Field Read: Multimodal AI for Physical World Understanding
I read the ECCV 2024 paper from Renmin University, BUPT, Shanghai AI Lab, and others on Ref-AVS. It’s a new method to locate objects using audio-visual-text cues. In the lab, this looks promising. On the factory floor? I’m skeptical about latency and noise robustness.
I think lab demos ignore ambient noise; real warehouses are loud. In the field, unit economics matter more than segmentation accuracy here. What I watch for is we need to see how it handles occlusion in cluttered spaces.

The Problem with Single-Modal Analysis
Existing research often approaches visual, textual, and audio cues independently. This single-modal analysis is insufficient for complex physical tasks. For example, how does a machine locate the person actually playing an instrument in a busy scene?
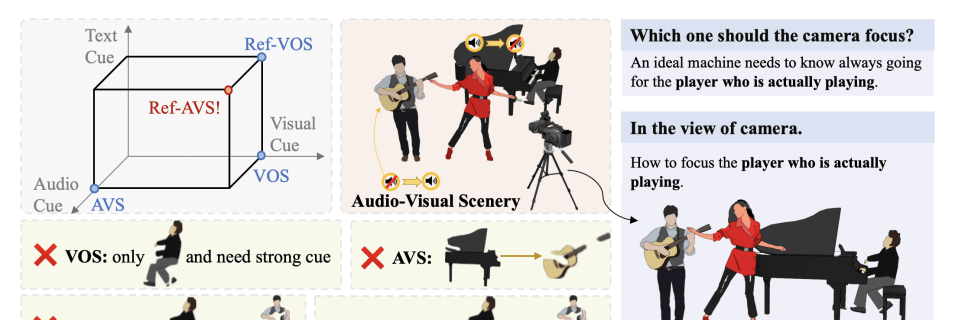
Current methods have clear limitations:
- Video Object Segmentation (VOS): Uses a mask from the first frame to guide subsequent frames. It heavily relies on precise annotations in that initial frame. If the first frame is wrong, the whole sequence fails.
- Referring Video Object Segmentation (Ref-VOS): Segments objects based on natural language descriptions instead of masks. While more accessible, its capabilities are limited compared to multimodal fusion.
- Audio-Visual Segmentation (AVS): Uses audio to segment sound-emitting objects. It cannot handle silent objects, which is a major gap for embodied AI.
Ref-AVS: Integrating Multiple Modalities
The new Ref-AVS method integrates relationships across multiple modalities—text, audio, and vision. This allows it to adapt to more realistic dynamic audio-visual scenes. Now, individuals singing while playing the guitar can be easily identified.

Furthermore, the same clip can be reused repeatedly to identify which guitar is currently being played. This reuse capability suggests potential efficiency gains in processing pipelines.

Dataset and Framework Details
Researchers constructed a dataset named Ref-AVS Bench to evaluate this approach. They also designed an end-to-end framework to efficiently process multimodal cues. The details of the architecture and benchmarks follow in the full paper accepted by ECCV 2024.
The Ref-AVS Bench Dataset: Ground Truth or Lab Fantasy?
I read through the construction details for the Ref-AVS Bench dataset, and what stands out is the sheer volume of manual labor required to make a model look smart on paper. We are looking at 40,020 video frames, 6,888 objects, and 20,261 reference expressions compiled by Renmin University, Beijing University of Posts and Telecommunications, and Shanghai AI Lab.
Each data point pairs audio with pixel-level annotations for every frame. To ensure the referenced objects aren’t just a narrow slice of reality, the team selected 52 categories: 48 sound-emitting objects and 3 static ones that don’t make noise.
I think pixel-level accuracy in a controlled dataset doesn’t translate to robustness on a cluttered factory floor.
Videos were sourced from YouTube and clipped to exactly 10 seconds. During this manual collection, the team deliberately avoided videos with specific characteristics: those with many identical semantic instances, extensive editing or camera switches, and synthetic content created via post-production.
In the field, cleaning out bad data is easy; cleaning up a robot’s perception in the wild is where the real cost lies.
To improve consistency with real-world distributions, they prioritized scene diversity, including interactions between multiple objects like instruments, people, and vehicles.
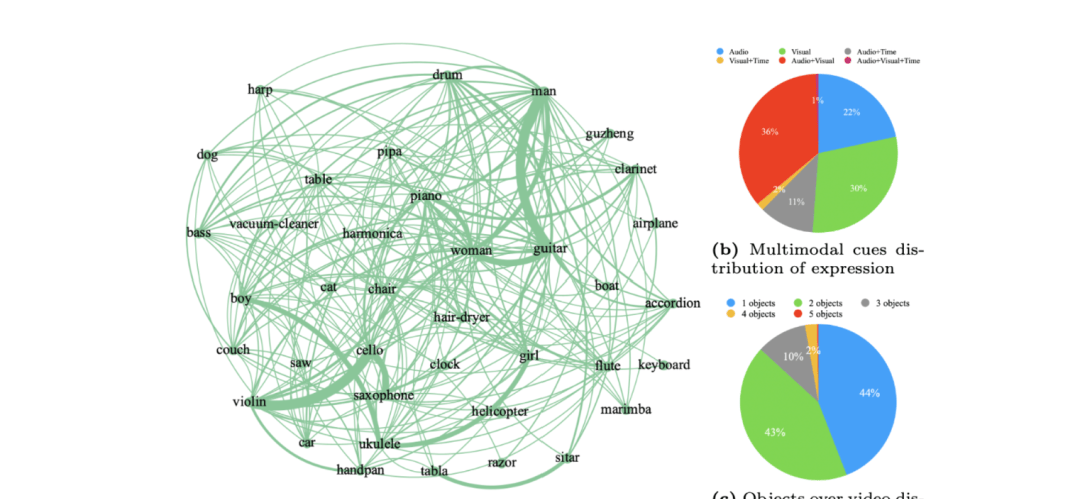
Diversity in expressions is another core element. Beyond basic text, these references incorporate auditory (volume, rhythm), visual (appearance, spatial properties), and temporal dimensions. The team used cues like “(object) that makes sound first” to create sequential hints.
What I watch for is temporal cues work fine until the robot encounters a noisy environment where timing is ambiguous.
By integrating these modalities, they designed expressions that reflect multimodal scenes while meeting precise referencing needs.
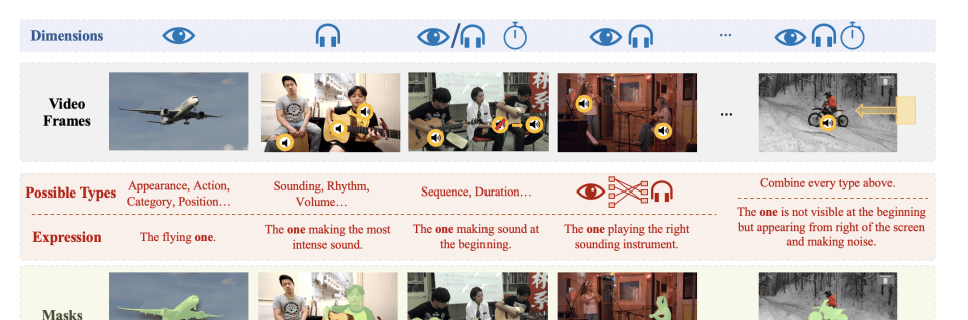
Accuracy of expressions was a core focus, governed by three rules for high-quality generation:
- Uniqueness: An expression must refer to a single unique object.
- Necessity: Every adjective must narrow the scope; no redundant descriptions.
- Clarity: Subjective templates like “the louder __” are only used when unambiguous.
The team split each 10-second video into ten one-second segments. They used Grounding SAM to segment and label key frames, which annotators then manually checked and corrected. This generated masks for multiple targets in key frames, after which tracking algorithms followed the objects across the full span to produce final mask labels (Ground Truth Masks).
I think relying on manual correction of algorithmic outputs is a bottleneck that won’t scale to real-time deployment.
For data splitting, test set videos and annotations were carefully reviewed by trained annotators. To evaluate performance comprehensively, the test set was divided into three distinct subsets:
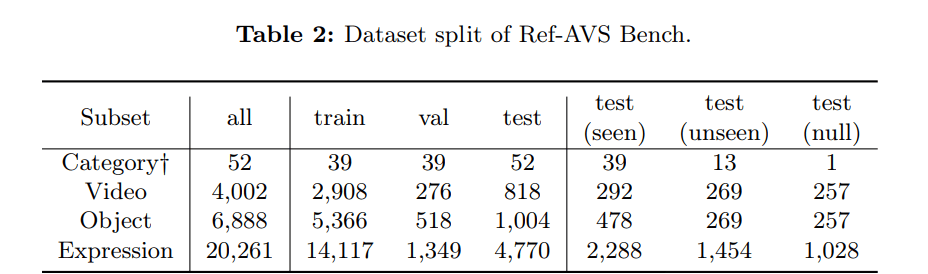
These subsets include:
- Seen Subset: Object categories from the training set, establishing baseline performance.
- Unseen Subset: Assesses generalization in unseen audio-visual scenarios.
- Null Subset: Tests robustness against null references unrelated to any object in the video.
The Mechanics Behind the Mask
I read through the implementation details of this new method from Renmin University, Beijing University of Posts and Telecommunications, and Shanghai AI Lab. What stood out to me was their attempt to force a static segmentation model to understand time. They call it Expression Enhancing with Multimodal Cues (EEMC), but at its core, they are just trying to make the AI pay attention to what happened three seconds ago versus now.
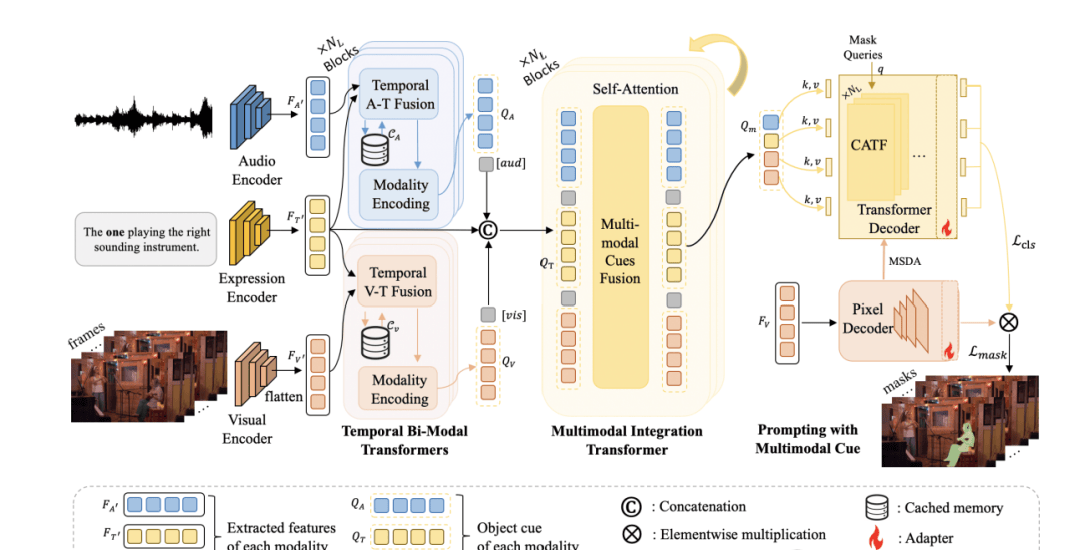
The team fused audio and visual modalities (FV, FA) with text (FT) inside a Temporal Bi-Modal Transformer. To handle the “when” rather than just the “what,” they introduced a Cached Memory mechanism (CV, CA). This isn’t magic; it’s a simple running average of features up to the current moment $t$.
In the field, lab models love averaging data because noise disappears in the mean. Real robots need to react to sudden changes, not smoothed-out history.
The math relies on an adjustable hyperparameter $\alpha$ to control sensitivity. If the audio or visual input hasn’t changed much from the past average, the output stays flat. But if there is a spike, the cached memory amplifies that difference. It’s a basic delta detector wrapped in Transformer terminology.
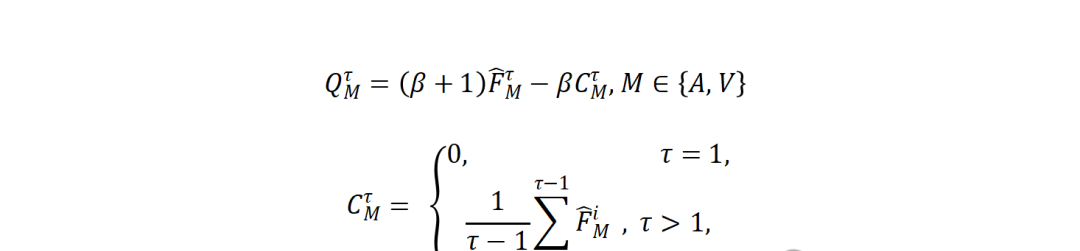
These concatenated features then feed into a Multimodal Integration Transformer to create $Q_M$. This is where the rubber meets the road for deployment. They didn’t build a new decoder from scratch; they plugged this logic into Mask2Former, using its pre-trained mask queries as $Q_{mask}$.
What I watch for is plugging new sensors into old decoders rarely fixes fundamental alignment issues in the wild. We’ve seen this “plug-and-play” claim fail when lighting changes.
They treat the multimodal features as keys ($K$) and values ($V$) for a cross-attention transformer (CATF). This allows the foundation model to segment based on these new audio-visual cues. It’s a clever hack, but I remain skeptical about how well this generalizes beyond their controlled dataset.
I think cross-attention works until the microphone picks up background noise that wasn’t in training. Unit economics matter more than architectural novelty here.
Field Reality Check
I read the quantitative results, but I’m looking for unit economics, not just accuracy scores on a benchmark. In the field, lab metrics don’t pay for compute or fix hardware failures in the real world.
The team compared their baseline against other methods, supplementing missing modality information to ensure fairness in these quantitative experiments. On the Seen subset, the new Ref-AVS method outperforms other methods. Simultaneously, on the Unseen and Null subsets, Ref-AVS demonstrated generalizability and could accurately follow reference expressions.
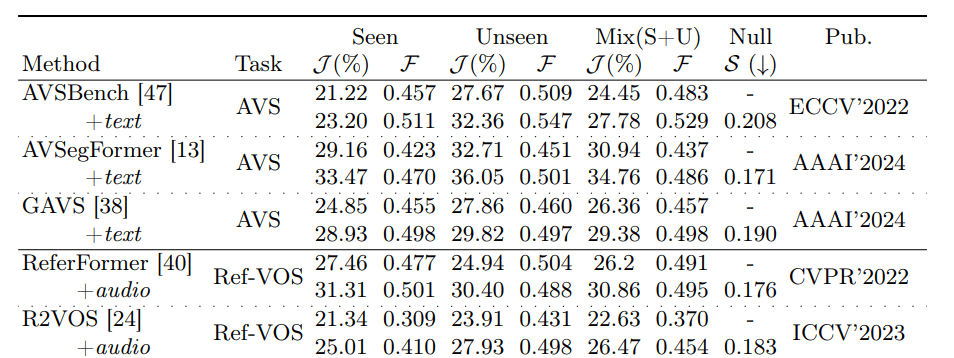
Where It Actually Breaks
I followed the release, and while the numbers look clean, the qualitative errors reveal where these models still fail in messy environments. What I watch for is a model that can’t distinguish a vacuum from a child is a liability, not a feature.
In qualitative experiments, the team visualized segmentation masks on the Ref-AVS Bench test set and compared them with AVSegFormer and ReferFormer.
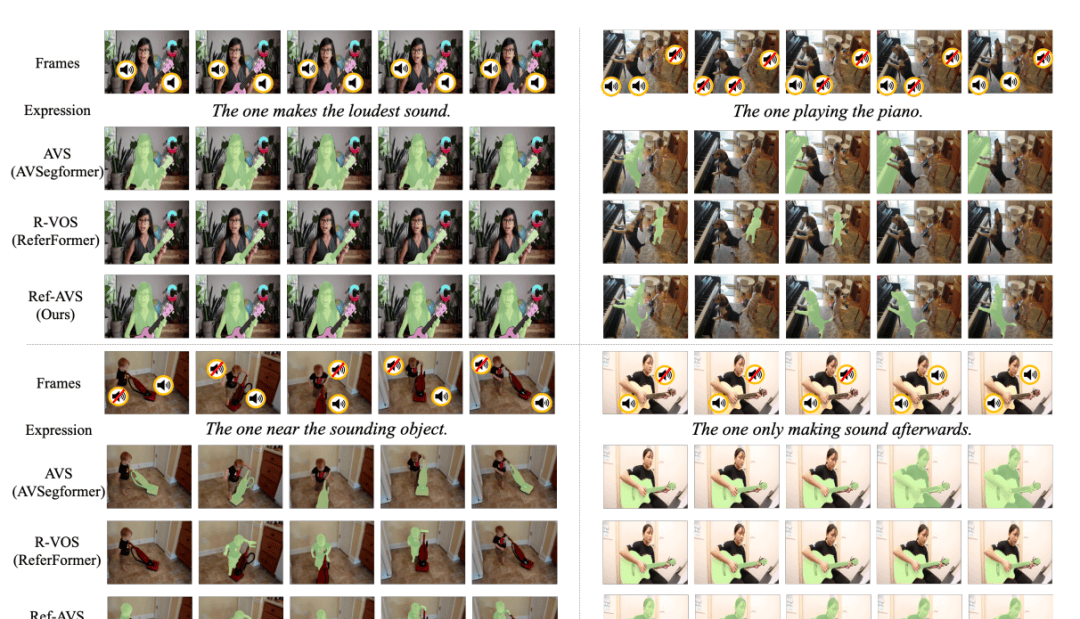
The results show that ReferFormer’s performance in Ref-VOS tasks and AVSegFormer’s performance in AVS tasks both failed to accurately segment the objects described in the expressions. Specifically, AVSegFormer struggled with understanding expressions, often directly generating masks for sound sources. For example, in the bottom-left sample, AVSegFormer incorrectly segmented the vacuum cleaner as the target instead of the boy. On the other hand, Ref-VOS may fail to fully comprehend audio-visual scenes, thereby misidentifying a toddler as a piano player, as shown in the top-right sample.
In contrast, the Ref-AVS method demonstrated superior capabilities, handling both multimodal expressions and scenes simultaneously, thus accurately understanding user instructions and segmenting target objects.
The Deployment Gap
I’m skeptical about “real-time applicability” claims until we see latency benchmarks on edge hardware, not just server-side throughput. I think we need robust navigation, not just pretty segmentation masks for a paper.
In the future, higher-quality multimodal fusion techniques, real-time applicability of models, and dataset expansion and diversification could be considered to apply multimodal referring segmentation to challenges in video analysis, medical image processing, autonomous driving, and robot navigation.
For more details, please refer to the original paper.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google