Can Multimodal Large Models Achieve Generalized Reasoning with Dynamic Reinforcement Learning?!
Researchers from OPPO Research Institute and The Hong Kong University of Science and Technology (Guangzhou) have proposed a new technology called OThink-MR1, which extends reinforcement learning to multimodal language models, helping them better handle various complex tasks and new scenarios.
The researchers stated that this technology enables the industry to break through the generalized reasoning capabilities of multimodal models.

As is well known, while multimodal large models can process various types of input data and generate relevant outputs, their performance often falls short when faced with complex reasoning tasks.
Currently, most multimodal models are primarily trained using Supervised Fine-Tuning (SFT).
SFT is akin to a teacher highlighting key points for students, guiding them to learn in fixed patterns. Although this method can yield good results on specific tasks, it struggles to cultivate essential general-purpose reasoning abilities.
Meanwhile, Reinforcement Learning (RL), as an alternative training approach, has begun to attract attention.
RL is like allowing students to learn through trial and error, offering rewards for correct actions and “criticism” for mistakes. Theoretically, this method can make models more flexible in handling various tasks and enhance their reasoning capabilities. However, it faces issues such as insufficient exploration of general capabilities in multimodal tasks and suboptimal bottlenecks caused by training constraints.
Thus, the OThink-MR1 technology was born.
So, how does it enable multimodal models to break through generalized reasoning capabilities?
Based on Dynamic Reinforcement Learning
OThink-MR1 is a framework and model based on dynamic reinforcement learning that supports fine-tuning of multimodal language models.
Its core “techniques” are twofold: a dynamic KL divergence strategy (GRPO-D) and a carefully designed reward model. Working in tandem, these components significantly boost the model’s learning efficiency and reasoning capabilities.

First, let’s look at the dynamic KL divergence strategy.
In reinforcement learning, exploring new strategies and leveraging existing experience are two crucial aspects. However, previous methods struggled to balance these two, often either wasting too much time in the exploration phase or relying too early on established experiences.
The dynamic KL divergence strategy acts like an “intelligent navigator” for the model, dynamically adjusting the balance between exploration and exploitation based on training progress.
To put it simply, during the initial stages of training, it encourages the model to act like a curious child, boldly exploring various possible strategies. As training progresses, it guides the model to gradually leverage previously accumulated experience, proceeding along more reliable paths.
This allows the model to learn more effectively and avoid getting stuck in local optima.
Next is the reward model. In OThink-MR1, the reward model serves as the grading standard used by teachers for students.
For multimodal tasks, researchers designed two types of rewards: one for verification accuracy and another for format compliance.
For example, in a visual counting task where the model must count objects in an image, it receives a verification accuracy reward if the count is correct. Additionally, if the model’s response adheres to the required format (e.g., writing down the answer in a specified structure), it earns a format reward.
These combined rewards are like a teacher evaluating students from multiple perspectives, helping the model understand where it excels and where improvements are needed, thereby facilitating more targeted learning.
Experimental Results
To verify the capabilities of OThink-MR1, researchers conducted a series of experiments.
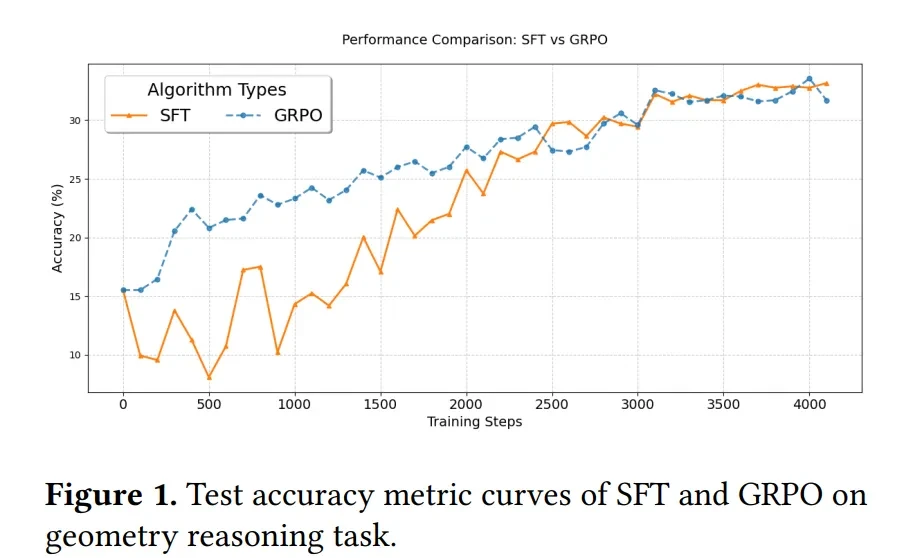
The first experiment investigated the impact of reward terms and KL divergence terms on original GRPO (a reinforcement learning-based method) during validation on the same tasks.
In geometric reasoning tasks, researchers adjusted the weight of the format reward and found that model performance improved significantly when the format reward weight was non-zero. This is similar to student essays, where not only content correctness but also formatting standards can earn extra points, helping students comprehensively improve their abilities.
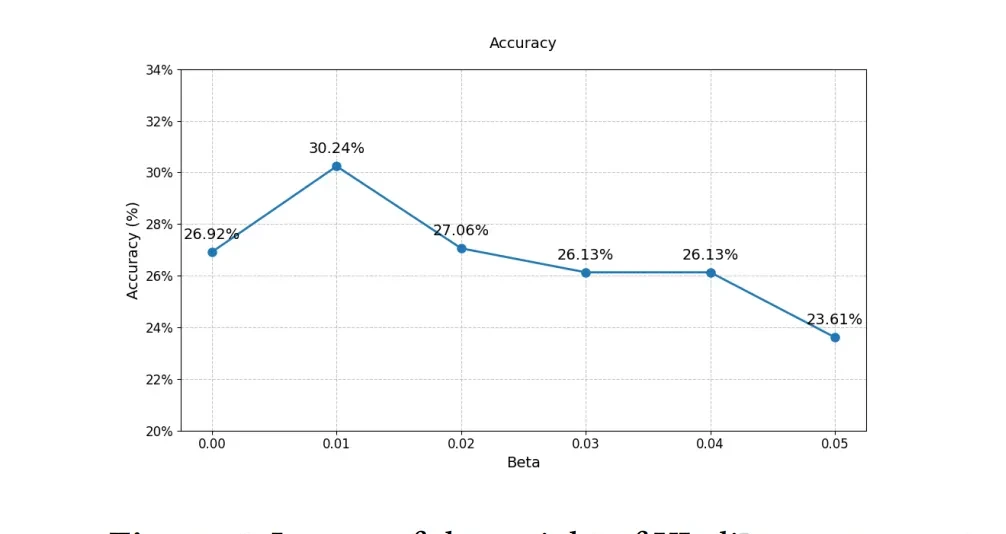
Simultaneously, when adjusting the KL divergence weight, they discovered that the model performed best with moderate weights; both excessively high and low weights led to decreased performance.
The second experiment involved cross-task evaluation, representing a true “final exam.”
Previous studies mostly evaluated model generalization capabilities across different data distributions within the same task. This experiment, however, directly challenged models with entirely different types of tasks.
Researchers selected visual counting and geometric reasoning tasks, which vary in difficulty and demand different capabilities from the model.
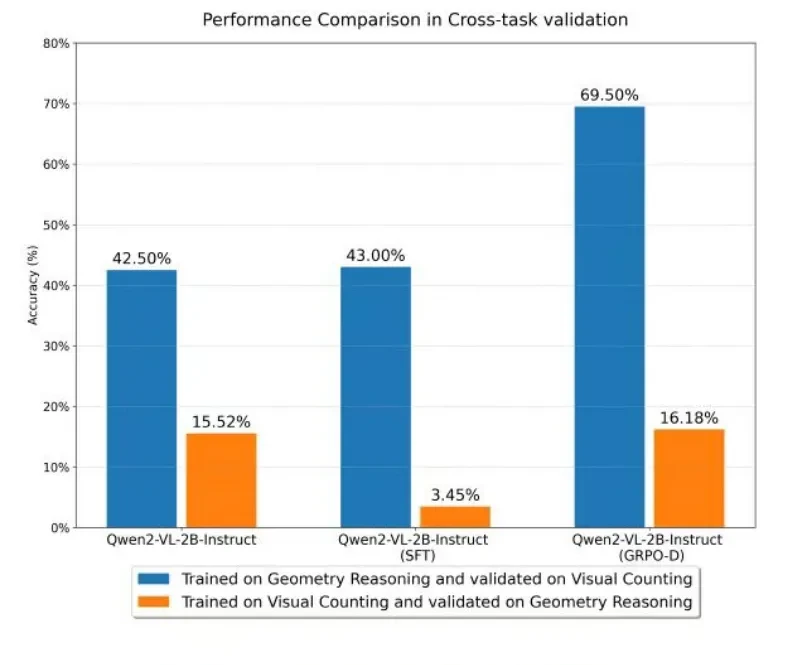
In cross-task validation, models trained with supervised fine-tuning performed poorly. It was like a student who only knew how to solve one type of problem; upon encountering a different format, they were completely lost.
In contrast, models trained with GRPO-D excelled. In generalization experiments moving from reasoning tasks to understanding tasks, their scores improved significantly compared to untrained models. Even in the more difficult generalization experiments moving from understanding tasks to reasoning tasks, they achieved notable progress.
This is akin to a student who not only excels in mathematics but can also quickly master language arts knowledge, demonstrating strong learning adaptability.

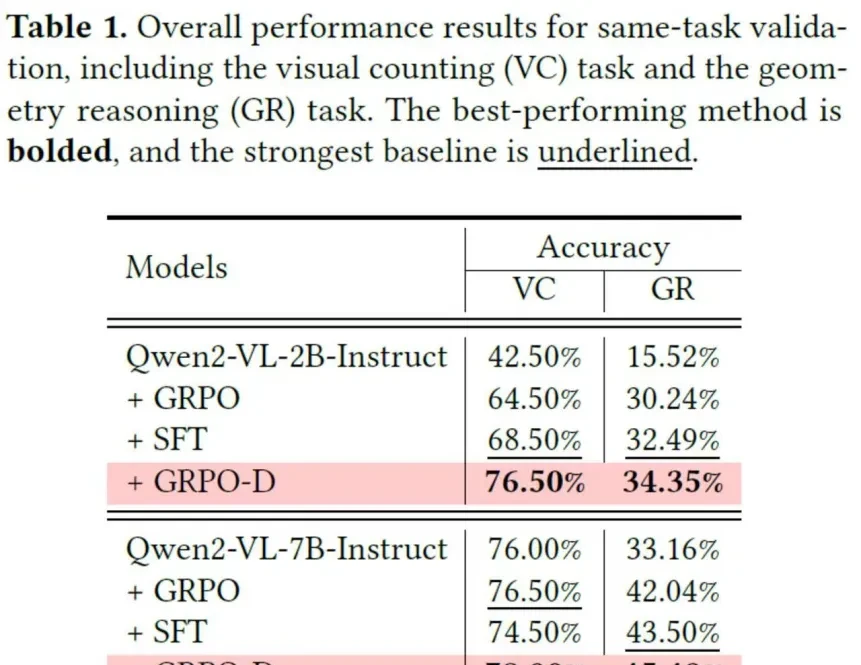
The third experiment focused on same-task evaluation.
Experimental results showed that in same-task validation, the GRPO method using fixed KL divergence underperformed compared to supervised fine-tuning. However, the GRPO-D within OThink-MR1 managed to turn the tables.
It outperformed supervised fine-tuning in both visual counting and geometric reasoning tasks. This is like a student with average grades who, after finding a suitable learning method, saw their scores skyrocket, directly surpassing peers who relied solely on rote memorization.
Overall, the emergence of OThink-MR1 paves a new path for the development of multimodal language models.
It highlights the immense potential of dynamic reinforcement learning in enhancing model reasoning and generalization capabilities. In the future, technologies like OThink-MR1 are expected to play significant roles across more domains.
Paper Link: https://arxiv.org/abs/2503.16081
• Title: OThink-MR1: Stimulating multimodal generalized reasoning capabilities through dynamic reinforcement learning
• Authors: Liu Zhiyuan¹, Zhang Yuting², Liu Feng¹, Zhang Changwang¹, Sun Ying², Wang Jun¹
• Affiliations: 1. OPPO Research Institute, 2. The Hong Kong University of Science and Technology (Guangzhou)