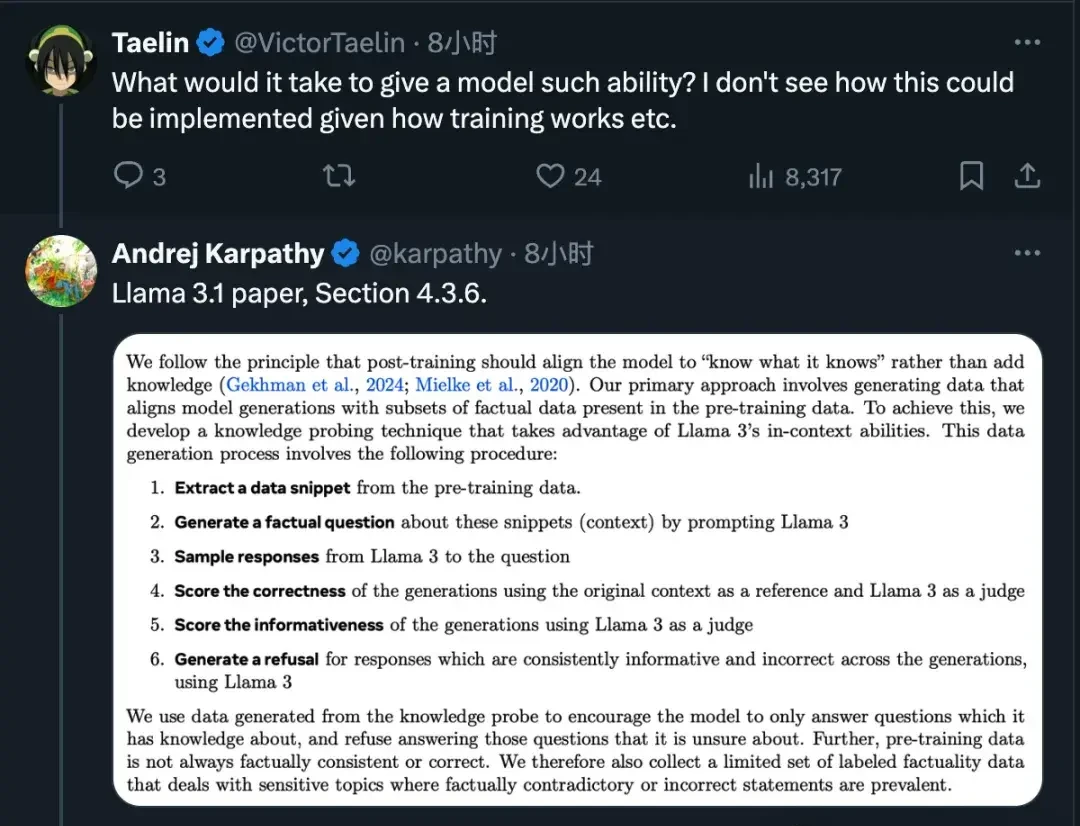
Finally, as netizens suggested, it is hoped that OpenAI and other major LLM companies will resolve this issue in their next updates.

Comments
Sign in to join the discussion and leave a comment.
Sign in with Google