Can pre-trained large language models learn reasoning through self-play without introducing external data?
Researchers from Tsinghua University, the Institute for Artificial Intelligence (THUAI), and Pennsylvania State University have proposed a training method called “Absolute Zero.”
This approach enables large models to acquire reasoning capabilities by generating and solving tasks based on specific reasoning objectives.

In tests, models trained with “Absolute Zero” outperformed those trained using expert-labeled samples.
Notably, the “Absolute Zero” method requires training only in a code environment yet yields significant improvements in mathematical reasoning.

The research has sparked discussion on Reddit, with users reposting the findings and exclaiming: “Has self-evolving AI been unlocked?”

Self-Learning Through Problem Generation and Solving
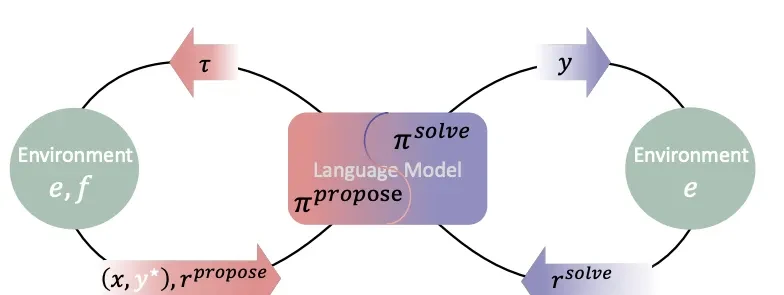
“Absolute Zero” employs a self-play learning paradigm. In this framework, a unified language model assumes two roles: Proposer and Solver.
The Proposer is responsible for generating new reasoning tasks, while the Solver tackles these tasks. Through the alternation and collaboration of these two roles, the model autonomously constructs a distribution of learning tasks and continuously enhances its reasoning capabilities during the solving process.
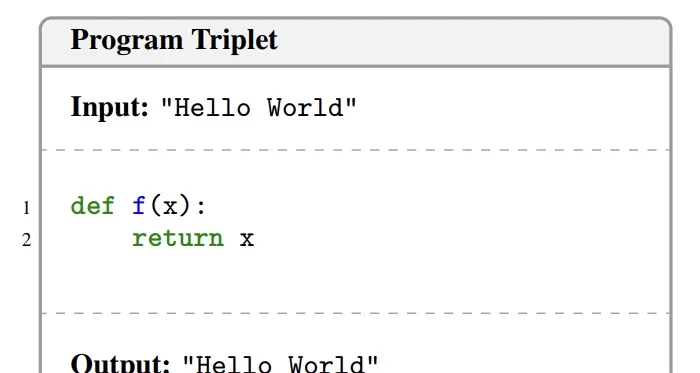
“Absolute Zero” represents all reasoning tasks uniformly as triplets of (program, input, output), denoted as $(p, i, o)$.
Here, the program is executable code, the input is the data fed into the program, and the output is the result produced by the program given that input.
Through this formalized representation, abstract reasoning tasks are transformed into concrete programming problems. Language models can generate and manipulate code to handle task generation and solving.
Based on whether $p$, $i$, and $o$ are known, “Absolute Zero” categorizes reasoning tasks into three basic types: Abduction, Deduction, and Induction:
-
Abduction Tasks: Given $p$ and the corresponding $o$, find possible values for $i$. These tasks assess the model’s ability to reverse-engineer conditions from results and understand code semantics.
-
Deduction Tasks: Given $p$ and $i$, determine $o$. These tasks evaluate the model’s ability to execute and comprehend code logic.
-
Induction Tasks: Given a set of $(i, o)$ examples, find a unified program $p$. These tasks test the model’s ability to summarize patterns and generate code.

Before self-play training begins, “Absolute Zero” requires an initial set of tasks as a seed (though this may be omitted if the base model is sufficiently strong). This seed set is generated by having the foundational language model produce valid code triplets $(p, i, o)$.
When the seed set is empty, “Absolute Zero” uses a predefined “zero triplet” as a starting point, which is essentially a simple identity function:
In each iteration, the Proposer first generates a new reasoning task based on the current existing task set and specified task type.
Specifically, it samples relevant examples from historical tasks as references, then leverages the language model’s generative capabilities to produce a new $(p, i, o)$ triplet.
-
For abduction tasks, $p$ and $o$ are generated, but not $i$.
-
For deduction tasks, $p$ and $i$ are generated, but not $o$.
-
For induction tasks, a set of input-output pairs $(i, o)$ is generated, but not $p$.
Additionally, for induction tasks, the Proposer samples a program $p$ from historical abduction and deduction tasks, then generates $N$ matching input-output pairs $(i, o)$ along with a natural language description.
This approach provides richer contextual information for induction tasks, helping the Solver better understand and resolve them.
During generation, the Proposer attempts to control the difficulty and novelty of new tasks to ensure they are both meaningful and challenging for the current Solver.
Specifically, “Absolute Zero” introduces the concept of “learnability” to estimate how much learning value a task holds for the current Solver model.
It calculates this by having the Solver attempt to solve the task and recording its success probability. If a task is too easy or too difficult, its learnability will be low. The Proposer’s goal is to generate tasks with moderate learnability.

The newly generated tasks are sent to an independent code executor for verification. The executor actually runs the program generated by the Proposer and checks if it meets the following conditions:
-
Syntax Correctness: The program executes normally in a Python interpreter without syntax errors.
-
Safety: The program does not use unsafe operations or libraries, such as file I/O or system calls.
-
Determinism: The program always produces the same output for identical inputs, with no randomness or uncertainty.
By passing these three checks, the executor filters out most invalid or harmful tasks.
For tasks that pass verification, the executor also calculates a “learnability reward” to provide feedback on the Proposer’s performance.
Finally, all verified tasks are stored in a task buffer pool for subsequent training use.
After filtering reasoning tasks, “Absolute Zero” switches to the Solver role to begin solving them. The specific approach varies depending on the task type:
-
For abduction tasks, the Solver infers possible values for $i$ given $p$ and $o$. This process resembles “reverse-executing” the program.
-
For deduction tasks, the Solver deduces $o$ from $p$ and $i$. The Solver must simulate the program’s execution to derive the final output.
-
For induction tasks, the Solver infers a possible program $p$ from input-output pairs $(i, o)$. The Solver needs to summarize general patterns from limited samples.
During task solving, the Solver can leverage existing knowledge in the language model (such as common algorithmic patterns and programming conventions) to assist in resolution.
The solutions generated by the Solver are verified again by the code executor. The executor checks whether the input, output, or program provided by the Solver truly satisfies the task requirements.
If satisfied, the task is considered successfully solved by the Solver, and a corresponding reward is granted; otherwise, it is deemed a failure, with no reward or a penalty applied.
This reward signal serves as feedback for the Solver’s behavior, helping it learn how to better solve various types of reasoning tasks.
Simultaneously, the Solver’s solutions are recorded as references for future generation and solving of similar tasks.
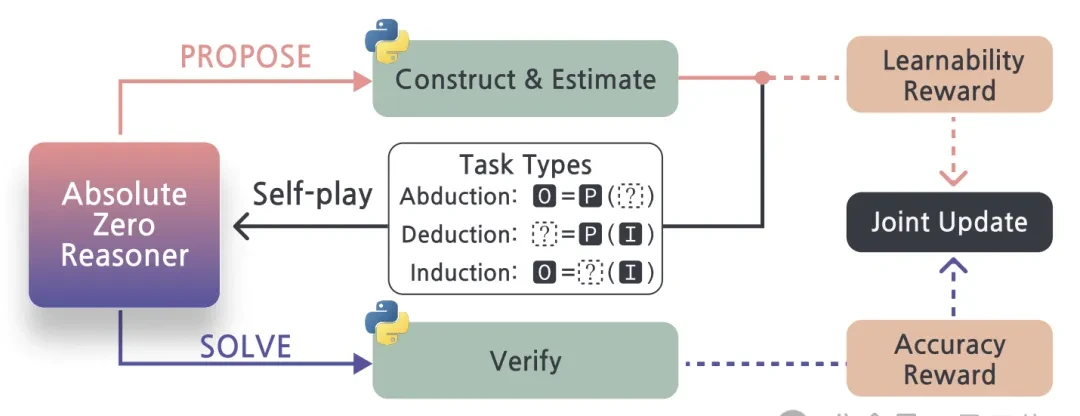
At the end of each iteration, “Absolute Zero” uses the feedback signals collected by both the Proposer and Solver to jointly optimize and update the entire model. This ensures that tasks generated by the Proposer are more conducive to learning, while the Solver’s ability to solve tasks becomes increasingly robust.
After multiple iterations, “Absolute Zero” eventually converges to a strong equilibrium point where the tasks generated by the Proposer perfectly match the Solver’s capabilities, and the Solver can acquire sufficient knowledge from these tasks.
Dual Improvement in Coding and Mathematical Reasoning Performance
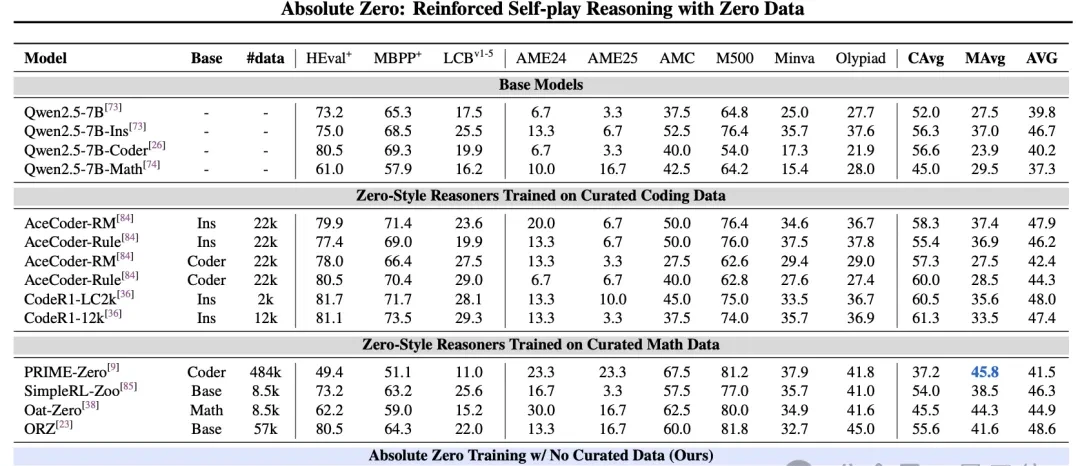
For coding tasks, researchers used three datasets: HumanEval+, MBPP+, and LCB.
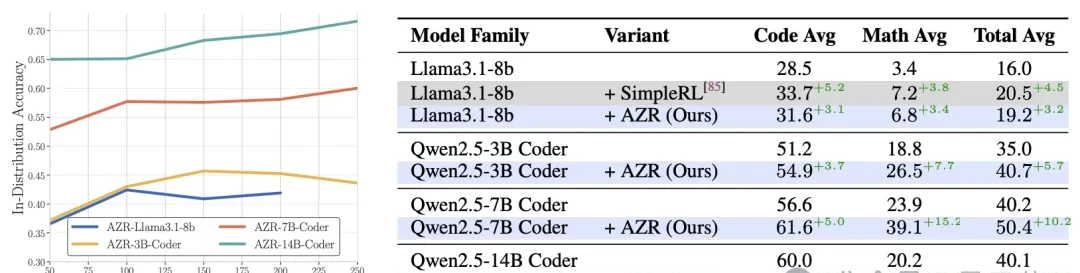
Compared to versions not trained with “Absolute Zero,” this method increased Qwen-2.5-7B-Coder’s pass rate on HumanEval+ from 80.5% to 83.5%, on MBPP+ from 69.3% to 69.6%, and on LCB from 19.9% to 31.7%.
For mathematical reasoning tasks, researchers selected six representative datasets for evaluation: AME’24, AME’25, AMC’23, MATH500, Minerva, and Olympiad.
“Absolute Zero” achieved an average accuracy of 39.1% across these six datasets, a 15.2 percentage point improvement over the baseline without “Absolute Zero.”
Specifically, on the MATH500 dataset, “Absolute Zero” reached an accuracy of 72.6%, surpassing the baseline by 22.6 percentage points; on the AMC’23 dataset, it achieved 57.5% accuracy, exceeding the baseline by 17.5 percentage points.
Beyond Qwen-2.5-7B-Coder, researchers tested “Absolute Zero” on several other pre-trained language models:
-
Qwen-2.5-3B-Coder: After applying “Absolute Zero,” the average pass rate for coding tasks increased from 51.2% to 54.9%, and the average accuracy for math tasks rose from 18.8% to 26.5%.
-
Qwen-2.5-14B-Coder: After applying “Absolute Zero,” the average pass rate for coding tasks increased from 60.0% to 63.6%, and the average accuracy for math tasks rose from 20.2% to 43.0%.
-
Llama-3.1-8B: After applying “Absolute Zero,” the average pass rate for coding tasks increased from 28.5% to 31.6%, and the average accuracy for math tasks rose from 3.4% to 6.8%.
Testing across different model sizes and types revealed that performance improvements with “Absolute Zero” are positively correlated with model scale—models with more parameters exhibit greater post-training gains.
For example, in math tasks, the 3-billion-parameter Qwen-2.5-3B-Coder improved by 7.7 percentage points, while the 14-billion-parameter Qwen-2.5-14B-Coder improved by 22.8 percentage points.
This indicates that “Absolute Zero” effectively leverages the capabilities of large models to achieve higher gains in reasoning performance.
Paper Link:
https://arxiv.org/abs/2505.03335
References
https://www.reddit.com/r/singularity/comments/1kgr5h3/selfimproving_ai_unlocked/