The release of Alibaba’s Qwen3 technical report signals a strategic pivot in the Asia-Pacific AI landscape, moving beyond raw parameter wars toward architectural efficiency. By integrating distinct reasoning and non-reasoning modes into a single model, this move challenges Western-centric assumptions about specialized model silos and suggests a new path for cost-effective deployment across emerging markets.
I think this dual-mode approach could lower inference costs for APAC enterprises with tight budgets. From an APAC angle, the small RL dataset hints at a shift toward data quality over sheer volume globally. Globally, distilling large models to smaller ones accelerates local adoption in resource-constrained regions.

Unveiling the Qwen3 Architecture: Eight Models, One Strategy
I followed the release of the Qwen3 technical report, which details the engineering behind eight new models. What stood out to me immediately was the adoption of a dual-mode architecture. This allows a single model to handle both complex reasoning and standard non-reasoning tasks, switching automatically as needed. The training process relies on a phased strategy for fine-tuning, progressively building capabilities rather than jumping straight into deployment. Furthermore, Alibaba employs a “large guiding small” approach, distilling data from larger models to train the smaller ones in the family.
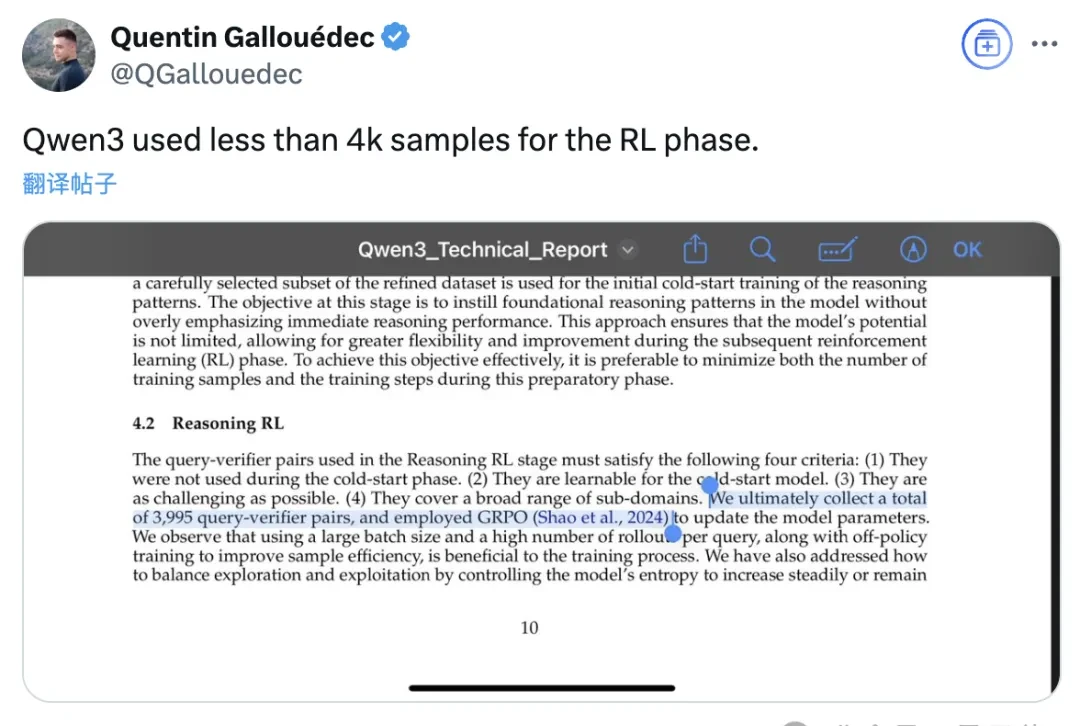
Readers who have already reviewed the report have identified additional highlights. For instance, a Hugging Face researcher noted that Qwen3’s sample size during the Reinforcement Learning (RL) phase was surprisingly low, totaling less than 4,000 samples.
One Model, Two Minds: Balancing Speed and Depth
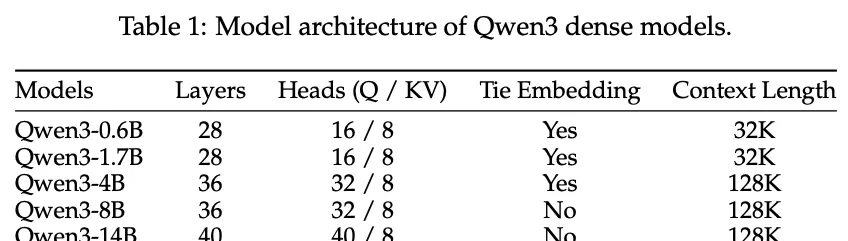
The Qwen3 series includes six dense models with parameter counts of 0.6B, 1.7B, 4B, 8B, 14B, and 32B; as well as two Mixture-of-Experts (MoE) models with total parameters of 30B and 235B, and activated parameters of 3B and 22B, respectively.
The architecture of the dense models is similar to Qwen2.5 but removes the QKV bias used in Qwen2 and introduces QK-Norm into the attention mechanism to ensure stable training for Qwen3.
Unlike Qwen2.5-MoE, Qwen3-MoE does not include shared experts. Additionally, Qwen3 employs a full-batch load balancing loss to promote expert specialization.

A core innovation of Qwen3 is its dual working mode: the integration of “thinking” and “non-thinking” modes, catering to the needs of complex reasoning tasks and rapid response tasks, respectively.
To enable flexible switching between these two modes, Qwen3 introduces the concept of a Thinking Budget.
The thinking budget is essentially a parameter that determines the amount of computational resources invested in thinking mode; its size is positively correlated with the complexity of the input question.
Upon receiving an input, the model evaluates its complexity and dynamically allocates the thinking budget.
Simple questions are assigned a lower thinking budget, prompting the model to provide answers quickly. Complex questions receive a higher thinking budget, allowing the model to invest more computational power in deep reasoning before generating a response.

How Qwen3 Was Trained
The architecture behind Alibaba’s latest model suggests a deliberate pivot toward hybrid reasoning capabilities. For global competitors, this signals that the race is no longer just about parameter count, but about how efficiently models toggle between deep analysis and rapid response. I followed the release notes closely to understand how they achieved this duality without sacrificing speed in non-thinking tasks.
I think hybrid models may reduce latency costs for enterprises demanding both creativity and precision. From an APAC angle, the reliance on human-verified steps highlights a bottleneck that pure RL might eventually solve.
Pre-training: A Three-Stage Foundation
During pre-training, Qwen3 adopted a three-stage strategy to progressively build and strengthen the model’s language understanding and generation capabilities.
The first stage aims to equip the model with basic language and general knowledge. This phase of training was conducted on general corpora using a sequence length of 4,096 tokens.
The second stage focuses on enhancing reasoning capabilities. It utilizes higher-quality data primarily sourced from STEM, programming, and reasoning domains.
Training on these datasets significantly improved the model’s logical analysis and causal reasoning abilities. While the sequence length remained at 4,096 tokens, the learning rate decayed faster during this phase.
The third stage concentrates on long-text capabilities, using high-quality long-document corpora specifically collected by the research team. The training sequence length was extended to 32,768 tokens.
Through training on these ultra-long texts, the model learned to handle complex long-range dependencies and mastered skills for integrating information across paragraphs and documents.

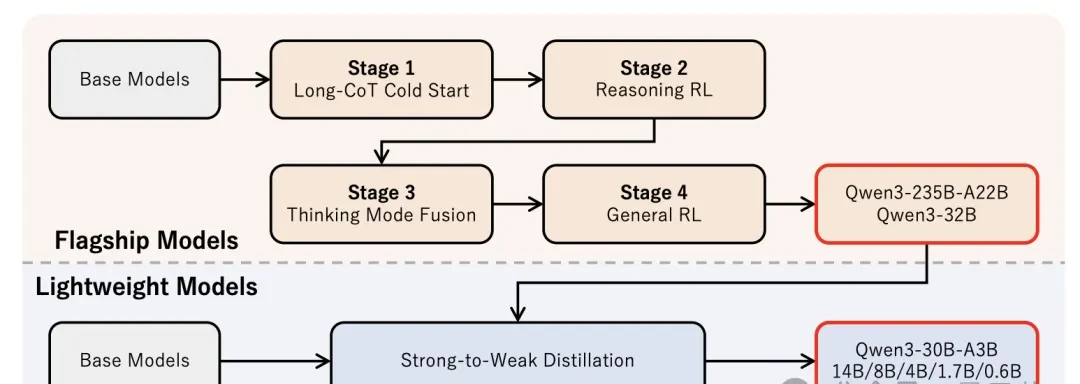
Post-training also employed a phased approach, divided into four stages.
Post-training: From Cold Start to Dual Modes
The first stage is called Long Chain-of-Thought Cold Start. Its goal is to establish initial problem-solving capabilities for the model in mathematics and programming reasoning tasks.
The Qwen team constructed a dataset containing numerous high-quality math and programming problems, annotating each with detailed solution steps. These annotated data were used for supervised fine-tuning (SFT) to help the model master key skills and common approaches.
Specifically, they filtered questions using Qwen2.5-72B and then used the QwQ-32B model to automatically generate preliminary solution steps. Human experts verified and corrected these auto-generated steps to ensure accuracy and readability.
The number of training samples and steps in this phase were kept small to allow the model to grasp basic problem-solving abilities without over-specialization.

The second stage is Reasoning Reinforcement Learning. Building on the first stage, it further introduces reinforcement learning to optimize the model’s problem-solving strategies.
They selected 3,995 questions from the first-stage dataset that covered specific domains, possessed a certain level of difficulty, and were learnable by the model.
During this phase, GRPO (Group Relative Policy Optimization) was used to update model parameters.

The third stage is Thinking Mode Integration. As the name suggests, its purpose is to integrate both thinking and non-thinking modes into a single model. This process used an SFT dataset containing both types of content.
For thinking-type samples, Qwen team followed the data generation methods from the previous two stages. For non-thinking samples, they collected open-domain conversation data and specifically generated samples such as greetings and instructions.
Additionally, the team designed a chat template that uses special tokens on the input side to distinguish between thinking and non-thinking modes.
By continuing pre-training on this mixed dataset and incorporating human feedback, the model learned to flexibly switch between the two modes based on input signals, forming a seamlessly integrated dual-mode system.

The final stage is General Reinforcement Learning, aimed at further enhancing the model’s capabilities and stability across various scenarios.
In this stage, the Qwen team constructed a reinforcement learning environment covering over 20 types of tasks, including QA, writing, code generation, an
Qwen3 Family Training Secrets Revealed: Integrating Thinking and Non-Thinking Modes in a Single Model, with Large-Model Distillation Boosting Smaller Models
d mathematical reasoning. Each task was designed with unique scoring criteria.
This phase specifically targeted improvements in instruction following, format adherence, and preference alignment.

Beyond this training methodology, the Qwen3 family also adopted a “large guiding small” data distillation approach.
Distillation is divided into two main phases: Off-policy distillation and On-policy distillation.
Analogy to human learning: the first phase is like memorizing textbooks, while the second phase involves practicing problems and self-correcting based on answers.

In the Off-policy distillation phase, a teacher model (the 235B MoE model distills the 30B MoE; the 32B dense model distills other smaller dense models) generates a large volume of high-quality outputs on a massive dataset.
These data serve as supervision signals to train student models, enabling them to mimic the teacher model’s output distribution as closely as possible.
In this phase, the teacher model uses mixed outputs from both thinking and non-thinking modes, allowing the student model to learn capabilities for handling both modes simultaneously.
Globally, this dual-mode distillation reduces inference costs while preserving complex reasoning abilities across smaller deployments.
In the On-policy distillation phase, the research team adopted a more dynamic and interactive learning method.
First, the student model autonomously generates a series of outputs in actual tasks. These are then compared with the teacher model’s outputs on the same tasks.
The optimization goal for the student model is to minimize the difference between its output distribution and that of the teacher model.
Through this continuous process of self-generation and comparison, the student model can constantly correct and refine its knowledge base in practice, gradually approximating the teacher model’s output distribution.
Qwen’s Version of DeepResearch Goes Live
With the release of the Qwen3 technical report, Alibaba has also fully launched the “Deep Research” feature in Qwen Chat. This capability, which had previously been rolled out through phased testing, marks a significant step toward automating complex analytical workflows for regional users.
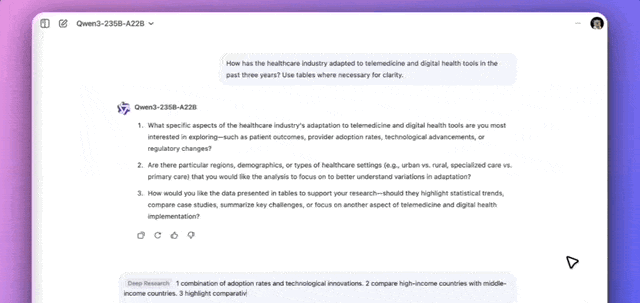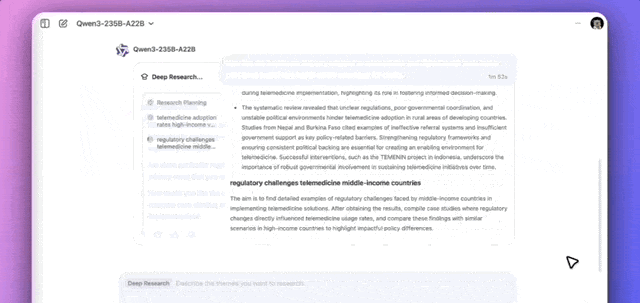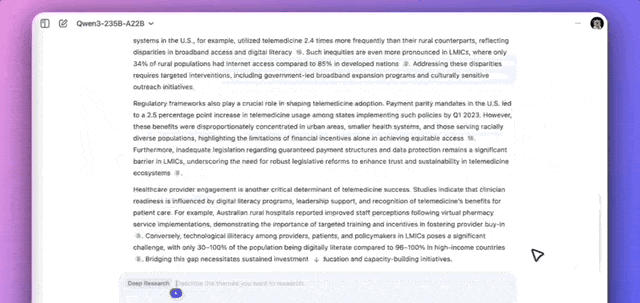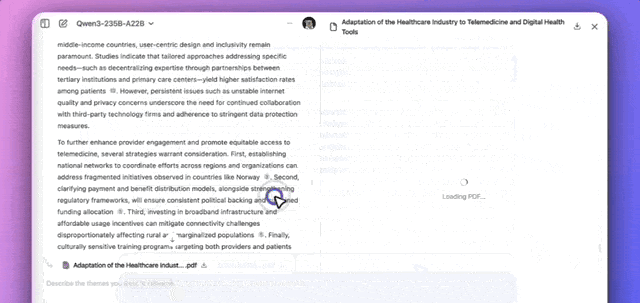
According to official descriptions, the interaction is straightforward: users describe a problem and answer refined questions posed by the model. After approximately the time it takes to drink a cup of coffee, Qwen compiles a comprehensive research report.
In an official case study, I followed Qwen as it investigated this specific query:
How has the healthcare industry adapted to telemedicine and digital health tools over the past three years? Use tables where necessary for clearer expression.
The model demonstrated a clear methodology. After clarifying requirements, Qwen planned a strategy, breaking the task down into sub-questions for retrieval and summarization. The entire research process took approximately 8.5 minutes, ultimately generating a report complete with tables and automatically exporting it as a PDF.
I think automated research agents are shifting from novelty to utility in enterprise settings. From an APAC angle, the 8.5-minute turnaround suggests optimized retrieval pipelines, not just raw generation speed. Globally, pDF export integration lowers the barrier for non-technical users in APAC markets.
For those interested in testing these capabilities directly, I recommend trying out the live interface.
Report Link:
https://github.com/QwenLM/Qwen3/blob/main/Qwen3\Technical\Report.pdf
Qwen Chat:
https://chat.qwen.ai
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google