What’s the Difference Between a 4B Model and Top-Tier Commercial LLMs in Mathematical Reasoning?
The University of Hong Kong NLP team, in collaboration with ByteDance Seed and Fudan University, has released Polaris, a reinforcement learning (RL) training recipe.
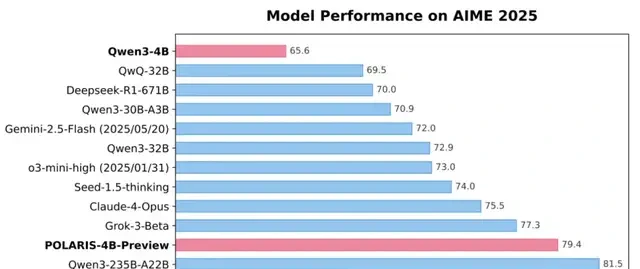
By scaling RL, Polaris enables a 4B model to achieve mathematical reasoning scores of 79.4 on AIME25 and 81.2 on AIME24, surpassing numerous commercial large language models such as Seed-1.5-thinking, Claude 4 Opus, and o3-mini-high (as of January 31, 2025).
Furthermore, the lightweight nature of Polaris-4B allows it to be deployed on consumer-grade graphics cards.
The detailed blog post, training data, model weights, and code have all been open-sourced. Links are provided at the end of this article.
Parameter Configuration Centered on the Target Model
Previous RL training recipes, such as DeepScaleR, have demonstrated the powerful effects of scaling RL on weaker base models.
However, can scaling RL replicate such significant improvements for currently state-of-the-art open-source models (such as Qwen3)?
The Polaris research team provides a clear answer: Yes!
Specifically, through just 700 steps of RL training, Polaris successfully enabled Qwen3-4B to approach the performance of its 235B counterpart in mathematical reasoning tasks.
When applied correctly, RL holds immense potential for development.
The secret to Polaris’s success lies in this principle: both training data and hyperparameter settings must be tailored specifically to the model being trained.
Training Data Construction
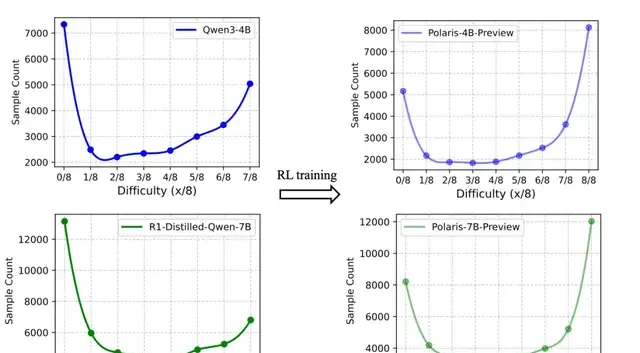
The Polaris team discovered that for the same dataset, base models with different capabilities exhibit a mirror-image distribution of difficulty levels.
For each sample in the DeepScaleR-40K training set, researchers used two models—R1-Distill-Qwen-1.5B and R1-Distill-Qwen-7B—to reason through the problem eight times each. They then counted the number of correct answers to measure the difficulty level of each sample.
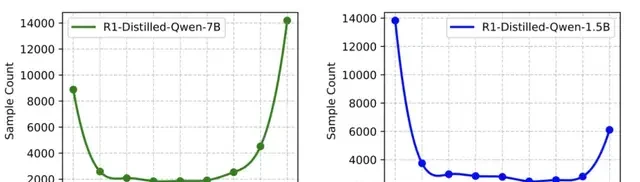
Experimental results showed that most samples were located at the extremes (8/8 correct or 0/8 correct). This means that while the dataset was challenging for the 1.5B model, it was insufficient to effectively train the 7B model.
Polaris proposes constructing a data distribution slightly biased toward harder problems, shaped like an inverted “J.” Distributions overly skewed toward easy or hard problems result in samples that offer no advantage occupying too large a proportion of each batch.
The team filtered open-source datasets DeepScale-40K and AReaL-boba-106k, removing all samples with 8/8 correct answers, ultimately forming an initial dataset of 53K samples.
Although a good initial dataset was obtained, it is not the “final version” of the training data.
During reinforcement learning training, as the model’s “mastery rate” over training samples increases, difficult problems become easy ones.
To address this, the research team introduced a dynamic data update strategy during training. The pass rate for each sample was updated in real-time based on reward calculations. At the end of each training stage, samples with excessively high accuracy were removed.
Sampling Control Centered on Diversity
In RL training, diversity is considered a key factor in improving model performance. Good diversity allows the model to explore broader reasoning paths and avoids getting stuck in overly deterministic strategies during the early stages of training.
Diversity during the rollout phase is primarily controlled via top-p, top-k, and temperature (t). Most current works use top-p=1.0 and topk=-1, which achieves maximum diversity; however, there is no unified setting for sampling temperature t.
Currently, mainstream methods for setting t fall into two categories: 1) Using a recommended decoding temperature, such as 0.6 set in the Qwen3 demo; or 2) Setting it directly to an integer value of 1.0.
However, neither approach proved optimal in Polaris’s experiments.
Balancing Temperature, Performance, and Diversity
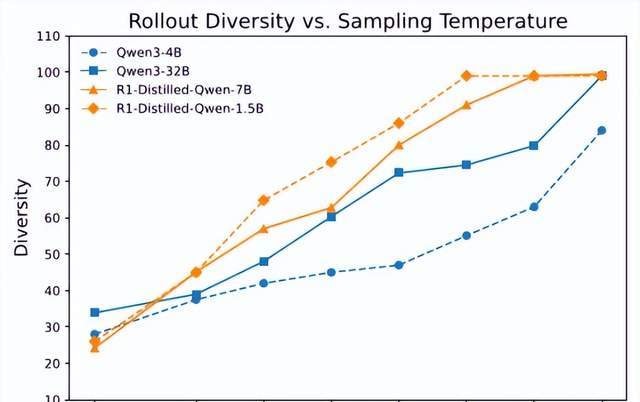
The Polaris team conducted a series of experiments to analyze the relationship between sampling temperature, model accuracy, and path diversity.
To quantify the diversity of sampling trajectories, they employed the Distinct N-gram metric (n=4) to measure the proportion of unique consecutive word groups in generated text: scores closer to 1.0 indicate higher diversity, while lower scores suggest higher repetition rates.
The results showed that higher temperatures significantly improved diversity, but different models exhibited considerable variation at the same temperature. As seen in the chart above, for these two models, a sampling temperature of 0.6 clearly lacked sufficient diversity.
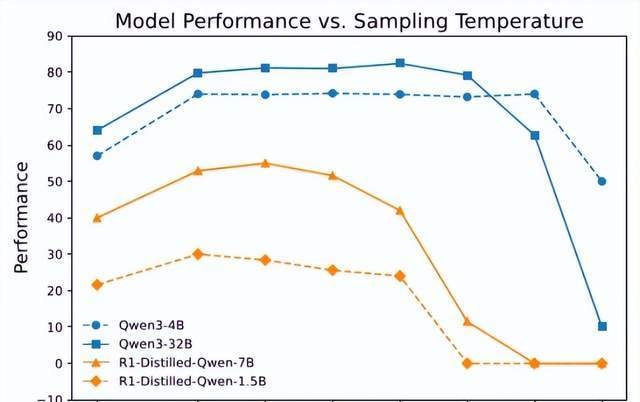
However, simply increasing the temperature is not always better; changes in performance must also be considered.
The Polaris team found that model performance followed a “low-high-low” trend as temperature increased. For example, setting the sampling temperature to 1.0 was too high for the Deepseek-R1-distill series models but slightly low for the Qwen3 series.
This indicates that ideal temperature design requires fine-tuning for each specific model; no single hyperparameter fits all models.
Defining Temperature Intervals
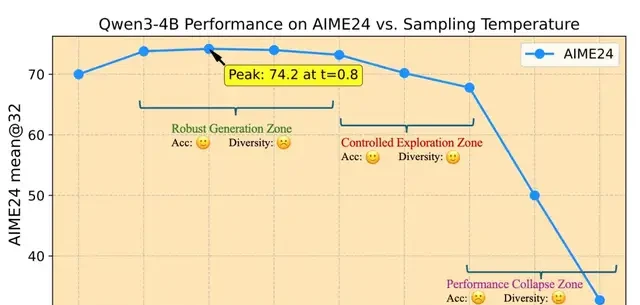
Based on experimental trends, the Polaris team identified three zones for model sampling temperature:
- 1. Robust Generation Zone
- In this zone, performance fluctuations are minimal. The decoding temperature used during testing is typically selected from this zone.
- 2. Controlled Exploration Zone
- Although temperatures in this zone cause a slight decrease in model performance compared to the robust generation zone, the drop is within acceptable limits while significantly boosting diversity, making it suitable for use as the training temperature.
- 3. Performance Collapse Zone
- When sampling temperature exceeds a certain range, performance drops sharply.
Based on the patterns observed above, the Polaris team proposed using the temperature from the controlled exploration zone as the initial temperature.
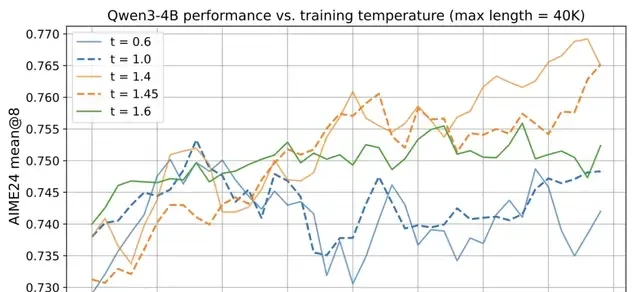
Experiments show that commonly used temperature settings of t=0.6 or t=1.0 are too low, restricting the model’s exploration space and making it difficult to fully unlock its Reinforcement Learning (RL) potential.
Therefore, Polaris sets the initial training temperature for Qwen3-4B to 1.4.
Dynamic Temperature Adjustment
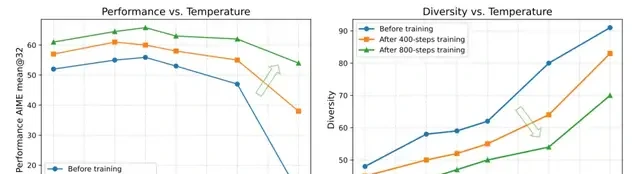
As performance improves, diversity also shifts. As training converges, the proportion of shared N-grams across different paths increases, thereby narrowing the exploration space.
Using the initial temperature throughout the entire training process leads to insufficient diversity in the later stages.
To address this, the Polaris team proposes a strategy for dynamically updating sampling temperatures during RL training: before each stage begins, they employ a search method similar to the one used for initializing the temperature. This ensures that the diversity score at the start of subsequent stages remains comparable to that of the first stage.
For example, if the diversity score at the beginning of the first stage is 60, Polaris will select a temperature in each subsequent stage that pulls the diversity score back up to 60 for training.
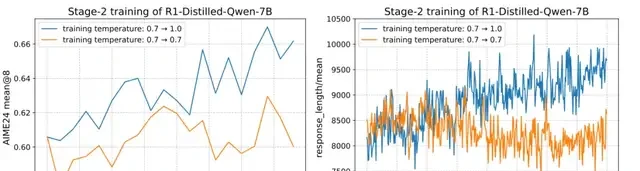
Comparative experiments show that using a single temperature throughout training yields inferior results compared to multi-stage temperature adjustment.
Multi-stage temperature adjustment not only leads to better RL training outcomes but also ensures more stable increases in response length.
Chain-of-Thought Length Extrapolation
During the training of Qwen3-4B, a significant challenge was long-context training. Since the model’s responses were already very long, extending them further required prohibitively high computational costs.
Qwen3-4B has a pre-training context length of only 32K tokens. In the RL phase, Polaris set the maximum training length to 52K. However, in practice, less than 10% of the training samples reached this maximum sequence length, meaning that very few samples were actually used for long-text training.

To evaluate the long-text generation capabilities of Polaris-4B-Preview, the Polaris research team selected 60 problems from AIME 2024/25. They performed 32 reasoning attempts per problem, totaling 1,920 samples, and categorized them into three groups based on response length:
- Short Text Group: Response length less than 16K tokens;
- Medium Text Group: Response length between 16K and 32K tokens;
- Long Text Group: Response length exceeding the pre-training length of 32K tokens.
Statistical results indicated that the accuracy for the long-text group was only 26%, demonstrating that the model’s performance is significantly constrained when generating Chain-of-Thought (CoT) responses longer than its pre-training context.
Since RL exhibits disadvantages with long contexts, poor CoT performance may stem from insufficient training on long texts.
To address the scarcity of long-text training samples, the team introduced length extrapolation technology. By adjusting RoPE (Rotary Position Embedding), the model can handle sequences longer than those seen during training at inference time, thereby compensating for deficiencies in long-text training.
Specifically, the research team adopted YaRN as the extrapolation method and set the expansion factor to 1.5, as shown in the configuration below:

Experimental results show that applying this strategy increased the accuracy of responses exceeding 32K tokens from 26% to over 50%.
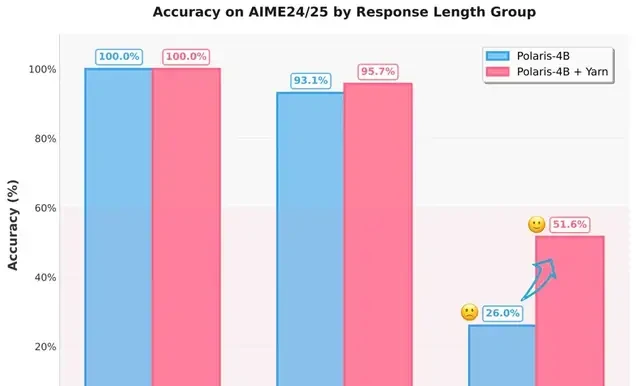
Multi-Stage Training
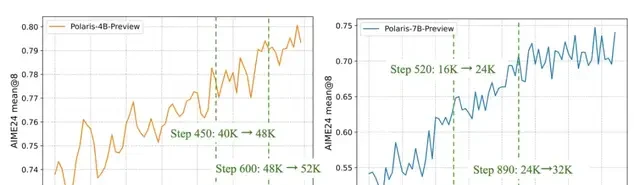
Polaris employs a multi-stage training approach. In the early stages, the model uses a shorter context window; once performance converges, the context window length is gradually increased to broaden the model’s reasoning capabilities.
While this strategy can be effective for some models, selecting an appropriate maximum length in the initial stage of multi-stage training is crucial, as different base models vary in their token utilization efficiency.
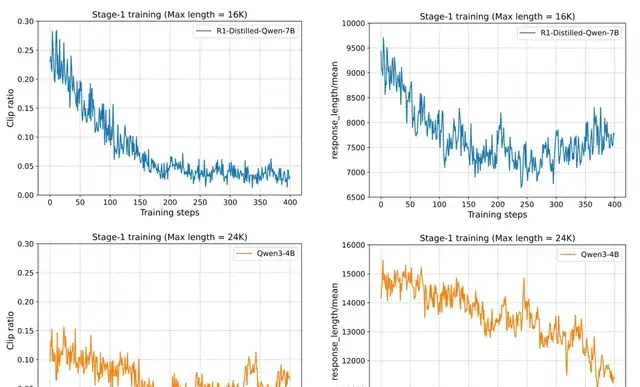
Experiments revealed that for DeepSeek-R1-Distill-Qwen-1.5B/7B, training with shorter response lengths yielded good results. However, for Qwen3-4B, performance dropped sharply even when the response length was only 24K and the truncation rate was below 15%. This decline was difficult to recover from in later stages.
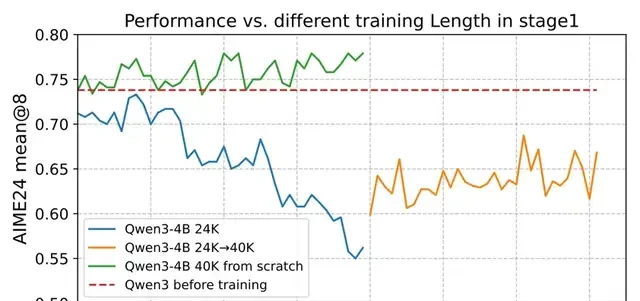
Generally, it is safer to encourage the model to “think longer” from the start. For Qwen3-4B, experiments observed steady performance improvements when starting with a 40K response length from scratch. This stands in sharp contrast to schemes that started with 24K or transitioned from 24K to 40K.
Key Takeaway: When computational resources allow, start directly with the maximum decoding length recommended by the official repository.
Evaluation Results
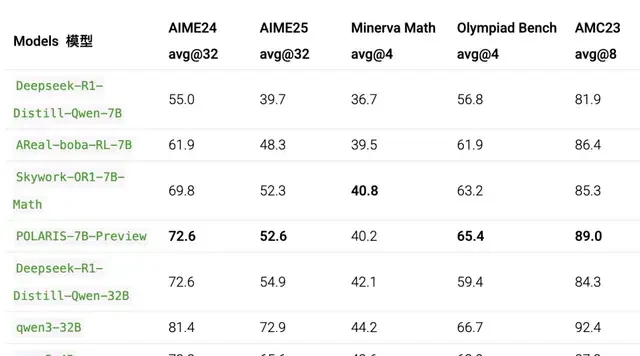
The Polaris model requires a higher sampling temperature and longer response lengths compared to Qwen3; all other settings remained identical.
For AIME 24 and AIME 25, the table above reports the average performance across 32 runs.
As seen in the results, Polaris enabled the 4B model’s math reasoning capabilities (achieving 79.4 on AIME 25 and 81.2 on AIME 24) to surpass numerous commercial large language models, performing best in most evaluations.
_notion address: https://honorable-payment-890.notion.site/POLARIS-A-POst-training-recipe-for-scaling-reinforcement-Learning-on
-Advanced-ReasonIng-modelS-1dfa954ff7c38094923ec7772bf447a1_
Blog URL: https://hkunlp.github.io/blog/2025/Polaris/
Code Repository: https://github.com/ChenxinAn-fdu/POLARIS
Hugging Face Hub: https://huggingface.co/POLARIS-Project