The “Reverse Curse” of Large Models Solved by Replacing Autoregression with Diffusion Models
The Institute for AI (AIIS) at Renmin University of China and Ant Group have jointly proposed LLaDA (Large Language Diffusion with mAsking).
LLaDA-8B demonstrates capabilities in in-context learning that are comparable to LLaMA3-8B, while surpassing GPT-4o in reverse poetry tasks.
In the field of large language models, reverse poetry is a specialized task used to evaluate a model’s ability to handle bidirectional dependencies and logical reasoning within language models. For example, it asks the model to generate the preceding line for “A row of white egrets ascends into the blue sky.”
Typically, autoregressive models (such as GPT) perform suboptimally when inferring previous text from subsequent context. This is because the fundamental principle of autoregressive models is to use preceding elements in a sequence to predict the current element—i.e., predicting the next token.

In contrast, LLaDA is a bidirectional model based on diffusion models, which naturally captures bidirectional dependencies in text more effectively.
The authors state in the abstract that LLaDA challenges the inherent connection between key capabilities of Large Language Models (LLMs) and autoregressive models.
These findings have sparked considerable discussion.
Some observers have asked:
Are we reconstructing masked language model modeling?

Could this paradigm also perform better in RAG and embedding similarity search?

Notably, LLaDA was trained on 2.3 trillion tokens of corpus using only 130,000 H800 GPU hours, followed by Supervised Fine-Tuning (SFT) on 4.5 million token pairs.
Forward Masking + Reverse Prediction
The core question posed by the paper is: Is autoregression the only path to achieving LLM intelligence?
After all, current LLMs based on the autoregressive paradigm still suffer from numerous drawbacks. For instance, the mechanism of generating tokens one by one leads to high computational costs, and left-to-right modeling limits performance in reverse reasoning tasks. These factors constrain the ability of LLMs to handle longer and more complex tasks.
To address this, they proposed LLaDA. Through a forward masking and reverse prediction mechanism, the model better captures bidirectional dependencies in text.

The study adopts standard data preparation, pre-training, Supervised Fine-Tuning (SFT), and evaluation processes to scale LLaDA to 8 billion parameters. It was pretrained from scratch on 2.3 trillion tokens using 130,000 H800 GPU hours, followed by SFT on 4.5 million data pairs.
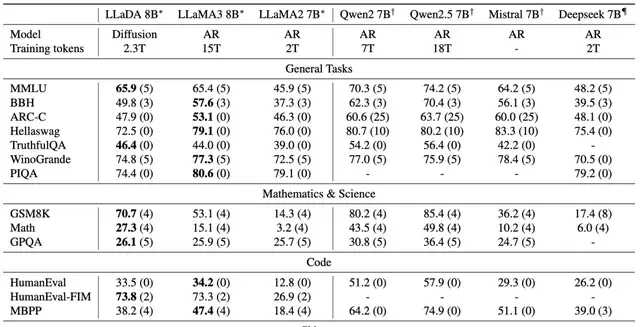
Performance across diverse tasks including language understanding, mathematics, coding, and Chinese is as follows:
Strong Scalability: LLaDA can effectively scale to $10^{23}$ FLOPs of computational resources. On six tasks (such as MMLU and GSM8K), it achieves results comparable to self-built autoregressive baseline models trained on the same data.
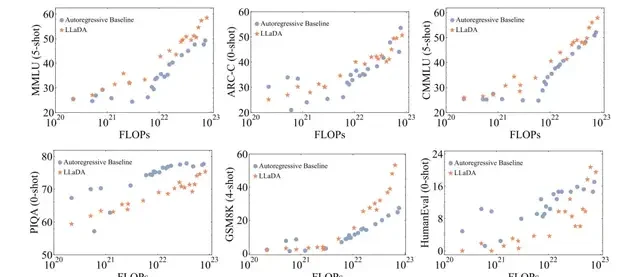
In-Context Learning: Notably, LLaDA-8B surpasses LLaMA2-7B in almost all 15 standard zero-shot/few-shot learning tasks and performs comparably to LLaMA3-8B.
Instruction Following: LLaDA significantly enhances instruction-following capabilities after SFT, as demonstrated in case studies such as multi-turn conversations.
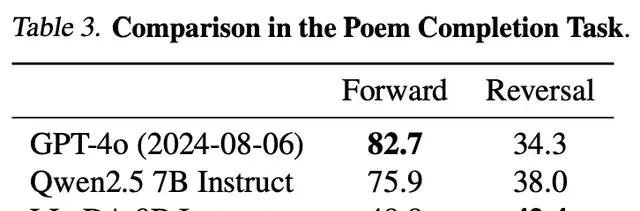
Reverse Reasoning: LLaDA effectively breaks the reverse curse, performing consistently on both forward and reverse tasks. Specifically, in the reverse poetry completion task, LLaDA outperforms GPT-4o.
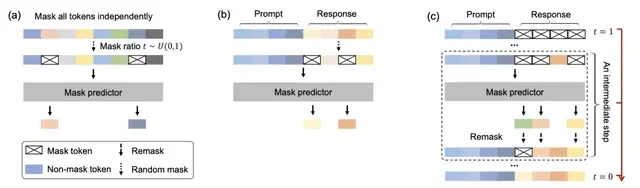
LLaDA uses a Transformer architecture as a masked predictor. Unlike autoregressive models, LLaDA’s Transformer does not use causal masking (Causal Mask), allowing it to see all tokens in the input sequence simultaneously.
While its parameter count is comparable to traditional large language models like GPT, architectural details (such as multi-head attention settings) differ slightly to accommodate masked prediction tasks.
Its forward masking process works as follows:
LLaDA employs a random masking mechanism. For an input sequence $x_0$, the model randomly selects a certain proportion of tokens to mask, generating a partially masked sequence $x_t$. The probability of each token being masked is $t$, where $t$ is sampled uniformly from [0,1]. This differs from traditional fixed masking ratios (such as 15% in BERT); LLaDA’s random masking mechanism demonstrates better performance on large-scale data.
The model’s objective is to learn a masked predictor capable of predicting the masked tokens based on the partially masked sequence $x_t$. During training, the model calculates loss only for the masked tokens.
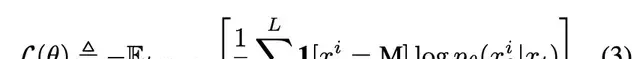
Where $1[\cdot]$ is an indicator function, signifying that loss is calculated only for masked tokens.
In the SFT phase, LLaDA uses supervised data (such as dialogue pairs and instruction-response pairs) to further optimize the model, improving its performance on specific tasks. For each task, the model fine-tunes based on the characteristics of the task data. For example, in conversational generation tasks, the model learns how to generate appropriate responses given a conversation history.
During SFT, the model selectively masks response tokens based on task-specific data characteristics, enabling it to better learn task-relevant patterns.
For inference, in generative tasks, LLaDA generates text through a reverse sampling process. Starting from a fully masked sequence, it progressively predicts the masked tokens until complete text is generated.
During sampling, LLaDA employs various strategies (such as random remasking, low-confidence remasking, and semi-autoregressive remasking) to balance generation efficiency and quality.
In conditional probability evaluation tasks, LLaDA assesses the model’s conditional probability based on a given prompt and partially masked response. This allows LLaDA to be evaluated across various benchmark tasks.
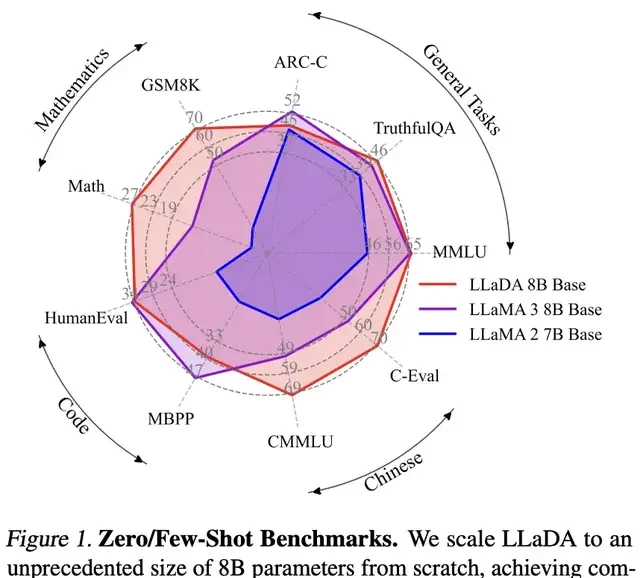
The performance of pre-trained LLMs on different benchmarks is as follows.
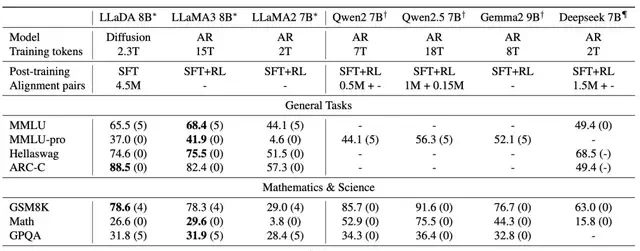
Performance on different benchmarks after post-training is shown below. Note that LLaDA underwent only SFT, while other models underwent additional Reinforcement Learning alignment.
In reverse poetry tasks, LLaDA surpassed GPT-4o.
LLaDA’s performance in multi-turn dialogue tasks is shown below. Darker colors indicate tokens predicted in the later stages of sampling, while lighter colors indicate tokens predicted in the early stages.

Netizens: Looking Forward to Practical Application
The research team also released some practical demonstrations of LLaDA.
It can solve standard mathematical reasoning problems.

It handles programming problems well too.

A foreign netizen commented: This will certainly push Chinese AI research to focus more on smaller models. However, this does not mean they are abandoning scaling laws.

Others have suggested that this might open up possibilities for hybrid models.

Some also mentioned that Meta has conducted similar work combining Transformers and diffusion.

Of course, some expressed concern that many architectures surpassing Transformers have been proposed previously, yet none have been truly adopted by academia or industry.
Let’s wait and see what happens next.

This research was jointly conducted by the Institute for AI at Renmin University of China and Ant Group. The corresponding author is Chongxuan Li, currently an Associate Professor (Tenure-Track) at the Institute for AI, Renmin University. His current focus is on deep generative models: understanding the capabilities and limitations of existing models to design effective and scalable next-generation architectures.
Paper Link:
https://arxiv.org/abs/2502.09992
Project Homepage:
https://ml-gsai.github.io/LLaDA-demo/