Huawei’s CloudMatrix Paper Reveals New Paradigm for AI Data Centers, Surpassing H100 in Inference Efficiency
The race to dominate the creative stack is no longer just about who can buy the most GPUs; it’s about who can make those chips actually work together without choking on their own complexity. As giants like xAI and Meta pour billions into brute-force hardware expansion, the bottleneck shifts from raw silicon to architectural efficiency—a shift that directly impacts how creators access compute and whether their workflows are optimized or just expensive.
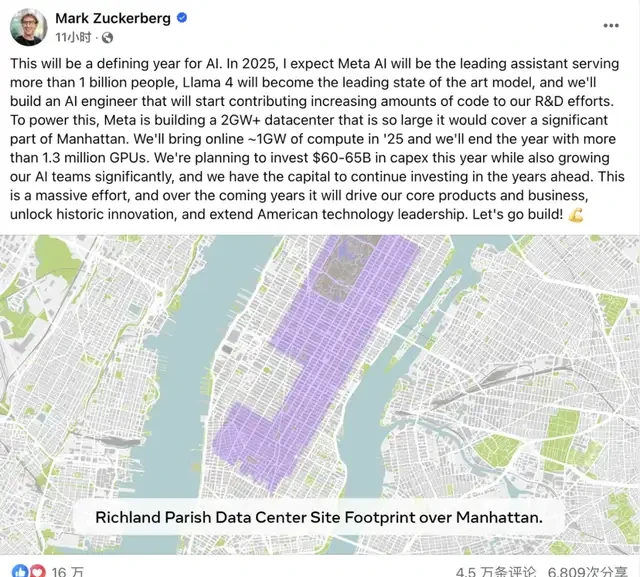
Elon Musk’s xAI plans to expand its 100,000-GPU supercomputing cluster tenfold, while Meta intends to invest $10 billion to build a data center with a capacity of 1.3 million GPUs…
The number of GPUs has become the direct indicator of an internet company’s AI capabilities.
Indeed, building AI computing power through the brute-force method of stacking GPUs is the simplest approach. However, more GPUs in a cluster do not necessarily mean better performance.
Although GPUs offer strong computational performance, they face numerous challenges when deployed in clusters. Even NVIDIA, the industry leader, struggles with communication bottlenecks, memory fragmentation, and fluctuating resource utilization rates.
In simple terms, due to limitations such as communication overhead, the full potential of GPUs cannot be fully realized.
I think scaling hardware without fixing architecture inflates costs for independent creators relying on cloud inference. For creators, proprietary efficiency gains often lock users into specific vendor ecosystems, reducing workflow flexibility.
Therefore, building cloud data centers for the AI era is not a one-time solution achieved simply by stacking cards into racks. The shortcomings of existing data centers must be addressed through architectural innovation.
Recently, Huawei released a substantial 60-page paper outlining its next-generation AI data center architecture design concept—Huawei CloudMatrix—and the first generation of productized implementation based on this concept: CloudMatrix384. Rather than simply “stacking cards,” Huawei’s CloudMatrix adopts architectural design principles centered on high-bandwidth, fully symmetric interconnectivity and fine-grained resource decoupling.
This paper is packed with technical insights, detailing the hardware design of CloudMatrix384 and introducing best practices for DeepSeek inference based on this platform: CloudMatrix-Infer.

So, how powerful is Huawei’s proposed CloudMatrix384? Simply put, it can be summarized in three aspects:
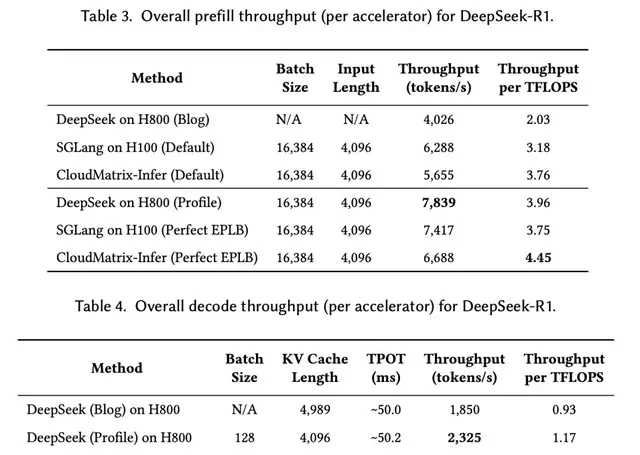
- High Efficiency: Prefill throughput reaches 6,688 tokens/s/NPU, and decode phase throughput reaches 1,943 tokens/s/NPU. In terms of computational efficiency, prefill achieves 4.45 tokens/s/TFLOPS, and the decode phase achieves 1.29 tokens/s/TFLOPS, both surpassing performance benchmarks on NVIDIA H100/H800 systems;
- High Accuracy: The accuracy of INT8 quantization benchmark tests for the DeepSeek-R1 model on Ascend NPUs matches that of the official API;
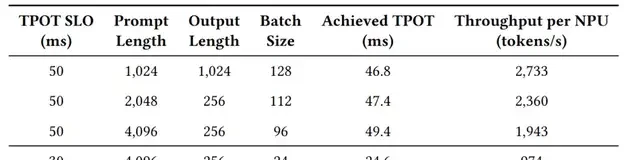
- High Flexibility: It supports dynamic adjustment of inference latency Service Level Objectives (SLOs), maintaining a decode throughput of 538 tokens/s even under strict 15ms latency constraints.
Huawei’s CloudMatrix Paper Reveals New Paradigm for AI Data Centers, Surpassing H100 in Inference Efficiency
The Shift from Workshop to Factory: Why We Need CloudMatrix384
I read the recent Huawei Cloud paper and what stood out immediately is the stark contrast it draws between legacy infrastructure and its new proposal. Traditional AI clusters operate like “dispersed small workshops,” where servers function independently with statically allocated computing power, memory, and network resources. This fragmentation causes severe bottlenecks—insufficient compute, memory bandwidth limits, and sluggish inter-node communication—when facing ultra-large-scale models.
Huawei’s response is CloudMatrix384, the first production-grade implementation of its next-generation AI data center architecture. The goal is to transform these disjointed units into “supercomputing factories.”

The core innovation is unified resource scheduling. CloudMatrix384 integrates 384 NPUs and 192 CPUs into a single super node. This allows computing power, memory, and network bandwidth to be managed uniformly, allocated precisely where needed rather than being siloed.
Data movement within this architecture mimics a high-speed factory conveyor belt. Because all chip connections rely on the ultra-high-bandwidth, low-latency Unified Bus (UB) network, data is transmitted directly between chips in a “fully symmetric” manner. This design avoids the “traffic jams” inherent in traditional hierarchical networks, enabling efficient handling of both massive parameter scales and inference tasks requiring frequent cache access through dynamic resource allocation.
On licensing, unified scheduling reduces idle time for creative render farms waiting on fragmented resources. I think direct chip-to-chip data flow could significantly shorten video rendering turnaround times.
△ Huawei CloudMatrix Architecture Vision
Having established the high-level vision, I followed the technical breakdown to understand how this architecture achieves its efficiency gains, particularly in interconnectivity.
Fully Symmetric Interconnectivity: Breaking the CPU Bottleneck
The paper highlights Fully symmetric interconnectivity (Peer-to-Peer) as a critical hardware innovation. In traditional AI clusters, the CPU acts as a “leader,” requiring NPUs to seek “approval and signing” for data transmission. This hierarchical overhead is particularly acute in large-scale model processing, where communication costs can consume up to 40% of total task duration.
CloudMatrix384 eliminates this bottleneck by treating CPUs and NPUs as a “flat-management team” with relatively equal status. They communicate directly via the UB network, removing the latency associated with hierarchical message passing.
For creators, lower communication overhead means faster iteration cycles for AI-assisted design workflows. On licensing, bypassing CPU bottlenecks allows creators to leverage more parallel processing power for complex assets.
The Flat Management Promise: Hardware That Doesn’t Trip Over Itself
I read Huawei’s CloudMatrix paper with an eye toward what this actually means for the people building models on top of these chips. The headline claim is “flat management,” and it hinges entirely on a hardware architecture called the UB network. This isn’t just a faster bus; it’s a non-blocking, fully connected topology using Clos design.
Here is the reality check: traditional clusters rely on RoCE networks capped at 200 Gbps (roughly 25 GB/s). They suffer from “north-south bandwidth bottlenecks,” where core switches get choked by traffic. Huawei claims their UB network gives each NPU 392 GB/s of unidirectional bandwidth. To put that in perspective, they say it’s enough to transmit 48 full HD movies per second.
But speed means nothing if the handshake is slow. Traditional NPUs use SDMA engines—essentially logistics hubs—that introduce a startup latency of about 10 microseconds. Huawei’s solution is AIV Direct Connect (AIV-Direct). By allowing direct writes to remote NPU memory via the UB network, they bypass those transit hubs entirely. Startup latency drops from 10 microseconds to under 1 microsecond.
I think lower latency means faster iteration cycles for researchers tweaking model architectures daily. For creators, bypassing SDMA engines reduces friction in high-frequency MoE token distribution workflows.
This architecture shines in Mixture of Experts (MoE) models, where single-communication time drops by over 70%. But hardware is only half the story; software support is doing heavy lifting here too. The UB network pairs with memory pooling to create a “global memory view.” NPUs and CPUs can access cross-node memory without caring about physical location.
During the decode phase, this allows NPUs to read KV caches generated during prefill directly. No CPU transit, no disk storage. Latency shifts from milliseconds to microseconds, pushing cache hit rates above 56%.
When I looked at the benchmarks for the 671B parameter DeepSeek-R1 model, the results were stark. Using FusedDispatch operators and AIV Direct Connect, token distribution latency fell from 800 microseconds to 300 microseconds. Prefill computational efficiency hit 4.45 tokens/second/TFLOPS, beating NVIDIA’s H100 at 3.75 tokens/second/TFLOPS.
Under strict constraints (TPOT < 50ms), decode throughput reached 1,943 tokens/second/NPU. Even when tightened to TPOT < 15ms, it held steady at 538 tokens/second. This suggests the “fully symmetric interconnectivity” isn’t just a lab curiosity; it’s stable under pressure.
The “Cloud” Abstraction: Selling Simplicity as a Service
The second pillar of this paper is the word “Cloud.” Huawei describes this as a cloud-oriented infrastructure software stack, acting like an “intelligent butler team.” Their goal is to turn complex hardware into a “cloud computing supermarket” where users don’t need to worry about the machinery underneath.
Huawei’s strategy here shows foresight; they determined early on that next-gen AI data centers must be built on this cloud-native foundation. After two years of refinement, they claim deploying CloudMatrix384 is now a “zero-threshold” process. Users can spin it up without managing hardware details.
On licensing, abstraction layers risk hiding the true cost and carbon footprint of inference workloads from creators. I think if the “cloud supermarket” locks you into proprietary tooling, migration costs for independent studios skyrocket.
The Software Stack Behind Huawei’s CloudMatrix384
When Huawei unveiled its CloudMatrix paper, it didn’t just show us faster silicon; it showed us a complex ecosystem designed to keep that silicon fed and efficient. As I followed the release details, what stood out to me was how much of the value proposition rests on this intricate software layer. For creators and developers, the hardware is only half the battle—the other half is whether you can actually deploy models without fighting the infrastructure.
The stack is built on five distinct modules: MatrixResource, MatrixLink, MatrixCompute, MatrixContainer, and the overarching ModelArts platform. While their roles are clearly defined, they are designed to work in tight collaboration. Let’s break down what each piece does for the people actually running these models.
MatrixResource: The Allocation Butler
At the foundation is MatrixResource. Think of it as the “resource allocation butler.” Its primary job is supplying physical resources within super nodes, with a specific focus on topology-aware computing instance allocation.
By running MatrixResource agents on Qingtian cards installed in each computing node, the system dynamically manages hardware resources like NPUs and CPUs. This ensures efficient scheduling according to topological structures, actively avoiding cross-node communication bottlenecks that can stall performance.
For creators, topology-aware scheduling reduces wasted compute time for large model training runs. On licensing, dynamic NPU management means less manual intervention when scaling up clusters.
MatrixLink: The Network Butler
Next is MatrixLink, which acts as the “network communication butler.” It provides service-oriented functions for UB and RDMA networks, supporting QoS guarantees, dynamic routing, and network-aware workload placement.
Its goal is to optimize communication efficiency among 384 NPUs within super nodes and across them. For example, in inference scenarios, MatrixLink assists in improving inference efficiency by 20% through parallel transmission and multi-path load balancing technologies. This is critical for keeping latency down when models are serving real-time requests.
I think a 20% inference boost directly translates to faster response times for end-users. For creators, multi-path load balancing reduces the risk of network congestion during peak traffic.
MatrixCompute: The Logical Super Node Butler
MatrixCompute plays the role of the “logical super node butler.” Its task is managing the lifecycle—“birth, aging, sickness, and death”—of super nodes. This covers everything from boot-up to fault recovery, including bare-metal provisioning, auto-scaling, and fault recovery.
Specifically, it orchestrates resources across physical nodes, constructing dispersed hardware components into tightly coupled logical super node instances. This achieves elastic resource expansion and high availability, ensuring that if one part of the cluster fails, the workload continues seamlessly.
On licensing, auto-scaling means you don’t need a dedicated ops team to manage cluster health. I think high availability protects your training jobs from costly interruptions due to hardware faults.
MatrixContainer: The Deployment Butler
Then there is MatrixContainer, described as the “container deployment butler.” Its function allows users to deploy AI applications onto super nodes as easily as sending a “package.”
Based on Kubernetes container technology, it packages complex AI programs into standardized containers. Users simply need to “click deploy,” and the system automatically assigns them to suitable hardware for execution. This abstraction layer is vital for simplifying what is often a highly technical deployment process.
For creators, standardized containers make it easier to move models between different cloud environments. On licensing, one-click deployment reduces the friction of getting new model versions into production.
ModelArts: The Full-Process Butler
Finally, we have ModelArts, the “AI full-process butler.” Located at the top of the software stack, it provides end-to-end services from model development and training to deployment. It offers three tiers: ModelArts Lite (bare-metal/containerized hardware access), ModelArts Standard (complete MLOps pipeline), and ModelArts Studio (Model-as-a-Service, MaaS).
Novice users can use ModelArts Lite directly to invoke hardware computing power. Advanced users can use ModelArts Standard to manage the entire process of training, optimization, and deployment. Enterprise users can use ModelArts Studio to turn models into API services (such as chatbots) with a one-click publish.
Thus, on top of CloudMatrix384’s inherent efficiency, this cloud-native infrastructure software stack plays a “winged tiger” role, making deployment even more convenient for everyone from individual researchers to large enterprises.
I think maaS options allow creators to monetize models without building custom serving infrastructure. For creators, unified pipelines streamline the journey from experiment to production API.
Software-Hardware Integration: Efficient, Convenient, and Flexible
The CloudMatrix paper doesn’t just boast raw power; it argues that true efficiency comes from treating software and hardware as a single, unified organism. This integration offers flexibility without sacrificing the ease of use that developers crave.
Take Huawei Cloud’s Elastic Memory Service (EMS). By using memory pooling to aggregate DRAM connected to CPUs into a shared pool, the NPU can directly access remote memory for KV cache reuse. The result? First-token latency drops by 80%, and NPU procurement costs fall by approximately 50%.
On licensing, lower hardware costs mean smaller studios can finally afford enterprise-grade inference speeds without breaking the bank.
The system also handles scaling with surprising grace. MatrixCompute automatically adjusts the number of NPUs in prefilling or decoding clusters based on real-time workload. Even under strict TPOT constraints of 15ms, it maintains a decoding throughput of 538 tokens per second.
Reliability is another pillar. Through deterministic operations services and Ascend Cloud Brain technology, fault recovery for a cluster of ten thousand cards takes just 10 minutes. In cases involving HBM or network link failures, the system targets a 30-second recovery time, reducing the impact of optical module failures by 96% to keep training and inference tasks continuous.
I think rapid fault recovery prevents overnight training runs from dying silently, saving researchers hours of lost compute time.
The software stack further supports multi-tenant partitioning of super-node resources. Different users share hardware while maintaining logical isolation—using namespaces to isolate cache data for different models ensures both data security and fair resource allocation.
Intelligent scheduling enables a “daytime inference, nighttime training” workflow. Inference tasks run during the day, while idle computing power fuels model training at night. Nodes switch between these modes in less than 5 minutes, significantly boosting overall utilization.
CloudMatrix384 is already live across four major Huawei Cloud nodes: Ulanqab, Horinger, Gui’an, and Wuhu. Users can provision compute on demand without building their own hardware environments. A 10-millisecond latency circle covers 19 urban agglomerations nationwide, supporting low-latency access.
Finally, full-stack intelligent operations lower the barrier to entry. The Ascend Cloud Brain fault knowledge base covers 95% of common scenarios, with one-click diagnosis accuracy reaching 80%. Network fault diagnostics take less than 10 minutes, effectively lowering the threshold for operations and maintenance (O&M).
For creators, automated O&M tools reduce the need for specialized infrastructure engineers, allowing creative teams to focus on model development rather than server management.
Huawei’s CloudMatrix Paper Reveals New Paradigm for AI Data Centers, Surpassing H100 in Inference Efficiency
Breaking the “Impossible Triangle”
I read Huawei’s latest paper on CloudMatrix384, and what stands out is how it challenges the traditional trade-offs between computing power, latency, and cost. By leveraging a “fully peer-to-peer architecture + software-hardware synergy” model, Huawei claims to have broken this “impossible triangle.”
On the hardware side, the fully peer-to-peer UB bus delivers an inter-card bandwidth of 392GB/s. This allows 384 NPUs to coordinate efficiently, keeping token distribution latency within 100 microseconds in EP320 expert parallel mode.
On licensing, high-speed inference reduces wait times for generative outputs, improving real-time creative workflows.
Software-wise, CloudMatrix-Infer uses a fully peer-to-peer architecture with large-scale EP parallelism and Ascend-customized fused operators. It also employs UB-driven disaggregated memory pools to maximize hardware efficiency. This design makes high computing power, low latency, and controllable costs simultaneously possible, making cloud-based large model deployment significantly more attractive.
The cloud enables unified planning at the data center level, constructing specialized high-speed network topologies that break through individual enterprises’ physical limitations. Crucially, it supports elastic scaling; businesses can dynamically adjust resources from dozens to hundreds of cards without modifying physical infrastructure.

Choosing the cloud also means users don’t need to hire specialized teams for complex tasks like model optimization, distributed training, and fault handling. CloudMatrix384’s automated O&M design reduces fault impact by 96%, keeping cluster fault recovery time for ten-thousand-card clusters within 5 minutes. This level of operational capability is difficult for most enterprises to build independently.
I think automated maintenance lowers the barrier to entry, allowing smaller studios to access enterprise-grade AI tools without dedicated DevOps staff.
More significantly, this cloud-based AI service model provides Chinese enterprises with a realistic path for implementation. For example, migrating DeepSeek-R1 from adaptation to online launch took only 72 hours, compared to two weeks for traditional solutions. This efficiency allows more companies to experiment with AI applications without bearing the risk of massive infrastructure investment.
For creators, faster deployment cycles mean creators can iterate on new models and features before competitors catch up.
CloudMatrix384 proves that domestic cloud solutions are not just “usable” but possess competitive advantages in both performance and cost-effectiveness.
AI Infrastructure Is Being Redefined
CloudMatrix384 represents more than a stronger AI supercomputer; it redefines what constitutes AI infrastructure. Technologically, it disrupts the past CPU-centric hierarchical design through UB, turning an entire super-node into a unified computing entity.
Looking ahead, Huawei’s paper outlines two development paths: expanding node scale and pursuing stronger decoupling. Expanding scale is intuitive as LLM parameter sizes grow, requiring more tightly coupled computing resources.
Decoupling can be viewed from both resource and application dimensions. In terms of resources, CPU and NPU will physically separate into dedicated pools, moving from logical to physical decoupling for better utilization.

In terms of applications, memory-intensive attention calculations during large model inference will be decoupled from the decoding path. Attention and expert components will also separate into independent execution services.
The authors depict a fully decoupled, adaptive, heterogeneous AI data center architecture that enhances scalability, flexibility, efficiency, and performance. As the paper notes:
In the future, computing resources will no longer be fixed physical devices but abstract capabilities that can be dynamically orchestrated.
Through CloudMatrix384 and its future vision, we are witnessing another technological iteration and a profound transformation in AI data center paradigms.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google