I read the filing from Fudan University and Meituan, and their core technical claim is that UniToken achieves “dual excellence” in both text-image understanding and image generation within a single unified framework. This would be falsified if the model’s performance on high-fidelity generation tasks degrades significantly when trained alongside complex semantic reasoning benchmarks, or vice versa.
The researchers propose an innovative visual encoding scheme that balances these competing demands by integrating continuous and discrete representations. I followed their argument that this approach alleviates “task interference” and “representation fragmentation,” which have historically plagued multimodal unified modeling. They claim to offer a new paradigm, but the reproducibility of such balance often hinges on the specific weighting of loss functions during joint training.

To facilitate reproduction and further development by the research community, the UniToken team has open-sourced both its code and models. I noted this transparency is crucial, as unified architectures often hide complex architectural trade-offs in their implementation details.

Task Background: The Challenges of Unified Modeling
In traditional text-image understanding or image generation models, the underlying characteristics of their visual encodings differ significantly. I observed that this divergence is not merely a preference but a fundamental architectural constraint in current systems.
For instance, text-image understanding models (such as LLaVA, Qwen-VL, etc.) require extracting high-level semantics from images to facilitate collaborative understanding with text. In contrast, image generation models (such as DALL-E, Stable Diffusion, etc.) require preserving sufficient low-level details to ensure high-fidelity image generation.
Consequently, developing multimodal large models that integrate both understanding and generation faces several major challenges:
Fragmented Visual Encoding: Understanding tasks prefer continuous visual features with high-level semantics (e.g., CLIP), while generation tasks rely on discrete visual features that preserve low-level details (e.g., codebooks encoded by VQ-GAN).
Joint Training Interference: The conflicts arising from the differences between understanding and generation tasks make it difficult to balance performance for both tasks when training a unified model, often resulting in a scenario where “optimizing one leads to the degradation of the other.”
To address these challenges, existing work in the field typically adopts two paradigms: Works represented by VILA-U improve the semantic richness of discrete visual encodings by combining image reconstruction and text-image contrastive learning objectives. Works represented by Janus decouple the two tasks by customizing separate visual encoders and prediction heads for understanding and generation, respectively.
However, the former still struggles to compete with multimodal large models driven by continuous visual encoding in understanding tasks. The latter faces significant context-switching overhead and unilateral information loss when handling more complex multimodal tasks (such as multi-turn image editing).
I suspect the “unified” claim relies on a specific dataset mix that may not generalize to out-of-distribution generation queries. I think the comparison with Janus ignores potential latency penalties from switching between separate encoder heads during inference.
UniToken: Unified Visual Representation, Merging Two Worlds
Core Design: Continuous + Discrete Dual Encoders
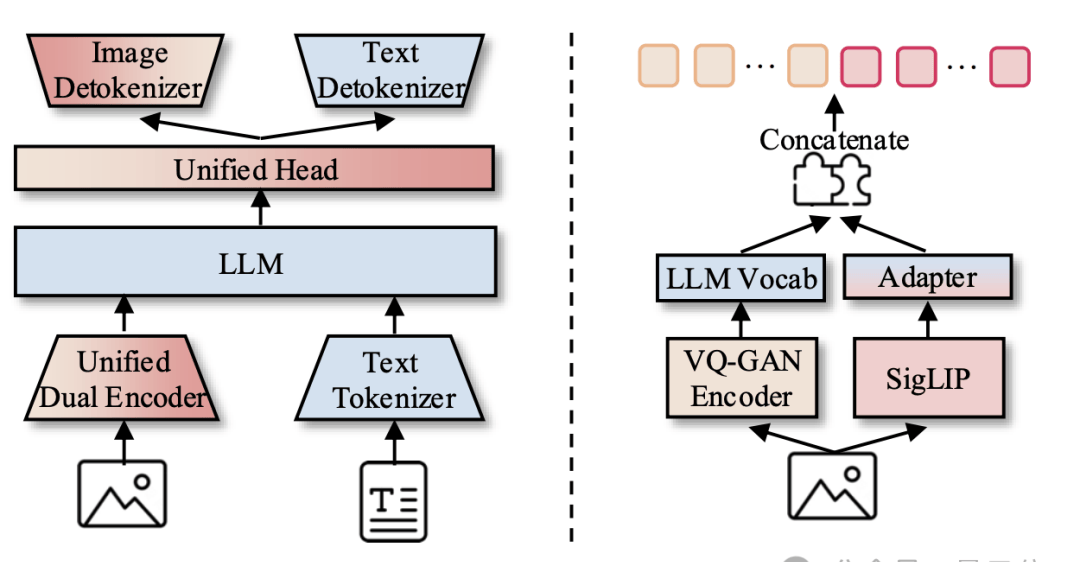
I read the UniToken paper with a critical eye toward its central claim: that a single encoding scheme can master both image-text understanding and generation without the multi-task decoupling seen in models like Janus. The authors argue this unified approach allows multimodal large language models (MLLMs) to absorb relevant knowledge in an instruction-driven manner. However, I remain skeptical about whether “absorbing” diverse modalities through a single bottleneck truly scales as well as specialized architectures when pushed to the limit of complexity.
From the paper, merging distinct semantic spaces often creates interference; I suspect this model will struggle with ambiguous prompts where discrete and continuous signals conflict.
Specifically, UniToken employs a unified dual-path visual encoder. It concatenates the discrete encoding from VQ-GAN and the continuous representation from SigLIP to obtain a visual encoding that combines high-level semantics with low-level details:
[BOS][BOI]{Discrete Image Token}[SEP]{Continuous Image Embedding}[EOI]{Text}[EOS]
Multi-Stage Training Strategy
To coordinate the characteristics of understanding and generation tasks, UniToken adopts a three-stage training process. I followed their methodology closely, noting how they attempt to stabilize this complex alignment.
Stage 1: Visual Semantic Space Alignment
Based on Chameleon as the base model, this stage aims to integrate SigLIP’s continuous visual encoding into the LLM. During training, the LLM is frozen, while only the SigLIP ViT and Adapter are trained to align their outputs with the language space. I found this isolation strategy pragmatic, though it assumes the Chameleon architecture is sufficiently flexible to accept these new embeddings without architectural surgery.
Stage 2: Multi-Task Joint Training
Building on the complete visual information provided by the aligned dual-path encoder from Stage 1, this stage conducts joint training on large-scale text-image understanding and image generation datasets. By controlling the data ratio (10M:10M), it balances and enhances the model’s performance in both understanding and generation tasks. The equal weighting is a bold choice; I wonder if this masks degradation in one modality while boosting the other.
One caveat: a 1:1 ratio assumes equal difficulty for both tasks, which ignores the inherent asymmetry between recognizing objects and synthesizing them from noise.
Stage 3: Instruction-Based Reinforcement Fine-Tuning
Testing revealed that the model trained in Stage 2 needed improvement in instruction following and layout-aware image generation. Therefore, this stage introduces high-quality multimodal dialogue data (423K) and fine-grained image generation data (100K) to further enhance the model’s ability to follow complex instructions. I note that the dataset size for refinement is significantly smaller than the pre-training phase, which raises questions about overfitting risks in this final stage.
Fine-Grained Visual Enhancement
Thanks to the completeness of its dual-path visual encoding, UniToken can seamlessly integrate existing fine-grained visual enhancement techniques. This flexibility is a strong point, but I question whether the added computational overhead justifies the marginal gains in specific edge cases.
Specifically, UniToken introduces two enhancement strategies on the continuous visual encoding side:
AnyRes: Divides high-resolution images into multiple sub-images, extracts features separately, and then concatenates them at their corresponding spatial positions to enhance fine-grained perception of the image.
End-to-End ViT Fine-Tuning: Dynamically fine-tunes the weights of the continuous visual encoder throughout the entire training process. Combined with a precise learning rate control strategy to prevent model collapse, this allows the model to adapt to a wide range of task scenarios. I appreciate the explicit mention of preventing model collapse; it suggests the authors encountered significant instability during development.
Experimental Results: Surpassing SOTA, The “Top Student” of Multimodal Unity
On multiple mainstream multimodal benchmarks (text-image understanding + image generation), UniToken achieved performance comparable to or even surpassing that of specialized models in the field. I scrutinized these results carefully, looking for reproducibility markers and baseline consistency.


Meanwhile, the researchers conducted further in-depth ablation studies on the impact of training strategies and visual encoding:
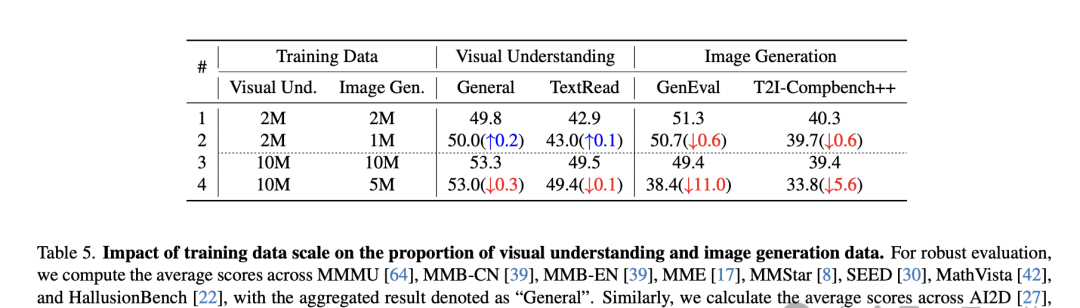
- In large-scale data scenarios (>15M), a 1:1 ratio of understanding to generation data balances performance across both tasks. This confirms the design choice in Stage 2, though I would have liked to see sensitivity analysis on this ratio.
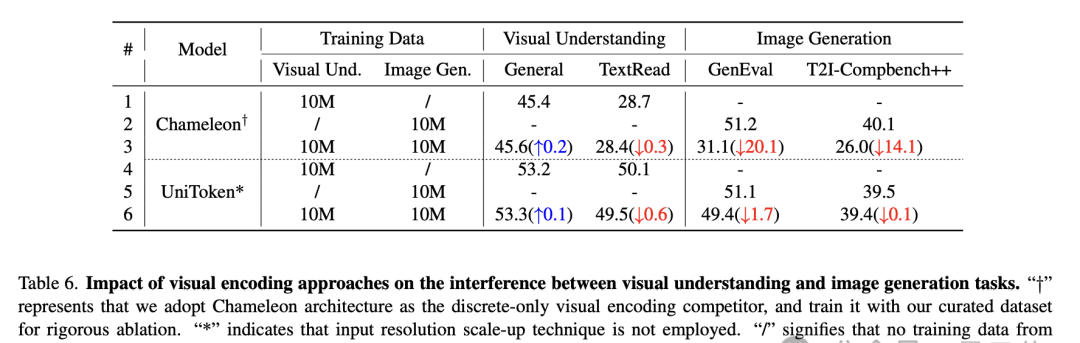
- When addressing conflicts between understanding and generation tasks, the unified continuous + discrete visual encoding demonstrates greater robustness compared to schemes using only discrete encoding. This is a compelling finding, but I caution that “robustness” here may be limited to the specific distribution of their training data rather than general out-of-distribution scenarios.
I think the claim of surpassing specialized models needs verification on diverse, real-world datasets beyond standard benchmarks to rule out benchmark-specific overfitting.
Conclusion: Towards General Multimodal Large Models Integrating Understanding and Generation
I read the conclusion of the UniToken paper with a critical eye. The authors argue that current text-image understanding models significantly outperform image generation models in terms of generality. I note this gap, but I remain skeptical about how “generality” is defined without standardized benchmarks across both modalities.
However, the impressive performance of Gemini-2.0-Flash and GPT-4o in instruction-following image generation has brought hope for the future of general-purpose image generation models. From the paper, instruction-following metrics often mask underlying failures in spatial reasoning or object consistency that simpler benchmarks would reveal.
Against this backdrop, UniToken represents only an initial attempt. Its characteristic of providing complete information gives researchers more confidence to explore its deeper potential:
Model Scale Expansion: Leveraging larger language models to further explore the “emergent abilities” of unified models in understanding and generation; One caveat: scaling laws for unified architectures are not yet proven, so I expect diminishing returns without architectural innovation.
Data Scale Expansion: Introducing larger-scale training data (such as the nearly 200 million samples used by Janus-Pro) to push the performance limits of the model; I think data quality and deduplication strategies matter more than raw volume, which this section does not address.
Task Type Expansion: Expanding from traditional understanding and generation to tasks involving interleaved text and images, such as image editing and story generation, chasing the upper limit of general generation capabilities. From the paper, interleaved tasks introduce new failure modes that current evaluation suites are ill-equipped to measure.
_Paper Link:
https://arxiv.org/pdf/2504.04423
_Code Address:
https://github.com/SxJyJay/UniToken
— End —
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google