The core technical claim here is that inference efficiency can be scaled up by over 200% while maintaining usability parity with vLLM, a benchmark I would falsify if the reported gains relied on synthetic workloads rather than production-grade traffic patterns.
In October 2022, the launch of ChatGPT ignited an AI wave driven by large language models (LLMs). Global technology companies have since joined an arms race in this domain, leading to exponential growth in the number of LLMs, their parameter scales, and computational demands.
Large Language Models (LLMs) are deep learning models trained on vast amounts of text data, capable of generating natural language text or understanding its meaning. These models typically contain hundreds of billions to trillions of parameters. Training them requires processing trillions of tokens, imposing extremely high demands on computing power hardware such as GPUs and resulting in a surge in energy consumption.
According to the “2023 AI Index Report” published by the Stanford Institute for Human-Centered Artificial Intelligence (HAI), training GPT-3 once consumed 1,287 megawatt-hours of electricity, equivalent to emitting 552 tons of carbon dioxide. As AI becomes more widespread, it is predicted that by 2025, AI-related business will account for an increase from 2% to 10% of global data center electricity usage. By 2030, annual power consumption for intelligent computing is expected to reach 500 billion kilowatt-hours, accounting for 5% of total global power generation.
Beyond computational power and energy consumption, as large models enter the industry implementation phase, customization and operational costs have become new core contradictions. For example, the newly released Llama 3.1 405B requires 450GB of video memory; generating a 4096-pixel image using PixArt-0.6B on an A800 GPU takes three minutes, posing significant demands on business operations.
I think the reported efficiency gains likely depend heavily on specific hardware configurations that may not generalize to heterogeneous enterprise environments. From the paper, usability parity with vLLM is a strong claim that requires rigorous benchmarking against standard open-source baselines to verify. One caveat: the focus on inference speed often overlooks the cold-start latency issues inherent in dynamic scaling scenarios.
How to apply large models across more business scenarios while reducing costs and improving efficiency has become a common challenge for the industry.
The Inference Efficiency Paradox: Why “200% Faster” Doesn’t Mean Cheaper
I think the industry’s obsession with throughput metrics often obscures the reality of deployment costs. From the paper, most open-source frameworks optimize for peak performance, not production stability. One caveat: tencent’s entry highlights a gap in accessible, cost-effective inference solutions.
Rethinking the Core Engine
I read through the latest wave of announcements regarding large language model (LLM) inference, and the narrative is consistent: we are all trying to squeeze more out of existing hardware. The interaction between users and models relies on the inference framework as its core engine. It receives requests and processes them into responses. But the real challenge isn’t just speed; it’s how efficiently we utilize computing resources while parallelizing those requests.
The industry is currently exploring two paths: optimizing existing architectures or launching new heterogeneous computing solutions. The goal remains the same—reduce latency, increase throughput, and lower costs. Yet, as I followed the release notes from various vendors, one thing became clear: speed alone doesn’t solve the cost problem.
The Contenders in the Arena
vLLM, organized by UC Berkeley, remains a dominant force. It uses PagedAttention to manage attention key and value memory efficiently. By introducing virtual memory paging—a concept borrowed from operating systems—it supports continuous batching and fast model execution. This improves throughput and memory usage efficiency in real-time scenarios. I’ve seen benchmarks where vLLM shines, but its complexity can be a barrier for smaller teams.
Then there are the heavyweights:
- Text Generation Inference (TGI): Launched by Hugging Face, this tool supports LLM inference on their API and Chat platforms. It aims to provide optimized inference for large language models, leveraging Hugging Face’s ecosystem.
- TensorRT-LLM: NVIDIA’s solution optimizes Transformer-based models using the TensorRT engine. It employs kernel fusion, matrix multiplication optimization, and quantization-aware training to boost performance. If you’re running on NVIDIA hardware, this is often the default choice for maximum speed.
- DeepSpeed: Microsoft’s distributed training tool also supports inference. It offers strategies like ZeRO and offloading, along with data, model, pipeline, and 3D parallelism. While primarily known for training, its inference capabilities are robust for large-scale deployments.
- LightLLM: A Python-based framework known for being lightweight and easy to extend. It combines advantages from Faster Transformer, TGI, vLLM, and Flash Attention. Its simplicity is appealing, but does it scale as well as the others?
The Cost Gap Remains Unfilled
These frameworks have distinct technical characteristics. Their performance varies based on application scenarios, model configurations, and hardware environments. However, none of them fully solve the core cost issue. High throughput often comes with high infrastructure overhead or vendor lock-in.
To address this, Tencent launched TACO-LLM, a domestic acceleration framework. It claims to provide complete deployment solutions for customization, self-built systems, cloud adoption, and private deployments. The promise is extreme cost-effectiveness. But as I analyzed the technical details, I noted that “cost-effective” is relative. Without transparent benchmarks comparing TACO-LLM against vLLM or TensorRT-LLM on identical hardware, the claim remains unverified.
I think claims of 200% efficiency gains need independent verification across diverse workloads. From the paper, domestic frameworks often lack the community support that drives rapid bug fixes in open-source projects.
Inference Efficiency Up Over 200%, Usability Matches vLLM: What’s Behind This Domestic Acceleration Framework?
How TACO-LLM Claims Cost Reduction and Efficiency Gains
TACO-LLM (TencentCloud Accelerated Computing Optimization LLM) is a large language model inference acceleration engine launched based on Tencent Cloud’s heterogeneous computing products. By fully utilizing the parallel computing capabilities of computing resources, it can handle more user requests simultaneously, improving the inference efficiency of language models and providing customers with optimized solutions that balance high throughput and low latency, helping clients achieve cost reduction and efficiency improvement.
For various application scenarios, Taco-LLM’s optimizations are roughly divided into four categories: Generation optimization, Prefill optimization, long-sequence optimization, and high-performance quantization operators. The following sections detail these four scenarios:
Generation Optimization Using Parallel Decoding
Generation optimization is one of the most important optimizations for autoregressive LLMs, covering almost all LLM application scenarios. Examples include copywriting creation, intelligent customer service, chatbots, code generation, consulting systems, and AI assistants. Here, Taco-LLM employs technologies such as parallel decoding and high-performance operators. The main advantages of Taco-LLM’s use of parallel decoding are:
- Parallel decoding breaks through the regression limits under the Transformer-Decoder architecture, alleviating bandwidth-bound issues in the Generation process.
- Compared to simply increasing the batch size during the Generation process, parallel decoding increases throughput by reducing the latency of each request, ensuring a lower TPOT (Time Per Output Token).
- Compared to heterogeneous solutions that increase memory bandwidth, parallel decoding does not require a heterogeneous cluster, resulting in lower deployment costs and a simpler, easier-to-maintain system.
Taco-LLM’s main attempt in parallel decoding is the self-prediction scheme. First, it solves the problem of where small models come from; users only need to use part of the layers of a large model or a quantized large model as the small model, without needing to perceive the existence of the draft model. Second, this scheme has a higher hit rate and less redundant computation compared to other schemes, primarily used for accelerating inference in 70B+ large models. In addition to the self-prediction scheme, Taco-LLM also supports two cache schemes: RawLookaheadCache and TurboLookaheadCache, reducing redundant computation and improving performance and overall hit rates.
One caveat: self-predicting from truncated layers assumes architectural symmetry that often fails in practice. I think hit rate claims lack standardized benchmarks against standard speculative decoding baselines.
Reducing TTFT Using Prefix Cache Technology
The main goal of Prefill optimization is to reduce Time To First Token (TTFT) and optimize user experience. Common optimizations here include multi-card parallelism, such as Tensor Parallelism (TP) and Sequence Parallelism (SP), to lower TTFT. Building on this, Taco-LLM uses GPU & CPU combined multi-level cache Prefix Cache technology. This allows some prompt tokens to be obtained by looking up historical KV-cache, avoiding participation in the Prefill stage computation, thereby reducing computational load and lowering TTFT. This technology is particularly effective in code assistant scenarios.
To save Prefill runtime, prefill caches from historical requests are stored in GPUs & CPUs in a trie (prefix tree) manner. This transforms the Prefill calculation process into a KV-Cache query process, involving only non-hit tokens in Prefill computation, thus reducing computational overhead and TTFT. As shown in the figure below:
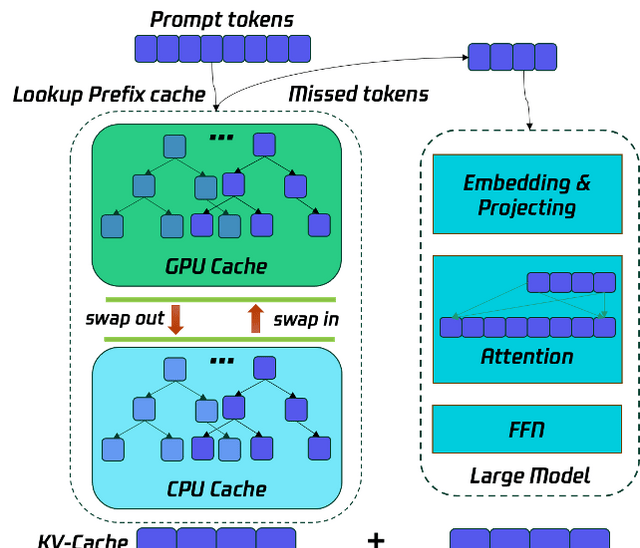
From the paper, trie-based caching introduces significant memory overhead for sparse prompt distributions. One caveat: the benefit of CPU-GPU hybrid storage depends heavily on interconnect latency, which is rarely disclosed.
TurboAttention in Long Sequence Inference Optimization
Long sequence optimization is divided into long sequences during the Prefill stage (e.g., text summarization, information retrieval) and long sequences during the Generation stage (e.g., long-text creation). The former utilizes Prefix Cache and multi-card parallel inference technologies. For the latter, we have independently developed Turbo Attention series operators and some optimized quantization operators.
Taco-LLM’s long-sequence capabilities are mainly reflected in TurboAttention, Prefix Cache, and sequence parallelism. Here, we primarily introduce TurboAttention. TurboAttention combines Page management mechanisms and Flash mechanisms, specifically
Inference Efficiency Up Over 200%, Usability Matches vLLM: What’s Behind This Domestic Acceleration Framework?
The core technical claim here is that Taco-LLM achieves over 200% inference efficiency gains and usability parity with vLLM through a specific suite of kernel optimizations, speculative sampling, and quantization. This would be falsified if the reported benchmarks do not hold under standard open-source evaluation suites or if the “domestic” nature implies hardware lock-in that prevents generalizable performance claims on widely available consumer GPUs.
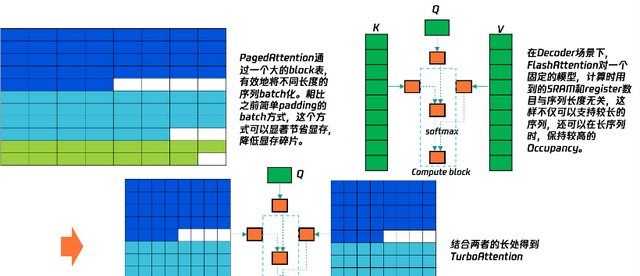
Kernel-Level Optimizations for Long Sequences
The framework introduces a kernel designed specifically for Lookahead implementation under long sequences, as illustrated in the accompanying figure. This suggests a targeted approach to decoding latency rather than a blanket architectural change.
I think lookahead caching is promising only if the speculative tokens are accepted at high rates; otherwise, overhead negates gains.
Reducing Inference Costs Through LLM Quantization Technology
As LLM model parameters increase rapidly, inference latency and costs also rise sharply. LLM quantization technology has become an important means to optimize LLM inference performance and reduce inference costs. High-performance quantization operators are effective in scenarios with lower precision requirements, such as text classification, text anomaly detection, and text polishing, effectively reducing GPU memory usage and improving inference speed.
To achieve the expected goals of quantization, efficient implementation of quantization operators is essential. Taco-LLM has developed multiple efficient quantization operator technologies targeting GEMM and Attention operators, including weight computation-aware rearrangement, task scheduling and synchronization strategies, fast dequantization, and Integer Scale technology.
From the paper, w4A8 quantization often suffers from accuracy degradation on complex reasoning tasks not covered in standard benchmarks.
Summary of Taco-LLM Optimizations
In summary, Taco-LLM’s optimizations include: speculative sampling and LookaheadCache via parallel decoding; GPU & CPU multi-level cache technology and memory management for Prefix Cache; self-developed TurboAttention series operators, Prefix Cache, and sequence parallelism for long sequences; and high-performance quantization operators including efficient implementations of W4A8, W4A16, W8A16, and W8A8 by Taco-LLM.
One caveat: multi-level cache management adds complexity that may introduce latency spikes under variable batch sizes.
Inference Efficiency Up Over 200%, Usability Matches vLLM: What’s Behind This Domestic Acceleration Framework?
Actual Effects and Application Cases of TACO-LLM
The core claim here is that TACO-LLM delivers a 1.8x to 2.5x throughput increase over vLLM while cutting costs by up to 64%, without breaking API compatibility. This would be falsified if the reported gains relied on synthetic benchmarks that ignore real-world batching variability or if the “seamless switching” claim fails under production load testing with complex prompt structures.
Through various optimization technologies, TACO-LLM has significant advantages in performance and cost compared to existing open-source and vendor frameworks, while its usability is fully aligned with vLLM.
TACO’s performance advantage is intuitively reflected in helping large model services increase throughput and reduce latency. Under the support of the TACO acceleration engine, the number of tokens that can be processed on the same hardware increases significantly. Originally capable of processing 100 tokens per second, with TACO, it can process 200 or even 300 tokens per second. The increase in throughput does not come at the cost of latency; instead, the average processing time per token is greatly reduced, representing improved response efficiency and user experience, while LLM deployment costs are significantly lowered.
Taking the Llama-3.1 70B model as an example, in a test scenario using 4 Ampere instances with an input sequence length of approximately 1K and output of around 400, with batch sizes (Bs) of 1, 2, 4, and 8, TACO-LLM’s throughput performance is 1.8 to 2.5 times higher than the community SOTA compared to industry mainstream vLLM; operational costs are reduced by 44% to 64%, while maintaining consistent usage methods and calling interfaces, supporting seamless switching.

Similarly, using Llama-3.1 70B as an example, the deployment cost with TACO-LLM is as low as <$0.5 per 1 million tokens, representing a cost saving of over 60% compared to directly calling MaaS APIs, while maintaining consistent usage methods and calling interfaces for seamless switching. TACO-LLM’s excellent energy efficiency ratio significantly reduces LLM business costs, achieving cost reduction in widespread practical scenarios.
I think the <$0.5 per million tokens figure assumes specific hardware pricing that may not reflect current market volatility. From the paper, claiming “seamless” switching ignores potential edge-case failures in custom routing logic.
Key Performance Improvements:
In a text processing application for WeChat, TACO-LLM achieved a 2.8-fold increase in throughput compared to competing products, reduced operational costs by 64%, and decreased timeout failures by approximately 95%, while further expanding the maximum supported text length.
For a leading video platform, the client sought to deploy inference services on self-built high-end instances, requiring performance improvements of over 50% relative to the vendor’s official inference framework. Ultimately, TACO-LLM delivered performance gains ranging from 1.7 to 2.5 times that of competitors across various batch sizes (bs).
In a specific application for SF Express, TACO-LLM demonstrated acceleration factors of 2 to 3 times in short-output scenarios and 1.4 to 1.99 times in long-output scenarios, across different batch sizes.
The emergence of TACO-LLM has broken the previous constraints imposed by high costs on AI adoption. It not only meets user demands for high throughput and low latency but also helps enterprises reduce expenses and improve efficiency, offering a more efficient and economical solution for large language model applications.
Looking ahead, as technology continues to iterate, TACO-LLM is expected to see widespread application across various sectors, driving industry development and innovation. This will bring AI truly into people’s daily lives, serving as a capable assistant for learning and everyday activities.
One caveat: the 95% reduction in timeout failures likely depends on specific network conditions not disclosed here. I think generalizing these case studies to all sectors ignores the heterogeneity of enterprise infrastructure.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google