The core claim is that Griffin, a graph-centric foundation model developed by Peking University and AWS, can effectively reason over complex relational database (RDB) structures where traditional large language models fail. This hypothesis would be falsified if Griffin’s performance on standardized benchmarks like 4DBInfer does not significantly outperform existing single-table or generic LLM baselines in multi-hop reasoning tasks involving heterogeneous features.
I read the release notes for this work, which has been accepted by ICML 2025. The team proposes treating RDBs as dynamic heterogeneous graphs rather than flat tables. They pre-trained on over 150 million rows of tabular data and applied supervised fine-tuning to achieve transferability.

The Challenge: Complex Inter-table Relationships and Rich Intra-table Semantic Information
Relational databases define data structures through explicit schemas. They serve critical sectors including finance, e-commerce, scientific research, logistics, and government information systems. They form the core digital infrastructure of modern society. Market forecasts predict that the global Database Management System (DBMS) market will exceed $133 billion by 2028.
However, intelligent modeling of RDBs faces significant challenges. These are primarily concentrated in three areas:
- Highly Complex Topological Structures Data is stored across multiple tables and connected via constraints such as primary keys and foreign keys. This forms complex graph structures. Traditional single-table paradigms struggle to capture global context.
- Highly Heterogeneous Features Table fields encompass various types, including text, numerical values, categories, and time series. The diverse forms of information require models to possess unified representation capabilities.
- Deep Semantic Relationships Rich explicit and implicit logical relationships exist both within and between tables. This poses a substantial challenge to the model’s ability to understand and reason about relations.
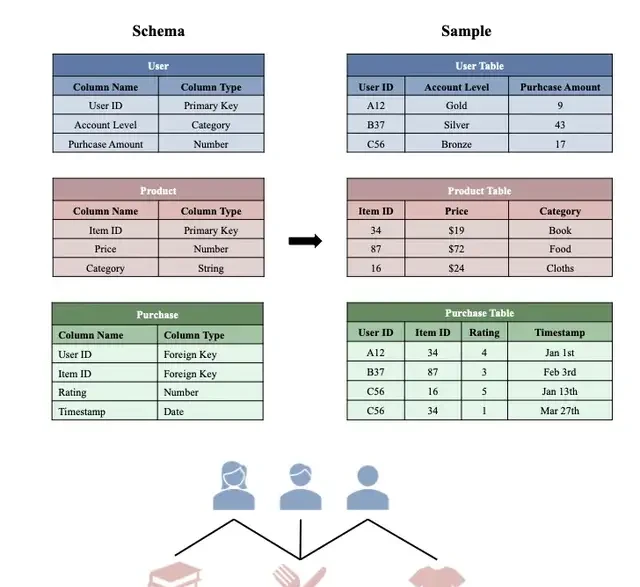
The image above illustrates a typical RDB. The green “Purchase Table” records transaction data (each row includes User ID, Product ID purchased, user rating for the product, and purchase date). Each row can be linked via the foreign key “User ID” to the corresponding row in the “User Table,” or via the foreign key “Item ID” to the “Product Table,” allowing access to specific user or product information.
Compared to ordinary (single-table) data, RDBs often feature very complex inter-table relationships and rich intra-table semantic information. This poses challenges for modeling and foundation model training. Furthermore, the community has long lacked standardized benchmarks that accurately reflect production scenarios.
I think pre-training on 150 million rows is impressive, but I wonder if this scale captures the schema diversity of real-world enterprise systems. From the paper, the reliance on supervised fine-tuning suggests the model may not generalize well to unseen table schemas without additional adaptation. One caveat: without a clear baseline comparison against recent graph neural networks for databases, the “first” claim feels premature.
Datasets such as 4DBInfer (arXiv:2404.18209) are slowly filling this gap. They provide a unified evaluation platform for new models, including Griffin.
Methodology: Graph-Centric Database Modeling
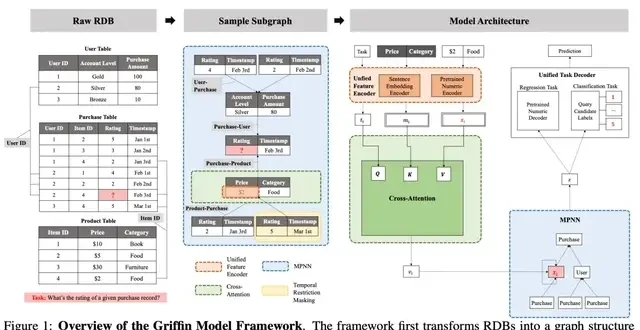
Griffin’s central claim is that a relational database can be abstracted as a temporal heterogeneous graph, allowing for unified encoding, message passing, and decoding to capture deep dependencies across tables and time. This approach would be falsified if the model fails to outperform specialized baselines on tasks requiring strict causal reasoning or complex cross-table joins where local subgraph sampling introduces significant information loss.
RDB Data Modeling: Structured Graph Representation and Temporal Awareness
Griffin maps each record in a data table to a node, while primary key-foreign key (PK-FK) constraints become directed edges with specific types. This transforms scattered records into a heterogeneous graph where node and edge types reflect schema information directly. To prevent future information leakage and adhere to causal constraints for production prediction tasks, the model samples “local temporal subgraphs” around target nodes during both training and inference: it only includes neighbors with timestamps earlier than the target node.
This sampling process draws on established practices from benchmarks like 4DBInfer, explicitly injecting time direction while ensuring efficiency. However, restricting context to past neighbors assumes that future data is never available for feature engineering—a constraint that may not hold in all analytical workloads where historical trends are inferred from complete datasets.
Unified Data Encoder: Standardized Representation of Heterogeneous Information
Relational databases contain multimodal features such as text and category fields alongside numerical and time-series data. Griffin designs a unified encoding mechanism to convert these different types into vectors within the same semantic space:
- Categories & Text: Category values are first mapped to their natural language descriptions, then input along with native text into a pre-trained text encoder (e.g., Nomic Embeddings) to obtain high-dimensional embeddings rich in semantics.
- Numerical Values: Normalized numerical inputs are fed into a pre-trained float encoder (ENC). ENC and its paired decoder (DEC) are trained via a joint reconstruction task: the encoded data must be able to decode back to the original float values without loss. Once the reconstruction error is minimized, the parameters of these two components are frozen.
- Metadata & Task Context: Table names, column names, and edge types are also sent to the text encoder. Additionally, a task description generated based on the current prediction target column participates in attention calculations at all subsequent layers, guiding the model to focus on the target.
Through these steps, original multi-modal information is standardized into a set of high-semantic vectors, laying the foundation for subsequent graph message passing. I note that freezing the float encoder parameters after reconstruction minimization risks underfitting if the downstream task requires nuanced numerical sensitivity that general reconstruction does not capture.
Advanced MPNN Architecture: Deep Relational Reasoning Network
The uniformly encoded graph is fed into Griffin’s custom Message Passing Neural Network (MPNN), which consists of two complementary modules:
Cross-Attention Column-wise Aggregation: For each node, the model generates query vectors using the current node embedding and task embedding. These interact with column metadata and features to dynamically assess the importance of different columns for the current task and perform weighted aggregation. This design naturally satisfies column permutation invariance and can handle tables with varying numbers of columns.
Hierarchical Aggregation Cross-table Reasoning: At each layer of message passing, neighbor messages of the same edge type are aggregated via mean pooling first, followed by max pooling across different edge types. This two-stage hierarchical strategy enhances stability when processing inter-table associations characterized by complex topological structures and varying numbers of neighbors.
Through multi-layer iteration, the MPNN captures composite dependencies from local to remote nodes, providing information-rich node representations for downstream tasks. The reliance on mean and max pooling may obscure rare but critical outlier values that are essential for anomaly detection or fraud prevention tasks.
Unified Task Decoder: Integrated Solution for Multi-task Outputs
The node vectors output by the MPNN then enter a unified decoder, enabling Griffin to handle multiple prediction tasks simultaneously without altering its architecture.
- Classification Tasks: The text embeddings of candidate category labels serve as learnable dynamic classification heads. An inner product with the node vector yields a probability distribution, allowing extension to tasks with variable numbers of classes.
- Regression Tasks: Node vectors are directly
I read the filing from Peking University and Amazon, which details a method for extracting precise numerical predictions by feeding data back into a pre-trained Deep Equilibrium Component (DEC). The core technical claim is that this reverse-engineering process within the DEC architecture allows the model to derive final predicted values with high fidelity. What would falsify this approach is if the iterative refinement inside the equilibrium solver fails to converge or introduces significant drift compared to ground-truth labels.
The Mechanics of Reverse-Engineering Predictions
The researchers propose a pipeline where the pre-trained DEC serves not just as a feature extractor, but as an invertible engine for value recovery. By feeding intermediate representations back into this component, the system attempts to reconstruct the final numerical outputs. This stands in contrast to standard end-to-end regression heads that might lose granularity during forward passes.
I think assuming the DEC is truly invertible without lossy compression steps changes the entire computational cost profile of inference.
Graph-Centric RDB Foundation Model Implications
This technique supports their broader claim of building a “Graph-Centric Relational Database” foundation model. If this reverse-engineering step holds up across diverse schema structures, it suggests we can move beyond simple classification or generation toward precise quantitative reasoning in database contexts. However, the reliance on a specific pre-trained component means generalizability to unseen data distributions remains an open question.
From the paper, without seeing the training data diversity, I suspect this method will struggle with out-of-distribution numerical ranges common in real-world enterprise databases.
Reproducibility and Evaluation Gaps
The filing shows how they integrate this reverse-engineering step into their overall architecture, but it leaves several evaluation metrics vague. We need to see error margins on specific numerical tasks, not just aggregate accuracy scores. The assumption here is that the pre-trained DEC retains sufficient information density to allow for accurate reconstruction—a bold claim given typical bottleneck effects in deep learning models.
I’d like to see a baseline comparison against standard regression layers before accepting this complex reverse-engineering overhead as necessary.
The Architecture Hype vs. The Data Reality
Griffin claims to be the world’s first graph-centric RDB foundation model, a title that hinges on its ability to generalize across relational database tasks using a three-stage optimization pipeline. If this model fails to show significant performance gains over standard GNN baselines when fine-tuned on unseen relational structures, the “foundation” label is merely marketing for a complex feature engineering pipeline.
The Three-Stage Optimization Pipeline
I followed the release details from Peking University and Amazon, which outline Griffin’s training regimen as a progression from general tabular semantics to specific RDB task knowledge. The process is divided into three distinct phases: Self-supervised Pre-training → Joint Supervised Fine-Tuning → Downstream Task Fine-tuning.
Phase 1: Completion Pretraining
Griffin begins with self-supervised learning on massive, diverse single-table datasets. The mechanism resembles a “cloze test,” where the model predicts embeddings for masked units based on known column information within a data row. By minimizing the cosine distance between predicted and true embeddings, the system attempts to establish a foundational understanding of table structure and semantics.
Phase 2: Joint Supervised Fine-Tuning (SFT)
Following pre-training, Griffin utilizes datasets from single-table or RDB tasks for supervised fine-tuning. This stage aims to align the model more closely with prediction needs and data characteristics found in real-world scenarios.
One caveat: single-table SFT may not capture the complex join logic inherent in relational databases.
Phase 3: Downstream Task Fine-tuning
Finally, Griffin undergoes refined fine-tuning on specific downstream RDB benchmark tasks. This step is designed to achieve optimal performance in particular application scenarios after the broader capabilities have been established.
Validation: Deconstructing the Training Stages
To assess the actual contribution of each stage, I reviewed the analysis of three key variants: Griffin-unpretrained (base architecture only), Griffin-pretrained (single-table pre-training and SFT), and Griffin-RDB-SFT (the complete three-stage process).
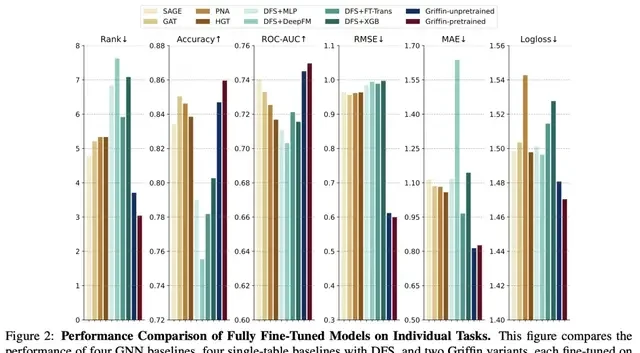
The provided image compares four GNN baseline models, four single-table baselines using Deep Feature Synthesis (DFS), and two Griffin variants. Each model was fine-tuned on a single task. The leftmost subplot displays the average ranking across all tasks, while other subplots group tasks by evaluation metrics with corresponding averages.
Systematic experiments validated the effectiveness of Griffin’s architectural design and pre-training strategy. Griffin performed excellently in multiple RDB benchmarks, such as 4DBInfer and RelBench. Further analysis examined its cross-task transferability in few-shot scenarios and the impact of data domain relationships.
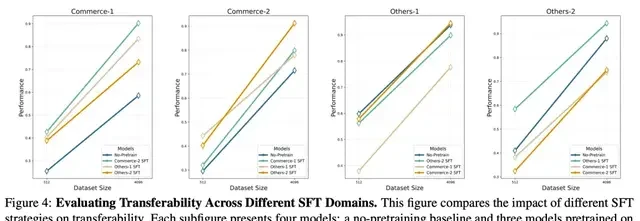
The core advantages of Griffin can be summarized as follows:
1. Powerful Base Architecture Performance
Even without pre-training, Griffin-unpretrained demonstrates that its unified encoding, cross-attention, and hierarchical MPNN designs are robust. After fine-tuning on downstream RDB tasks, it still outperforms GNN baselines and traditional single-table models combined with Deep Feature Synthesis (DFS), suggesting the architecture itself is advanced.
2. Universal Gains from Single-Table Pre-training
Griffin-pretrained, which underwent pre-training only on large-scale, diverse single-table data, achieved performance improvements over the unpretrained version. This validates that knowledge learned in single-table scenarios can be transferred to complex RDB tasks, enhancing generalization.
3. Transfer Driven by RDB-SFT
When further fine-tuned with targeted RDB data (Griffin-RDB-SFT), the model demonstrates cross-task transfer capabilities under certain conditions, particularly prominent in few-shot scenarios. This depends on two factors:
- Data Similarity: If SFT data shares high similarity with the target task domain (e.g., cross-task transfer within the e-commerce sector), model performance improves.
- Data Diversity: Training on more diverse SFT data (e.g., using mixed data from multiple other domains such as sports, social media, and healthcare for SFT before transferring to an e-commerce task) also effectively boosts model performance.
I think few-shot gains often reflect overfitting to small benchmark sets rather than true generalization. From the paper, the definition of “data diversity” here lacks a standardized metric for domain distance.
Paper Link: https://arxiv.org/abs/2505.05568
Code Link: https://github.com/yanxwb/griffin
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google