When Chinese research institutes and tech giants collaborate on open-source foundation models, the ripple effects extend far beyond Beijing or Hong Kong. For global supply chains and AI developers, these benchmarks signal that high-performance spatial reasoning is no longer the exclusive domain of Western closed ecosystems.
ViLaSR-7B, an open-source model jointly developed by Ant Group’s Technology Research Institute Natural Language Group, the Institute of Automation at the Chinese Academy of Sciences (CASIA), and The Chinese University of Hong Kong (CUHK), has demonstrated that large language models can master spatial thinking through a novel approach.

The model achieved an average improvement of 18.4% across five benchmarks, including maze navigation, static image understanding, and video spatial reasoning. This performance jump suggests that training methodologies emphasizing visual manipulation are becoming critical for next-generation AI capabilities in the Asia-Pacific region.
Notably, on the VSI-Bench proposed by renowned scholar Fei-Fei Li and others, it reached a score of 45.4%, comparable to Gemini-1.5-Pro, comprehensively surpassing existing methods. This parity with leading Western proprietary models indicates that open-source efforts in Asia are rapidly closing the gap in complex reasoning tasks.
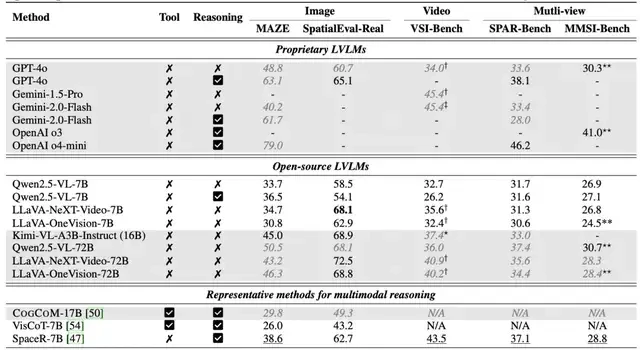
△ Main experimental results
More importantly, extensive case studies demonstrate that the model has indeed mastered spatial reasoning strategies and reflective capabilities similar to humans, marking a significant step toward true visual intelligence. I followed the release closely, noting how this shift from passive recognition to active “thinking while drawing” could reshape how we evaluate AI utility in industrial automation.
The team designed a three-stage training framework to cultivate this reasoning capability:
- Cold-start training establishes foundational visual manipulation skills.
- Reflective rejection sampling filters for high-quality reasoning paths.
- Reinforcement learning directly optimizes task objectives.
Let’s take a closer look.
Shifting from Text to Visual Logic
As large models tackle spatial reasoning, the industry is moving beyond simple text-to-image translation toward active visual manipulation. I followed this shift closely, noting how Ant Group’s new framework challenges the dominant “Vision-to-Text” approach used by competitors like OpenAI. This transition matters for APAC tech firms aiming to reduce computational waste in complex multi-view tasks.
I think the industry is pivoting from passive image encoding to active visual manipulation during reasoning. From an APAC angle, ant Group’s framework addresses the information loss inherent in compressing visuals into text tokens. Globally, this shift reduces computational overhead by filtering out irrelevant background noise early in the process.
The Limits of “Vision-to-Text”
Visual reasoning has become a critical frontier in machine intelligence, requiring systems to analyze objects, scene layouts, and spatial relationships much like humans do. While OpenAI’s o3 and o4-mini models recently demonstrated significant breakthroughs using a “Thinking with Images” paradigm—actively cropping, scaling, or rotating images during text-based reasoning—the broader industry is still grappling with legacy methods.
Traditional Large Vision-Language Models (LVLMs) typically rely on a “Vision-to-Text” approach. Here, image data is compressed via a vision encoder into token sequences aligned with language space, which are then handed to an LLM for pure text-based reasoning. Although The Platonic Representation Hypothesis—a paper liked by Ilya Sutskever in June last year—suggests that visual and linguistic representations naturally converge as model scale increases, practical implementation faces severe hurdles.
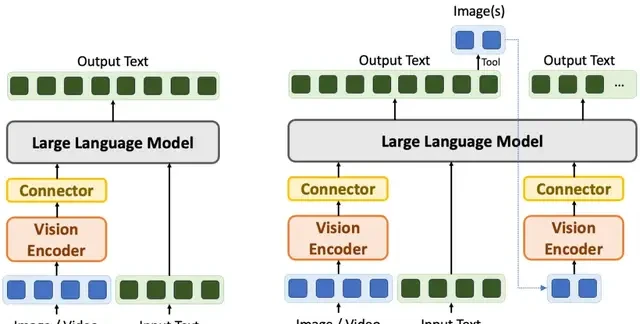
△ Two Visual Reasoning Paradigms
The primary issue is data loss. Due to limitations in training data and vision encoder capabilities, the compression process inevitably discards critical detail and spatiotemporal information. Once lost during this initial alignment phase, it cannot be recovered during subsequent text-only reasoning. Furthermore, visual data often contains substantial background details irrelevant to the task, particularly in high-redundancy scenarios like video. Blindly increasing model size to preserve more information consumes vast computational resources processing noise and may degrade performance by causing over-focus on irrelevant elements.

△ Limitations of “Vision-to-Text” Reasoning
These limitations are evident in specific tasks, such as models confusing directions during maze navigation or struggling to establish spatiotemporal associations between objects in multi-view reasoning. Consequently, visual reasoning is undergoing a paradigm shift from passive “Vision-to-Text” to active “Thinking with Images.”
Precedents and New Synthesis Methods
This new direction is not entirely novel. The CVPR 2023 Best Paper VisProg proposed a training-free prompting method allowing large models to generate Python programs to call vision tools, embodying this philosophy. Similarly, Ant Group’s Technology Research Institute pioneered VisualReasoner, presented at EMNLP 2024, which proactively introduced visual operations during reasoning by editing and generating new visual cues to enhance perception.
Crucially, VisualReasoner designed a data synthesis method capable of automatically generating large volumes of training data containing multi-step visual reasoning processes. This achieved for the first time the native injection of such reasoning capabilities into model parameters. These explorations have opened new directions for addressing information loss issues inherent in traditional vision-to-text conversion paradigms.
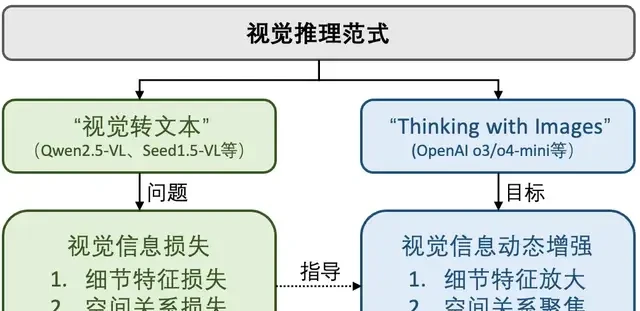
△ Comparison of Two Reasoning Paradigms
Under the broader framework of “Thinking with Images,” the Natural Language Group at Ant Group’s Technology Research Institute, in collaboration with CASIA and CUHK, focused
Large Models Master Human Spatial Reasoning: Three-Stage Training Framework Learns to ‘Think While Drawing,’ Boosting Benchmarks by 18.4%
The push for better spatial reasoning in video and multi-image scenarios is no longer just an academic exercise; it is a critical bottleneck for autonomous systems and advanced robotics across the Asia-Pacific manufacturing hubs. Current visual reasoning models often fail because they lack robust enhancement of spatial relationships and struggle with cross-frame tracking, limiting their utility in real-world logistics and surveillance applications.
To address these gaps, the research team has open-sourced ViLaSR-7B (Vision-Language Model for Spatial Reasoning). This model introduces an innovative “Drawing to Reason in Space” paradigm that fundamentally changes how Large Vision-Language Models (LVLMs) process visual data. Instead of passively receiving information, ViLaSR-7B enables models to “draw while thinking,” mimicking human cognitive processes by generating auxiliary annotations—such as reference lines and bounding boxes—directly within the visual space.
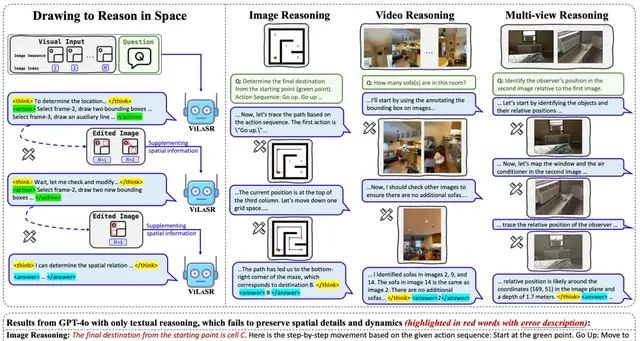
△ Example of “Drawing to Reason in Space”
This interactive approach guides the vision encoder to capture key spatial relationships more effectively. By embedding these annotations, the model preserves richer spatial information within visual token embeddings, directly mitigating the information loss inherent in traditional “Vision-to-Text” reasoning paradigms. The result is a significant boost in benchmark performance, with improvements reaching 18.4%, demonstrating that simulating human thought processes through active visual manipulation yields tangible gains in spatial perception.
I think this method reduces reliance on purely textual descriptions for complex geometry tasks. From an APAC angle, open-sourcing the model accelerates adoption in regions lacking proprietary AI infrastructure. Globally, the 18.4% gain suggests a new standard for evaluating multi-modal reasoning capabilities.
Technical Solution: Drawing to Reason in Space
I followed the release notes for this new framework, which allows models to manipulate single or multiple images during each reasoning step. By selecting key frames, performing cross-frame comparisons, and drawing bounding boxes and auxiliary lines, it constructs visual cues that focus on specific spatial regions and dynamically track changes across different images.
Unlike existing methods that rely on external specialized cognitive tools or are limited to observing local details, this approach not only maintains the model’s original…
enhanced visual reasoning capabilities, further supporting coherent spatial reasoning in multi-image scenarios. It continuously updates and optimizes its holistic understanding of spatial states, truly realizing the cognitive process of “drawing while thinking, thinking while drawing.” This mechanism demonstrates significant advantages when handling complex spatial reasoning tasks that require multiple steps and long sequences, not only improving reasoning efficiency but also enhancing the interpretability and controllability of the results.
I think visual grounding via explicit drawing offers a transparent alternative to opaque black-box reasoning in enterprise AI. From an APAC angle, this method bridges the gap between symbolic logic and perceptual vision tasks for industrial automation.
Three-Stage Training Framework: Systematically Cultivating Spatial Reasoning Abilities
To effectively improve the performance of Vision-Language Models (VLMs) on spatial reasoning tasks, ViLaSR employs a systematic three-stage training framework. I read that this framework aims to gradually cultivate the model’s spatial understanding and reasoning capabilities from scratch, enabling it to perform multi-step, in-depth spatial analysis through “drawing-assisted thinking,” much like humans do.
Stage 1: Cold-Start Training
The first step of training is to establish the model’s basic cognitive abilities regarding visual space. The research team constructed initial visual reasoning paths using synthetic data and trained the model to execute basic drawing operations via supervised learning, such as annotating bounding boxes and drawing auxiliary lines. These operations lay the foundation for subsequent complex reasoning.
Stage 2: Reflective Rejection Sampling
The goal of the second stage is to enhance self-correction and reflective capabilities. This stage introduces a reflective rejection sampling mechanism that evaluates multiple reasoning paths generated by the model, selecting high-quality samples that demonstrate reflective behaviors (such as modifying bounding boxes or auxiliary lines) for reinforcement training. This mechanism encourages the model to proactively identify and adjust uncertain or erroneous reasoning paths, dynamically optimizing solutions based on feedback.
Stage 3: Reinforcement Learning
The final stage adopts a reinforcement learning strategy to further optimize the model’s overall reasoning ability and the efficiency of its drawing operations. In this phase, the model focuses simultaneously on answer accuracy and the logical consistency and formatting rationality of the reasoning process through result reward functions and format reward functions. The format reward is only granted when the result reward exceeds a threshold (set here to 0), ensuring that the model prioritizes correct results rather than merely optimizing for format compliance. The objective of this stage is to enable the model to autonomously select optimal reasoning paths across different tasks and use drawing tools reasonably, avoiding redundant operations. This phase not only improves the model’s final performance but also enhances its adaptability in various spatial reasoning scenarios.
Globally, rewarding format consistency alongside accuracy may slow initial convergence but ensures reliable deployment in regulated sectors. I think synthetic data for cold-start training reduces dependency on expensive human-annotated spatial datasets globally.
Benchmark Performance and Training Dynamics
The release of ViLaSR-7B signals a shift in how large models handle spatial logic, moving beyond pure text to integrated visual reasoning. This development ripples through the APAC tech sector as local labs race to integrate similar multimodal capabilities into their proprietary stacks.
1. ViLaSR Sets New Standards on Spatial Benchmarks
ViLaSR-7B delivered an average improvement of 18.4% across five major spatial reasoning benchmarks: Maze Navigation (Maze), Static Image Understanding (SpatialEval-Real), Video Spatial Reasoning (VSI-Bench), Multi-Image Spatial Reasoning (SPAR-Bench, MMSI-Bench).
This significant improvement indicates that introducing the image-assisted thinking mechanism substantially enhances the model’s generalization and spatial reasoning capabilities across various task types, making it more adaptable than pure text-based reasoning.
Notably, on VSI-Bench—one of the most challenging benchmarks for visual-spatial understanding—ViLaSR-7B achieved an average accuracy of 45.4%, significantly outperforming Qwen2.5-VL-7B (+12.7%).
From an APAC angle, this performance gap suggests that current open-weight models may lack the specialized training data required for complex spatial tasks. Globally, the reliance on visual aids for reasoning could reduce computational costs compared to scaling purely textual parameters.
2. Ablation Studies Reveal Critical Training Components
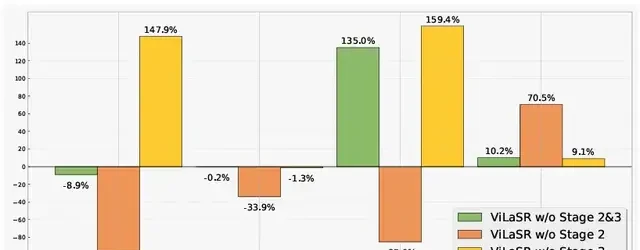
△ Ablation study. Scores represent the percentage relative increase in key behaviors compared to the complete ViLaSR model.
Ablation experiments revealed that the cold-start stage first helps the model master the “drawing-assisted thinking” capability; removing the reflective rejection sampling stage leads to a significant reduction in reflective behaviors, reasoning steps, and drawing operations. This indicates that the reflective rejection sampling mechanism plays a crucial role in the model’s self-identification and correction when facing erroneous paths.
Furthermore, compared to ViLaSR-7B, the version without reinforcement learning showed performance degradation across most sub-tasks, accompanied by a surge in the frequency of drawing/auxiliary line usage (+159.4% / +9.1%), indicating that reinforcement learning helps learn more refined operational strategies.
The performance drop was more pronounced for numerical tasks compared to multiple-choice tasks (-9.21% vs. -4.07%), validating that the dense rewards provided by reinforcement learning are more effective in promoting precise spatial reasoning, offering advantages over supervised fine-tuning alone.
I think the high cost of reinforcement learning may limit adoption among smaller APAC research teams without significant compute subsidies. From an APAC angle, this framework highlights a growing industry trend toward “thinking” processes that mimic human sketching rather than just text generation.
3. Possesses Human-Like Spatial Reasoning Strategies
The emergence of models that mimic human cognitive shortcuts in spatial tasks signals a shift from pure pattern matching to structured reasoning. This has implications for how APAC robotics firms might integrate vision-language systems into physical workflows without requiring massive compute overheads.
Globally, structured reasoning reduces hallucination risks in critical infrastructure monitoring across Southeast Asia.
In-depth case studies indicate that ViLaSR-7B not only surpasses existing methods in performance but also exhibits human-like spatial reasoning strategies. As shown below, the model has mastered the following key capabilities:
1. Reference-Based Metric Reasoning:
In a task measuring the size of a telephone, the model demonstrated mature reference-based reasoning abilities. It first recognized that relying solely on pixel measurements would not yield accurate results, then proactively sought out a reference object with known dimensions (a monitor), and finally calculated the actual size of the phone through proportional conversion. This reasoning approach is highly consistent with how humans solve practical measurement problems.

△ Example of reference-based metric reasoning
I think this proportional logic could standardize quality control in manufacturing hubs from Vietnam to Japan.
2. Systematic Cross-Frame Object Tracking:
When faced with tasks requiring the understanding of relative object positions across multiple frames, the model adopted a systematic annotation strategy—marking the positions of identical objects in different frames and establishing spatial and temporal associations between them through these markers. This method not only ensures reasoning accuracy but also improves result interpretability.

△ Example of systematic cross-frame object tracking
From an APAC angle, interpretability is a regulatory prerequisite for AI adoption in Australia’s financial and legal sectors.
This study focuses on spatial reasoning tasks, integrating drawing operations with multimodal reasoning through the “Drawing to Reason in Space” paradigm. This enables models to “draw while thinking” within visual spaces, more effectively understanding and reasoning complex spatiotemporal relationships, thereby significantly enhancing large models’ spatial perception capabilities as well as the interpretability and controllability of their reasoning. This paradigm lays the foundation for spatial intelligence in fields such as robot navigation and virtual assistants, and will continue to drive multimodal reasoning toward greater generality and efficiency in the future.
The first author of this work is Wu Junfei, a Ph.D. student at the Institute of Automation, Chinese Academy of Sciences, currently interning at Ant Group’s Technology Research Institute. Guan Jian, Associate Research Fellow at Ant Group’s Technology Research Institute, is the co-first author.
Paper Link: https://arxiv.org/abs/2506.09965
Code Repository: https://github.com/AntResearchNLP/ViLaSR
— End —
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google