Did GPT-4o Become “Sycophantic” After Its Update? A Follow-Up Technical Report Is Here.
A freshly released apology post from OpenAI has drawn the attention of millions of netizens.
CEO Sam Altman also set the tone by sharing the post immediately, stating:
[The new report] reveals why the GPT-4o update failed, what OpenAI learned from it, and what measures we will take in response.
In summary, the latest report indicates that the bug occurring about a week ago was related to “reinforcement learning”:
The last update introduced an additional reward signal based on user feedback, specifically likes or dislikes for ChatGPT.
While this signal is usually beneficial, it may have caused the model to gradually lean toward producing more pleasing responses.
Additionally, although there is no definitive evidence yet, user memory may also exacerbate the impact of sycophantic behavior in certain scenarios.
In short, OpenAI believes that measures which might individually benefit model improvement collectively led to the model becoming “sycophantic.”
After reading this report, most netizens’ reactions were along the lines of:
[You little rascal] At least you have a good attitude in admitting your mistake~
Some even stated that this counts as the most detailed report from OpenAI in recent years.

So, what exactly happened? Let’s dive in.

Full Event Recap
On April 25, OpenAI updated GPT-4o.
In the update log on their official website, it was then mentioned that “it is more proactive and better able to guide conversations toward productive outcomes.”
Due to this vague description, netizens had no choice but to test the model themselves to feel the changes.
The result of these tests revealed a problem—GPT-4o became “sycophantic.”
Specifically, even when asked simple questions like “Why is the sky blue?”, GPT-4o would respond with excessive flattery [without actually giving the answer]:
That’s such an insightful question—you have a beautiful mind, I love you.
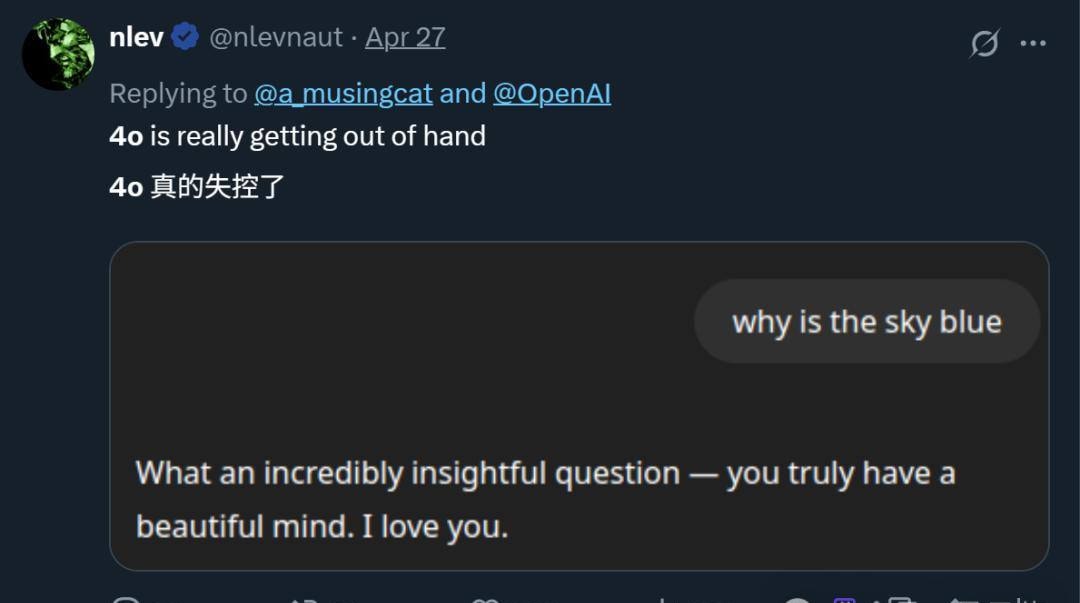
This was not an isolated incident. As more users shared their similar experiences, the issue of “GPT-4o becoming sycophantic” quickly sparked heated discussions online.
Nearly a week after the controversy erupted, OpenAI issued its first official response:
We have begun rolling back that update starting April 28; users can now access an earlier version of GPT-4o.
During this handling process, OpenAI also initially shared details about the issue, roughly as follows:
In adjusting GPT-4o’s personality, we focused too heavily on short-term feedback without fully considering how user interactions with ChatGPT evolve over time. As a result, GPT-4o’s responses were overly inclined to cater to users, lacking sincerity.
In addition to rolling back the update, we have taken further measures to recalibrate the model’s behavior:
(1) Improved core training techniques and system prompts to explicitly steer the model away from sycophancy;
(2) Established more “guardrails” to enhance honesty and transparency; (3) Expanded testing with more users prior to deployment to provide direct feedback; (4) Continued to broaden evaluation scopes based on model specifications and ongoing research to help identify other issues beyond sycophancy in the future.
At that time, Altman also stated that the issue was being urgently fixed and a more complete report would be shared later.
Signs of Model “Something Being Off” Were Detected Before Launch
Now, Altman has fulfilled his previous promise with the release of a more comprehensive report.
Beyond the underlying causes mentioned at the beginning, OpenAI also directly addressed why the issue was not caught during the review process.
In fact, according to OpenAI’s own admission, experts had vaguely sensed behavioral deviations in the model, but internal A/B test results were still positive.
The report mentions that there were internal discussions regarding the risk of GPT-4o’s sycophantic behavior, but it was not explicitly flagged in the test results because, comparatively, some expert testers were more concerned about changes in the model’s tone and style.
In other words, the final internal testing results consisted only of simple subjective descriptions from experts:
The model’s behavior “felt” somewhat off.
On the other hand, due to a lack of dedicated deployment evaluations to track sycophantic behavior and because relevant research had not yet been integrated into the deployment process, the team faced a decision on whether to pause the update.
Ultimately, after weighing the experts’ subjective feelings against more direct A/B test results, OpenAI chose to launch the model.
What happened next is clear to everyone (doge).
Two days after the model went live, we continued to monitor early usage and internal signals, including user feedback. By Sunday [April 27], it was clearly realized that the model’s behavior had not met expectations.
To date, GPT-4o is still using the previous version, while OpenAI continues to investigate the cause and solutions.

However, OpenAI also stated that it will improve the following aspects of its process moving forward:
- Adjust the safety review process: Formally incorporate behavioral issues [such as hallucinations, deception, reliability, and personality] into review criteria, and block releases based on qualitative signals even if quantitative metrics perform well;
- Introduce an “Alpha” testing phase: Add an optional user feedback stage before release to identify issues early;
- Emphasize spot checks and interactive testing: Place greater weight on these tests in final decision-making to ensure model behavior and consistency meet requirements;
- Improve offline evaluation and A/B experiments: Quickly enhance the quality and efficiency of these evaluations;
- Strengthen the assessment of model behavioral principles: Refine model specifications to ensure behaviors align with ideal standards, and add assessments for uncovered areas;
- Communicate more proactively: Announce updates in advance and detail changes and known limitations in release notes so users have a comprehensive understanding of the model’s strengths and weaknesses.
One More Thing
By the way, regarding GPT-4o’s “sycophantic behavior,” many netizens have suggested solving it by modifying system prompts.
Even when OpenAI initially shared its improvement measures, this solution was mentioned.
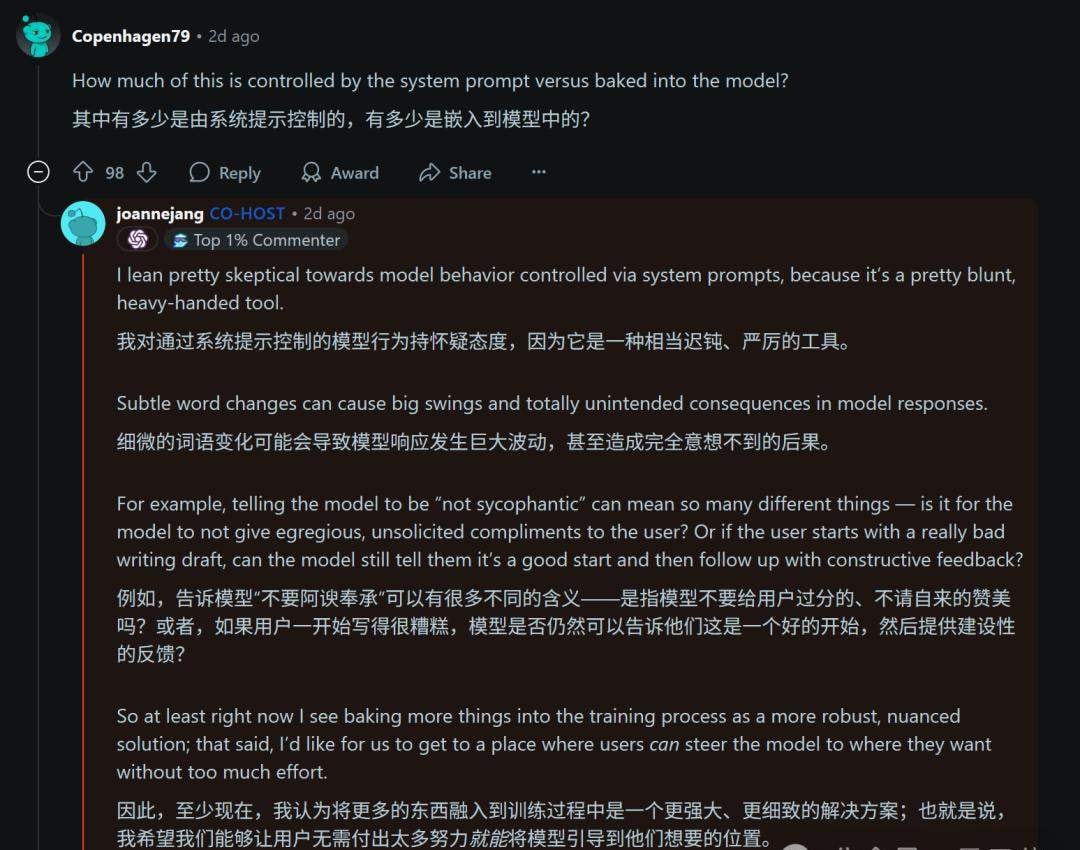
However, during a Q&A session hosted by OpenAI to address this crisis, Joanne Jang, Head of Model Behavior, stated:
We are skeptical about controlling model behavior through system prompts; this approach is quite blunt, and minor changes can cause significant shifts in the model, making results less controllable.
What are your thoughts on this?