As developers integrating AI into real-world applications, we constantly battle the tension between model speed and factual accuracy. Most multimodal models hallucinate when they lack specific, up-to-date context. The workflow problem here is clear: how do you make a vision-language model reliable without forcing it to search for everything, which slows down response times?
ByteDance and Nanyang Technological University (NTU) have released research that addresses this by optimizing multimodal model search strategies. Their approach involves building web search tools, constructing a multimodal search dataset, and designing simple yet effective reward mechanisms. This study marks the first attempt at end-to-end reinforcement learning-based autonomous search training for multimodal models.
The result is a system where the trained model can autonomously determine when to search, what to query, and how to process those results. It executes multi-turn on-demand searches directly in real-world internet environments.
In knowledge-intensive Visual Question Answering (VQA) tasks, the MMSearch-R1 system shows significant advantages. Its performance surpasses similarly sized models using traditional Retrieval-Augmented Generation (RAG) workflows. More importantly, it achieves the performance level of larger-scale models performing traditional RAG, while reducing search queries by approximately 30%.
How Was This Achieved?
Large Multimodal Models (LMMs) have seen dual improvements in the scale and quality of vision-language training datasets. They now demonstrate exceptional performance in cross-modal understanding tasks, significantly enhancing their ability to align textual and visual knowledge.
However, real-world information is highly dynamic and complex. Relying solely on expanding training data size for knowledge acquisition has inherent limitations: it struggles to cover long-tail distribution knowledge, cannot access new information post-training cutoff dates, and fails to reach private domain information resources.
These limitations lead to hallucinations in practical applications, severely restricting the reliability of model deployment across broad real-world scenarios. In this context, web search is viewed as an important tool for expanding model capabilities and has received significant attention from academia.
How to enable multimodal models to possess autonomous and precise external information retrieval capabilities, thereby achieving accurate question answering, has become a key challenge in current research.
Therefore, the MMSearch-R1 project, jointly conducted by ByteDance and Nanyang Technological University (NTU) S-Lab, explores solutions to this challenge. Below is a detailed look at the research methodology.
I think autonomous search feels like the natural evolution of RAG for multimodal agents. As a builder, cutting queries by 30% while keeping accuracy is a massive win for latency-sensitive apps. I want to see how this handles noisy, irrelevant search results in the wild.
Reinforcement Learning Training with Integrated Multi-Turn Search
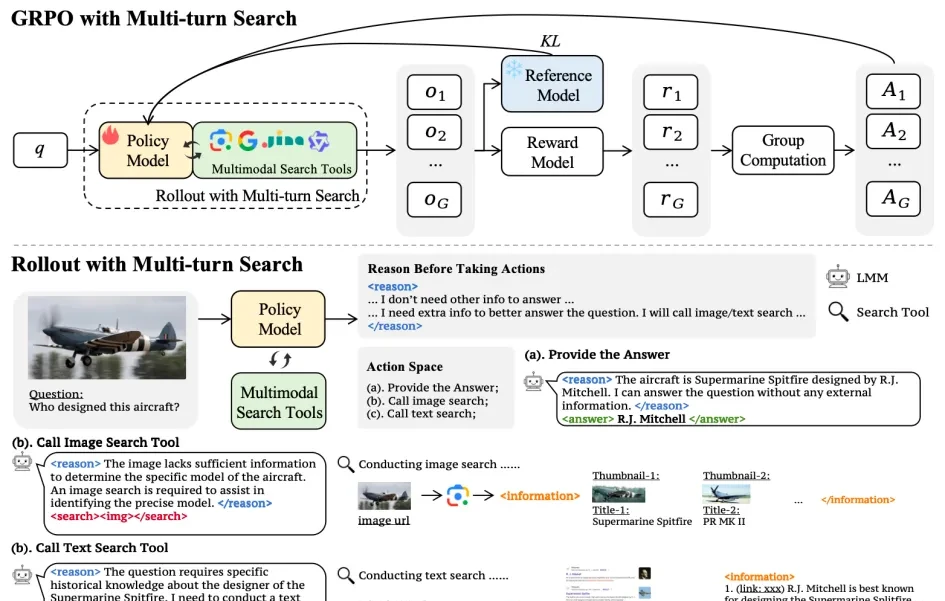
1. Multimodal Search Tools
MMSearch-R1 integrates two tools: image search and text search, to meet the needs of visual question answering tasks. The image search tool is based on Google Lens, supporting searches for web page titles and main thumbnails that match the user’s image visual appearance, helping the model accurately identify important visual elements.
The text search tool consists of a pipeline comprising Google Search, JINA Reader, and a language model for summarizing web content. It supports searching for web pages most relevant to the model-generated search queries along with their content summaries, helping the model precisely locate required textual knowledge and information.
2. Multi-Turn Search Reinforcement Learning Training
MMSearch-R1 employs Group Relative Policy Optimization (GRPO) as its reinforcement learning algorithm for model training. Based on the veRL framework, it implements a Rollout process integrating multi-turn dialogue and search. In each turn of dialogue, the model first engages in reasoning and executes optional actions, such as invoking multimodal search tools to interact with the real internet or providing a final answer.
3. Reward Function with Search Penalty
The reward function for MMSearch-R1 is composed of accuracy scores and format scores, combined via weighted summation with weights of 0.9 and 0.1, respectively. These measure whether the model accurately answered the user’s question (exact string matching between the model’s answer and the ground truth) and adhered to the prescribed response format.
To incentivize the model to prioritize using its own knowledge for answering, responses that rely on search tools to arrive at the correct answer are penalized (search penalty factor is 0.1). The final reward function is:

Personally, this penalty structure feels like a necessary guardrail against lazy tool usage. I worry about the latency overhead of this multi-turn rollout in production. I think the GRPO approach seems robust for balancing search versus internal knowledge.
Constructing a Balanced Multimodal Image QA Dataset for Search Needs
To effectively train models to achieve intelligent on-demand search capabilities, the researchers carefully constructed the FactualVQA (FVQA) dataset, comprising training and test sets. The construction of this dataset adopted a meticulously designed semi-automated process, focusing primarily on Q&A scenarios requiring rich support from both visual and textual knowledge.
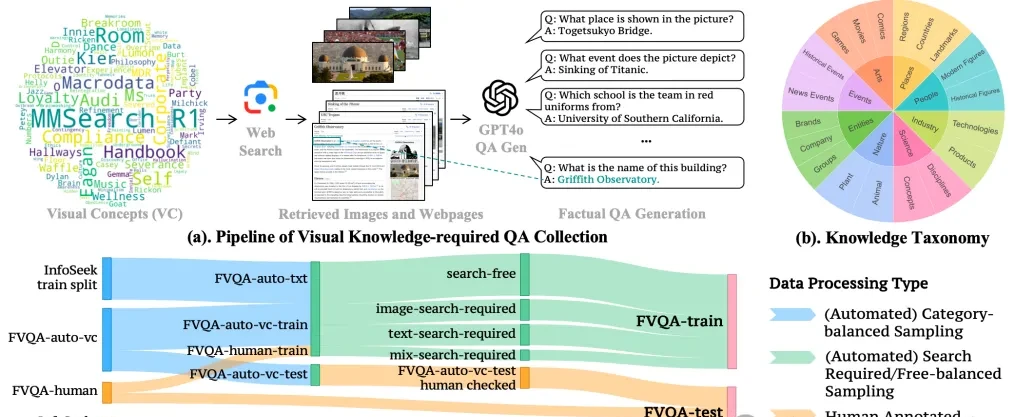
1. Data Collection
The team first performed multi-level sampling based on the metadata distribution of MetaCLIP, ensuring coverage of diverse visual concepts ranging from high-frequency to long-tail categories. They then searched the internet for images most relevant to these visual concepts and generated factual Q&A pairs using GPT-4o.
To enhance the textual knowledge dimension of the dataset, the team also selected representative Q&A samples from the InfoSeek training set for supplementation. To ensure data quality closely mirrored real-world application scenarios, FVQA included an additional 800 annotated Q&A sample pairs labeled by human annotators.
2. Data Balancing
After completing initial data collection, a coarsely trained model was used to classify existing samples and check the necessity of searching for each piece of data. The final training dataset contains approximately 3,400 samples requiring search and 1,600 samples that do not require search.
How Did the Experiments Perform?
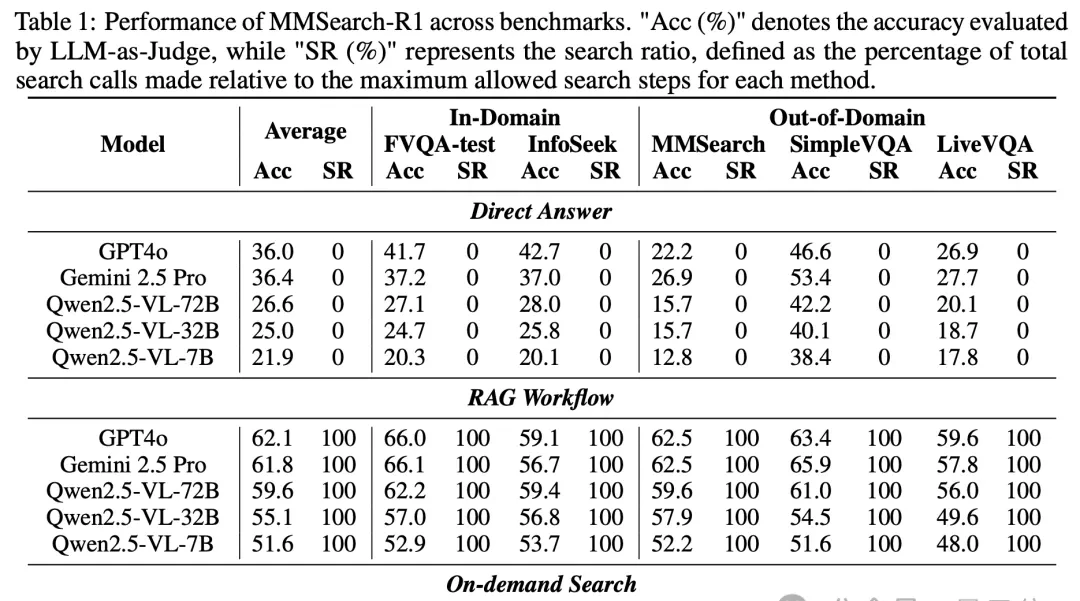
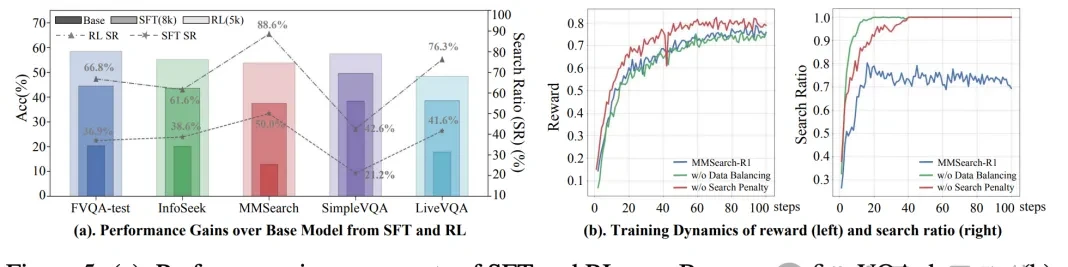
I followed the ByteDance and NTU study on MMSearch-R1-7B, a model built atop Qwen2.5-VL-7B that aims to solve the workflow friction of unnecessary API calls in multimodal VQA. The filing shows that for knowledge-intensive tasks like FVQA-test and InfoSeek, this approach delivers an average accuracy roughly 3% higher than traditional RAG baselines of similar size, while slashing its search ratio by 32.9%. It even matched the performance of a much larger 32B model baseline.
What stood out to me is how reinforcement learning (RL) training specifically optimized the model’s ability to process search results and mine its own inherent knowledge. The data indicates that after RL, the model became better at executing RAG workflows compared to its original state, while also increasing the ratio of correct answers generated without any external search.
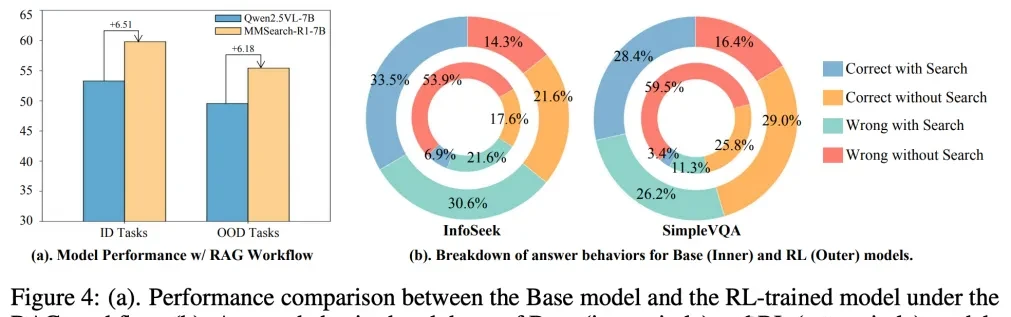
The study highlights that reinforcement learning offered greater potential than supervised fine-tuning, achieving larger gains with fewer training samples across all tasks. It also proved that balancing the data search ratio and incorporating a search penalty in the reward function effectively shapes on-demand behavior during training.
As a builder, this on-demand strategy could significantly cut latency for agents that currently over-rely on external tools. Personally, the penalty mechanism seems like a practical way to prevent model laziness in future training runs.
In summary, MMSearch-R1 is an innovative framework based on reinforcement learning that empowers large multimodal models to perform intelligent on-demand searches in real-world internet environments. This framework enables models to autonomously identify knowledge boundaries and subsequently choose image or text search methods to acquire necessary information, effectively reasoning over the search results.
The team stated that this research provides important insights for developing large multimodal models with real-world interaction capabilities, laying the foundation for building adaptive, interactive multimodal agents. As models continue to interact with the real world through more tools, it is expected that multimodal intelligence will achieve new leaps in reasoning and adaptability.
Paper Link: https://arxiv.org/abs/2506.20670
Project Link: https://github.com/EvolvingLMMs-Lab/multimodal-search-r1
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google