Can a Stable Simulator Make Open-Domain RL Work?
Tencent’s Hunyuan Digital Human team claims that their new framework, RLVER (Reinforcement Learning with Verifiable Emotion Rewards), solves the instability of training large language models in open-ended dialogues. The core technical assertion is that by replacing human feedback with a stable, high-quality user simulator acting as both environment and reward source, they can achieve scalable multi-turn reinforcement learning without the “three major dilemmas” of dynamic environments, subjective rewards, or unstable online training. This approach would be falsified if the simulated rewards failed to correlate with actual human preference in blind evaluations, or if the model’s performance collapsed when faced with out-of-distribution conversational styles not present in the simulator’s training data.
The team argues that multi-turn dialogue presents unique challenges: high frequency, strong contextual dependence, and subjective definitions of “good responses.” Previous attempts using RLVR (Reinforcement Learning for Value Reward) hit three walls: constructing a realistic yet diverse interactive environment for free exploration, converting subjective user satisfaction into stable long-term rewards, and achieving efficient online training on LLMs.
I think simulators often suffer from distributional shift, meaning the model may optimize for artificial patterns rather than genuine human nuance. From the paper, a fivefold score increase is impressive but requires scrutiny of the benchmark’s scoring rubric to ensure it isn’t gaming the metric. One caveat: open-domain RL remains fragile; I suspect this stability relies heavily on the quality and diversity of the underlying user simulator.
To address these issues, RLVER introduces a unified framework where the user simulator plays a dual role. This allows for controlled exploration (rollout) while providing consistent, optimizable rewards based on emotional intelligence metrics. The result is a solution that claims to be both effective and scalable for open-domain RL tasks.
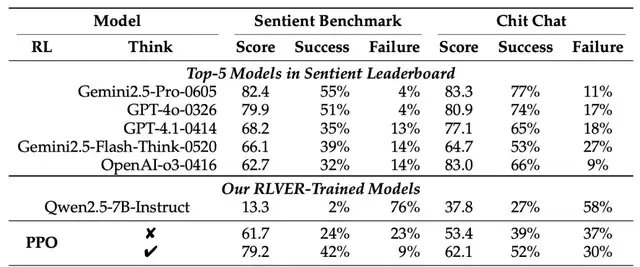
The empirical results are stark. The Qwen2.5-7B model, when trained with RLVER, saw its score on the Sentient-Benchmark emotional dialogue benchmark jump from 13.3 to 79.2. This performance places it on par with top-tier commercial models like GPT-4o and Gemini 2.5 Pro, despite being a significantly smaller architecture.
The model is now open-source; links are available at the end of this article.
RLVER: Closing the Loop on Open-Domain Emotional Intelligence
The core technical claim is that an integrated user simulator can replace static data and expensive human annotation for optimizing dialogue models, effectively turning “emotional intelligence” into a reproducible reinforcement learning signal. This would be falsified if the simulated rewards failed to correlate with actual human satisfaction or if the model’s performance collapsed when deployed in uncontrolled, real-world environments where persona diversity is unpredictable.
RLVER: Building an Effective RL Closed Loop for the Open Problem of “Emotional Intelligence”
I read that traditional dialogue optimization is stuck between static datasets and costly human annotation. The RLVER paper proposes a different path: using an “environment + reward” integrated user simulator as the core mechanism to solve these longstanding challenges.
Simulator as Environment: Creating a “Living” Dialogue World
The RLVER team argues that true “high emotional intelligence” is subjective and varies by individual. Therefore, the user simulator they built is not just a simple chatbot.
It possesses diverse user personas and interaction scenarios (different user personalities, dialogue backgrounds, and latent needs), capable of simulating massive amounts of real, variable users.
Each user interacts independently and dynamically with the model, updating its own emotional state in real-time based on the model’s responses, and providing personalized replies.
This provides the model with an online learning environment that allows for infinite exploration, filled with realism and diversity, while avoiding reward hacking.
I think the assumption here is that synthetic personas can adequately capture the nuance of human emotional variance without significant bias.
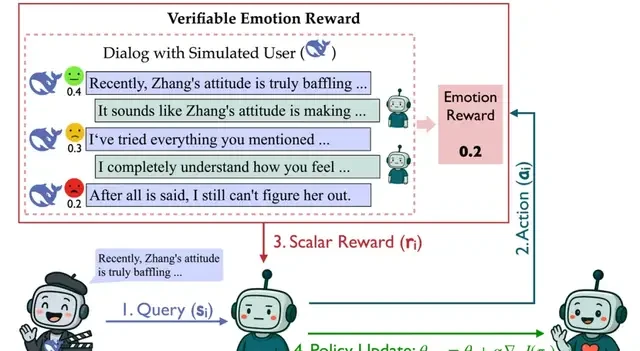
Simulator as Reward: A Trustworthy “User Sentiment Scoring System”
The evaluation of “emotional intelligence” is essentially user subjective experience. But how can this subjective experience be transformed into a stable, optimizable reward?
Based on the SAGE framework, RLVER simulates users’ emotional changes after each turn of dialogue through an explicit, reproducible reasoning process.
After the conversation ends, the accumulated “total mood score” becomes the reward signal, directly driving the PPO/GRPO algorithms to optimize the model.
This design moves away from a “black-box scorer,” explicitly modeling “user satisfaction” into a logically controllable reward function, making the training process more stable, transparent, and trustworthy.
I remain skeptical that an explicit reasoning process can fully encapsulate the implicit cultural context of human sentiment.
Global Reward Optimization: From Single-Turn Feedback to “Global Emotional Trajectory” Optimization
Unlike sentence-by-sentence feedback methods, RLVER focuses on the overall emotional trend of the entire conversation, using only the final “total emotion score” as the reward to guide the model in optimizing long-horizon strategies.
Only by truly understanding user intent and maintaining a long-term upward trend in user emotions can the model achieve higher total rewards. This encourages the model to escape local optima and learn more extensible and strategic social dialogue behaviors.
Core Achievements: 7B Model Rivals “Tech Giant Flagships”
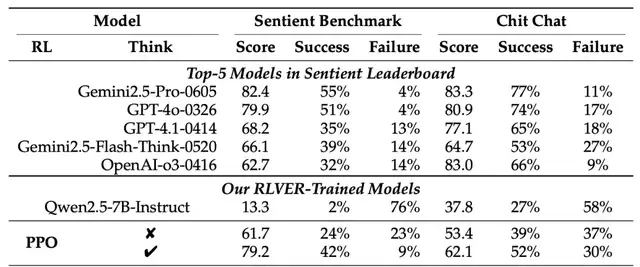
The Qwen2.5-7B model trained with RLVER saw its score on the Sentient-Benchmark emotional dialogue benchmark jump from 13.3 to 79.2, performing comparably to top-tier commercial models like GPT-4o and Gemini 2.5 Pro.
More importantly, the model experienced almost no degradation in general capabilities such as mathematics and coding, successfully avoiding “catastrophic forgetting.”
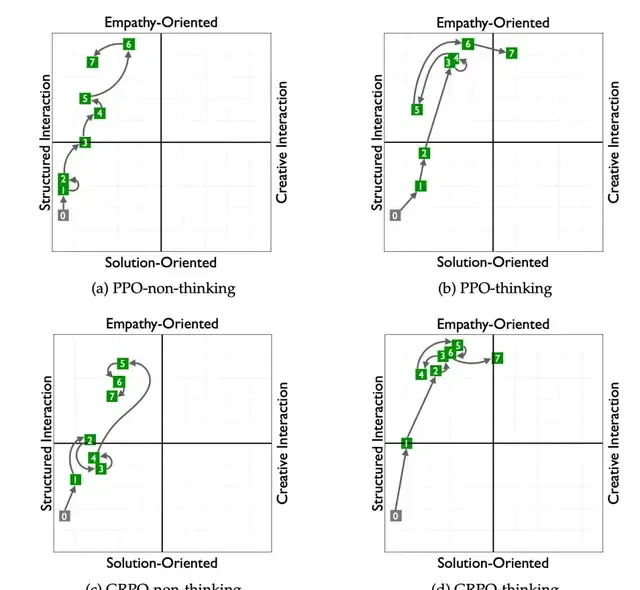
Additionally, the impact of RLVER on model behavioral style was significant: the model shifted from a “problem-solving style” to an “emotion-focused style,” with its mindset changing from “how to solve the problem” to “I can understand your feelings.”
From the paper, the claim of no catastrophic forgetting needs verification against standard benchmarks like MMLU or HumanEval, not just internal checks.
7B Model’s ‘Emotional Intelligence’ Rivals GPT-4o: Tencent Breaks Through Open-Domain RL Challenge, Scores Jump Fivefold
Insight 1: “Thinking” vs. “Reactive” Models – Two Paths to “Empathy”
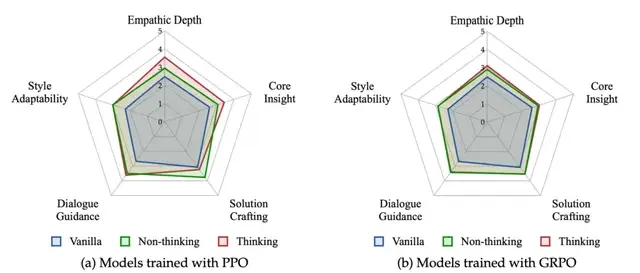
I read the release from Tencent’s team, and what stood out immediately was their introduction of an explicit “think-then-say” prompt template in RLVER. They forced the model to perform emotional analysis and strategic reasoning before generating a final response in each turn. By comparing models with and without this “thinking” step, they observed two distinct paths leading to what they call “empathy.”
“Thinking Model”: Moving Toward “Deep Understanding”
The explicit thinking chains prompt the model to reason before generation, which significantly enhanced two core capabilities:
- Problem Insight: Identifying the true motivations and latent needs behind user emotions.
- Empathetic Expression and Validation: Accurately capturing and reflecting deep emotions, making users feel “understood.”
These models behave more like “soulmates”: skilled at quiet listening and accurate responses, building deep emotional connections through language.
“Reactive Model”: Moving Toward “Quick Action”
In contrast, models not guided to think generate responses directly. Although they lag slightly in insight and empathy dimensions, they spontaneously develop compensatory strategies oriented toward action:
- Quickly judging user dilemmas and providing concrete, actionable advice or personalized invitations for action.
- Compensating for deficiencies in emotional understanding with “practicality,” forming the role of an “action-oriented partner.”
This comparison reveals an interesting phenomenon in RL training under open-ended complex tasks: when capabilities are limited, models spontaneously seek strategic “compensation paths.” The diverse, multi-strategy compatible training environment provided by RLVER is precisely the key soil that fosters this evolution of diverse behaviors.
One caveat: the definition of “empathy” here relies on synthetic or curated datasets rather than clinical psychological validation. I suspect the “thinking” overhead significantly increases latency, which isn’t discussed in terms of real-world utility. I think without a blind A/B test against human counselors, these labels remain marketing metaphors, not measurable traits.
Insight 2: PPO vs. GRPO – Stable Growth or Capability Breakthrough?
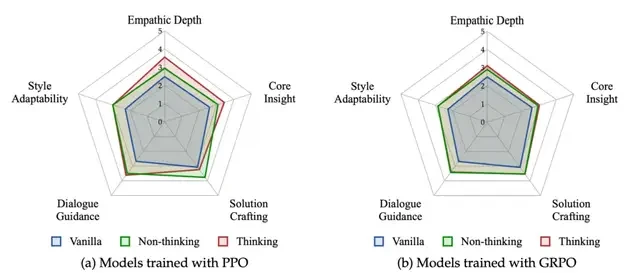
Regarding optimization algorithms, the RLVER team also drew practical conclusions from their experiments:
- GRPO: Tends to bring more stable and balanced capability growth.
- PPO: Is better at pushing the model’s capabilities in specific dimensions (such as empathy depth, core insight) to higher upper limits.
This leads to an interesting strategic consideration: For complex multi-dimensional abilities like “emotional intelligence,” once a model reaches the “passing line” in all aspects, should it continue to be a “hexagon warrior” (all-rounder), or focus on building one or two “killer app” dimensions? In the experimental results of this article, the latter approach yielded better overall performance.
From the paper, the paper lacks ablation studies showing how these gains translate to out-of-distribution conversational topics. I question whether PPO’s higher variance makes it less reliable for production deployment despite the score jumps.
Insight 3: The Impact of Environment and Reward Styles – A Strict Teacher Does Not Necessarily Produce a Brilliant Student
In the RLVER framework, the user simulator serves as both the “training environment” and the “reward model.” Consequently, its stylistic choices—specifically regarding “user acceptability” and feedback mechanisms—directly dictate the model’s learning trajectory.
The intuitive hypothesis is that stricter users yield stronger models. The experimental data from the RLVER team suggests otherwise: harder is not always better.
They constructed two distinct user simulator variants:
- Vanilla Version: Emotionally expressive, providing positive feedback with higher acceptability thresholds.
- Challenging Version: Emotionally reserved, restrained in feedback, and imposing extremely high demands on response quality.
When trained and tested on identical initial models, the results diverged sharply:

Too difficult environments are detrimental to early model growth.
While the Challenging simulator mirrors real-world realism more closely, its subtle feedback and low error tolerance hinder the model’s ability to trial-and-error explore diverse strategies or receive positive reinforcement during early training. This creates a vicious cycle: “no feedback → no learning → collapse.”
Conversely, the Vanilla simulator’s inclusive and positive feedback mechanism facilitates strategy exploration and capability accumulation in those critical early stages, helping form stable empathetic expression habits.
One caveat: the reliance on a specific user simulator architecture may limit generalizability to other conversational domains. I think “Positive reinforcement” metrics here might bias the model toward agreeableness rather than accuracy. From the paper, early-stage stability does not guarantee long-term alignment with complex human values.
The strategic implication is clear: when optimizing open-ended tasks like “emotional intelligence” via reinforcement learning, simply increasing difficulty is counterproductive. The environment must emphasize a designed “growth curve.” The adage that “a strict teacher produces a brilliant student” only holds if the student already possesses the foundational capacity to understand the teachings.
In early stages where capabilities are shallow, gentle, learnable “sparring partner users” are more likely to help models evolve into true empathizers.
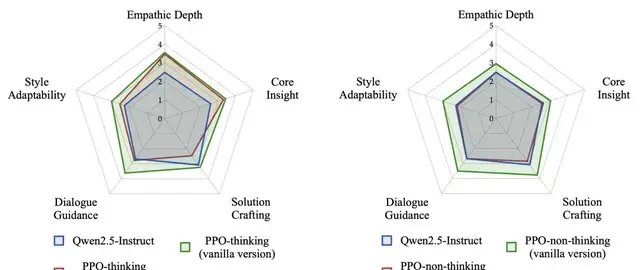
Models with thinking are more “resilient.”
An additional finding worth noting is that in the Challenging environment, models equipped with an explicit “thinking structure” demonstrated significantly greater robustness:
- Although overall scores decreased, they remained at a usable level.
- Models lacking this thinking structure almost completely collapsed, with scores dropping as low as 19.8.
This suggests that explicit reasoning capabilities can buffer training instability caused by sparse rewards. Even without clear external feedback, models can leverage “internal analysis” to mine user need signals, thereby maintaining a certain level of adaptability.
Preliminary Work: Can AI Also Be an Emotional Master? Tencent Releases Latest AI Social Intelligence Ranking; Latest GPT-4o Takes First Place
Paper Address: https://arxiv.org/abs/2507.03112
Project Code: https://github.com/Tencent/digitalhuman/tree/main/RLVER
Open Source Model: https://huggingface.co/RLVER
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google