I read the Shanghai AI Lab paper because it claims to beat DeepSeek-R1-Distill-Qwen32B and OpenAI’s O1 series on math reasoning without using distillation. They started with Qwen2.5-32B-Base and used only fine-tuning and outcome-reward reinforcement learning (RL). This is a significant shift from the current industry habit of relying on distilled data from larger models.
The team identified a “triple bottleneck” that currently limits large language models in mathematical reasoning tasks:

- Sparse Reward Dilemma: Binary feedback on final answer correctness makes optimizing complex reasoning difficult.
- Local Correctness Trap: Partially correct steps in long chains of thought can mislead the model during learning.
- Scale Dependency Curse: Traditional distillation forces researchers into an “arms race” for parameter scale.
In practice, distillation is a shortcut that hides training instability; RL exposes it early. I think sparse rewards mean our on-call engineers will spend more time debugging edge cases in production.
Consequently, the research team re-examined current outcome-reward-based reinforcement learning algorithms. Through rigorous theoretical derivation and proof, they redesigned a new result-reward RL algorithm, arriving at three key conclusions:
- For Positive Samples: In a binary feedback environment, behavior cloning via Best-of-N (BoN) trajectory sampling is sufficient to learn the optimal policy.
- For Negative Samples: Reward reshaping is necessary to maintain consistency in the policy optimization objective.
- For Long Sequences: Different parts of a sequence contribute differently to the final result; therefore, a finer-grained reward allocation function is needed, which can be learned from outcome rewards.
In simple terms, by imitating correct samples, learning preferences from incorrect samples, and focusing on key steps, the team achieved remarkable results without relying on distillation from super-large models (such as DeepSeek-R1), using only reinforcement learning.
Operationally, finer-grained reward allocation increases inference latency if not optimized at the token level. In practice, this approach is shippable today for specialized math tasks, but general-purpose use requires more compute.
Additionally, the team conducted comparative analyses of RL training across different starting models. They found that both the starting model and the training data distribution significantly impact final performance. To promote fair comparison and further research within the community, the study team has fully open-sourced the RL training data, starting points, and final models. The project links are provided at the end of this article.
Designing Outcome-Reward Reinforcement Learning from Scratch
We’re looking at a new strategy optimization framework called OREAL from Shanghai AI Lab, designed to tackle the persistent headaches of sparse rewards and local correctness in math reasoning. Before they showed us how to do it better with experiments, they proved why this approach is theoretically superior. It’s a rigorous start that suggests this isn’t just another lab demo tweaking hyperparameters.
I think theoretical proofs are nice, but I need to see if the inference latency holds up under load. Sparse rewards usually mean expensive training runs; cost efficiency is my primary concern here.
Positive/Negative Sample Reward Reshaping: Solving the Sparse Reward Dilemma
The team’s theoretical analysis hit on a core insight regarding binary feedback mechanisms: the distribution of correct trajectories remains consistent regardless of how many Best-of-N (BoN) samples you draw containing the right answer. This means directly behavior-cloning sampled correct trajectories is actually the optimal setup for training on positive samples.
However, they noted that directly penalizing negative samples introduces gradient bias. To fix this, they analyzed the training gradients of both sample types and proposed a reward reshaping factor based on average accuracy ($p$). This maintains consistency with the learned BoN distribution and provides a theoretical basis for improving algorithms like GRPO. The result? The model absorbs successful experiences effectively while precisely identifying critical error boundaries.

Operationally, if this reduces the need for massive BoN sampling at inference time, it’s a win for latency. Otherwise, we’re just shifting compute costs from training to data generation.
Outcome Reward “Causal Tracing”: Escaping the Local Correctness Trap
For complex long-reasoning chains, OREAL introduces a token importance estimator. They constructed a cumulative sequence reward function to decompose outcome rewards backward to each reasoning step (see the token-level RM heatmap below). This method precisely locates core error steps, enabling more granular gradient updates during training and significantly improving model performance on long-sequence tasks.

The OREAL Framework
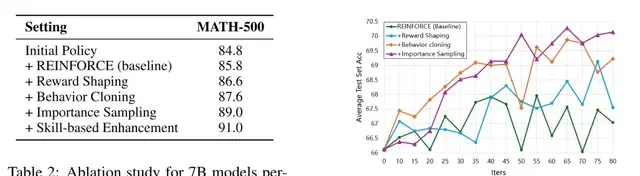
Combining these insights, the optimal reinforcement learning strategy can be summarized as: imitate learning on correct samples, preference learning on incorrect samples, and focused learning on key steps.
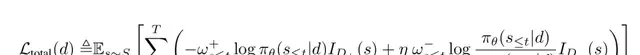
Through reasonable analysis and practice, the team pushed reinforcement learning performance to its optimal level step by step.
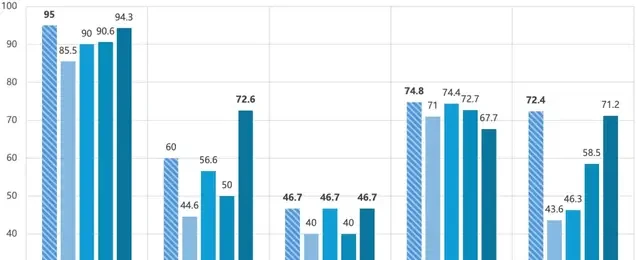
RL Beats Distillation: The Scale Dependency Curse is Broken
I read the Shanghai AI Lab release, and the production implication is immediate: you can now squeeze state-of-the-art math reasoning out of small models without relying on expensive distillation pipelines. This changes the cost structure for edge inference significantly.
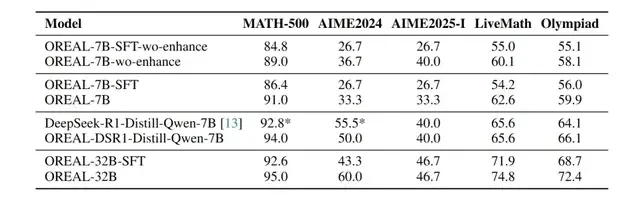
The team trained Oreal-7B and Oreal-32B using only 4,000 high-quality samples. At the 7B scale, Oreal-7B hit a pass@1 accuracy of 91.0 on MATH-500. This is the first time reinforcement learning (not distillation) has reached such precision. It sets a new milestone for RL methods and surpasses larger models like QWQ-32B-Preview and OpenAI-O1-Mini.
In practice, distillation requires massive compute clusters; RL on 4k samples is cheaper to iterate. I think small model inference reduces latency and eases on-call pressure for edge deployments.
They also applied Oreal to DeepSeek-r1-Distill-Qwen-7B, creating OREAL-DSR1-Distill-Qwen-7B. This new model achieved a pass@1 accuracy of 94.0 on MATH-500, setting a record for 7B models. The Qwen base model, after distillation from DeepSeek and subsequent RL training by Shanghai AI Lab, represents a significant leap in Chinese innovation.
For the 32B scale, Oreal-32B scored 95.0 on MATH-500. This surpasses the same-level DeepSeek-r1-Distill-Qwen-32B and achieves a new SOTA for 32B models.
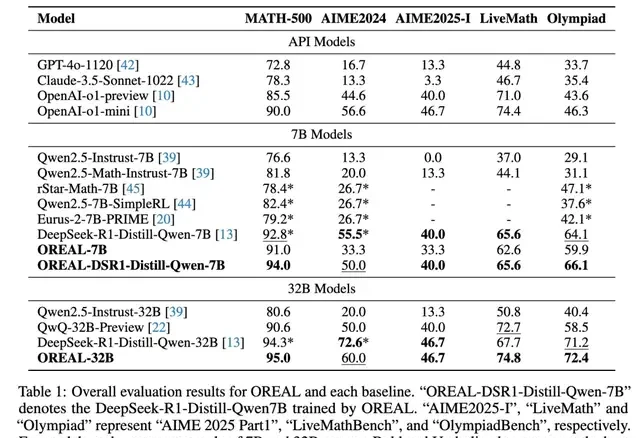
The Starting Point Matters More Than You Think
I followed the comparison across base models, and what stood out is that post-RL performance limits depend heavily on your starting point. Stronger initial models yield better results after RL.
While most benchmarks improved, there were exceptions. OREAL-32B stagnated on AIME 2025-I, and performance degraded compared to DSR1-Distill-Qwen-7B on AIME 2024. The researchers attribute this to insufficient preparation in training corpus quality, difficulty, and quantity.
Operationally, lab demos often hide the data curation cost required to prevent RL collapse. In practice, if your base model is weak, RL will amplify its flaws rather than fix them.
Beyond the algorithm, two factors are crucial for success:
- A strong starting model is a prerequisite for RL to effectively stimulate potential capabilities.
- The data used during RL must be guaranteed in quality, difficulty, quantity, and diversity. High-quality datasets allow models to leverage their potential through diverse challenges.
Open Source Everything to Fix the Comparison Problem
The team noted that while DeepSeek-R1 sparked enthusiasm, differences in training starting points, data, algorithms, and hyperparameters have hindered clear comparisons. To fix this, they have fully open-sourced the training data, starting models, and post-RL models. The training code will also be open-sourced to XTuner.
Welcome to download and experience:
Project Link:
https://github.com/InternLM/OREAL
Paper Address:
https://arxiv.org/abs/2502.06781
RL Training Data Link:
https://huggingface.co/datasets/internlm/OREAL-RL-Prompts
Series Model Address:
https://huggingface.co/collections/internlm/oreal-67aaccf5a8192c1ba3cff018
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google