It is often said that general-purpose large language models handle translation with ease. However, someone just flipped the table.
Ziyou Translation Model 2.0, a 14-billion-parameter model from NetEase Youdao, has achieved first place in industry benchmarks, surpassing a host of mainstream domestic and international general-purpose large language models in translation quality.
This is Ziyou Translation Model 2.0 (hereinafter referred to as Ziyou 2.0). In English-to-Chinese translation, it easily outperforms 12 mainstream general-purpose models, including Claude 3.5 Sonnet. In Chinese-to-English translation, it performs on par with Claude 3.5 Sonnet.
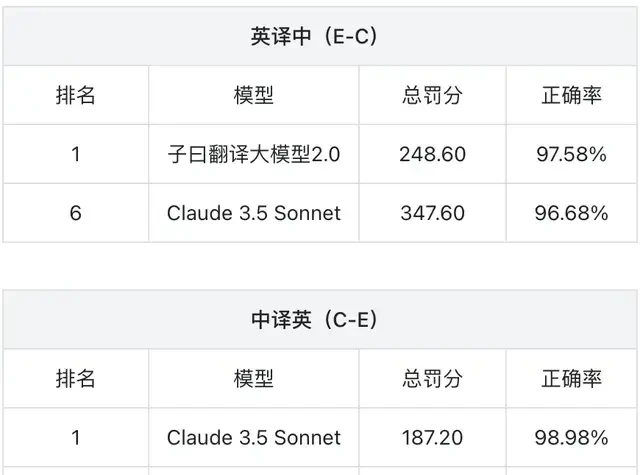
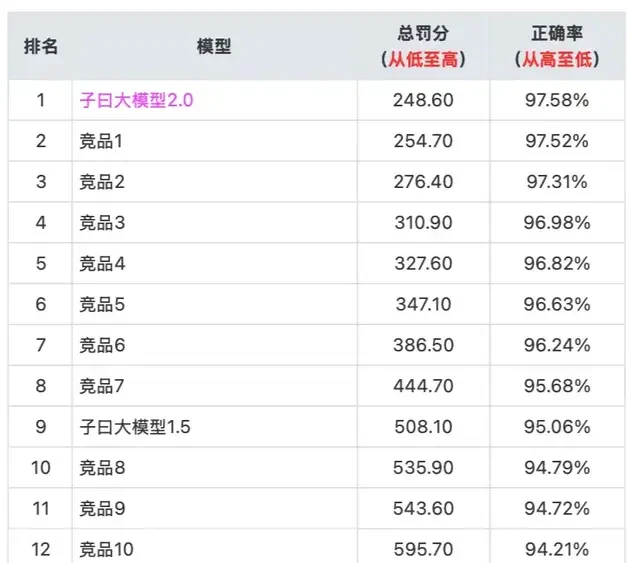
△ Display of evaluation results; a lower penalty score indicates better model performance.
Let’s look at a practical example. How do you translate “My fate is determined by me, not by heaven” into English?
Ziyou 2.0:
I’m the master of my destiny.
Claude 3.5 Sonnet:
My fate is in my own hands, not in heaven’s control.
(Alternative translations could be: “I control my destiny, not the heavens” or “My destiny is determined by me, not by fate”)

Comparing the two, even though Claude provided three responses, none are as natural, concise, and powerful as Ziyou’s.
Ziyou 2.0 is also more accurate in specialized translation fields.
When compared with the latest version of Claude-3.7, Ziyou 2.0 accurately translated the medical term “clear cell renal cell carcinoma.”

However, Claude-3.7 translated it as “clear cell renal cell carcinoma” (using the incorrect term “Qingxi” instead of “Touming”).

Unexpectedly, in such specialized fields, the performance of general-purpose large models still has room for improvement.
(Anxiety about being replaced by AI can be temporarily alleviated.)
So, why can a small model designed for vertical domains easily defeat a general-purpose model that is more than ten times larger?
Let’s look at further performances of Ziyou 2.0.
Effortlessly Mastering Professional Translation of Papers and Financial Reports
In summary, Ziyou 2.0 demonstrates outstanding performance in more professional translation scenarios.
The basic requirements for translation are faithfulness, expressiveness, and elegance—meaning faithful to the original text, fluent and clear, and appropriate word choice. The more specialized the field, the greater the difficulty of translation.
Therefore, we set up several distinct aspects to test the performance of professional translation models versus general-purpose large language models:
- Academic paper translation
- Financial report translation
- Poetry translation
The main dimensions considered include:
- Accuracy
- Fluency
- Avoidance of unnecessary additions or omissions
- Elegance/Idiomaticity
First, in terms of corpus richness, Ziyou 2.0 is clearly superior.
After all, when given “Strawberry Shake-Shake,” it knows to translate it as: Strawberry Shake-Shake.

In classical poetry translation, Ziyou 2.0 provides translations that are more vivid and preserve the artistic conception, while also considering rhyme. This further conveys the charm of ancient Chinese poetry into English, showing a touch of translator Xu Yuanchong’s style.

At this point, Claude 3.5 Sonnet pales in comparison; it merely conveys the meaning but fails to capture the essence.

In academic paper translation scenarios, accuracy requirements are higher. Different fields have their own specialized vocabulary, requiring AI translators to not only master a vast number of proper nouns but also analyze the corresponding context based on surrounding text to provide correct translations.
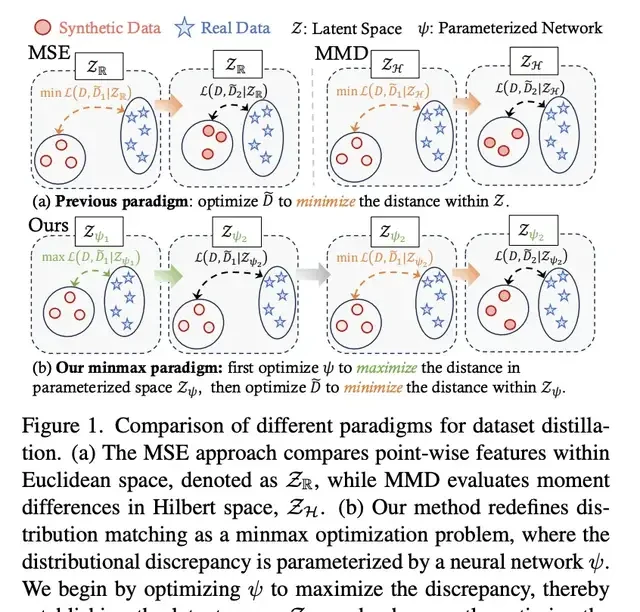
Taking the task of translating a perfect-score paper from CVPR 2025 as an example, the translation task assigned was: translate the caption in this image.
(Copying and pasting the caption text into the model; no multimodal input is involved.)
{kind=link}
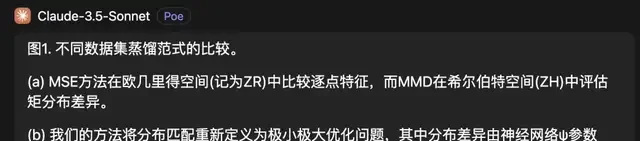
As seen in the original figure caption, MSE and MMD were provided only as acronyms. Ziyu 2.0 accurately translated these English acronyms into specialized computer science terminology, providing a more complete and correct translation (bolded text below).
Ziyu Large Model 2.0:
Figure 1. Comparison of different dataset distillation paradigms. (a) The Mean Squared Error (MSE) method compares point-to-point features in Euclidean space (denoted as ZR), while the Maximum Mean Discrepancy (MMD) evaluates moment differences in Hilbert space (ZH).

In contrast, Claude 3.5 Sonnet did not achieve this:
Figure 1. Comparison of different dataset distillation paradigms. (a) The MSE method compares pointwise features in Euclidean space (denoted as ZR), while MMD evaluates moment distribution differences in Hilbert space (ZH).
For specialized terms it does not understand, Ziyu 2.0 chooses not to translate rather than providing an incorrect translation. Compared to general-purpose large language models, the “hallucination” issue is further reduced.
For example, when translating content from Mixue Ice Cream & Tea’s prospectus, regarding the “according to CIC” section in the original text (CIC highlighted in red in the image), because the provided text snippet was incomplete, Ziyu 2.0 could not determine what noun the acronym stood for based on context. Therefore, it chose not to translate it.

Ziyu 2.0 Result:

Claude 3.5 Sonnet translated CIC as “China Investment Consulting.” Referencing the Chinese version of the prospectus, CIC should refer to CICC Consulting (CIC), making this a translation error.

Furthermore, in terms of word choice (green box in the image), Ziyu 2.0 combined context to translate “expansive” as “massive,” which is more appropriate for modifying supply chain; Claude literally translated it as “broad,” resulting in grammatical awkwardness in Chinese syntax.
In terms of sentence structure (pink box in the image), Ziyu 2.0’s translation version is also more concise and aligns better with native Chinese phrasing logic.
In medical papers, for large-scale translations, Ziyu 2.0’s results are more natural, fluent, and compliant with Chinese grammar, making them easier to understand.
For example, when translating the discussion section of the paper “Prohormone cleavage prediction uncovers a non-incretin anti-obesity peptide.”
Regarding the translation of the following sentence, Claude 3.5 Sonnet could only provide a literal translation:
It is difficult to study cleavage peptides using gene knockout mice because therapeutic effects of small peptide fragments like BRP may not be evident in mice lacking the parent protein (i.e., BRINP2).
Ziyu 2.0’s translation better conforms to Chinese expression habits, stating the cause first and then the result, making the output more fluent and easy to understand:
Because therapeutic effects of small peptide fragments (such as BRP) may not be evident in mice lacking the parent protein (i.e., BRINP2), it is therefore difficult to study cleavage peptides using gene knockout mice.

In more comprehensive evaluations, Ziyu 2.0’s performance is also noteworthy.
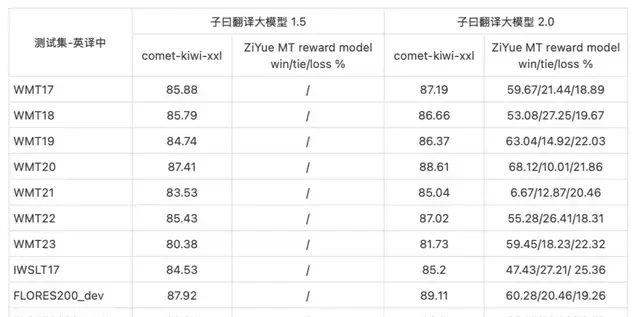
On one hand, it has achieved all-around improvements compared to the previous version (Ziyu 1.5) on international authoritative translation test sets.
The WMT (Workshop on Machine Translation) dataset is a series of benchmark datasets for machine translation. It contains translation data for multiple language pairs, typically sourced from news articles, parliamentary records, books, and other publicly available text resources. These datasets are widely used to train, evaluate, and compare different machine translation systems.
The Flores-200 dataset is an evaluation dataset built by Meta, specifically designed as a high-quality benchmark for machine translation. It covers 204 languages and allows for the assessment of model performance across 40,000 different language directions.
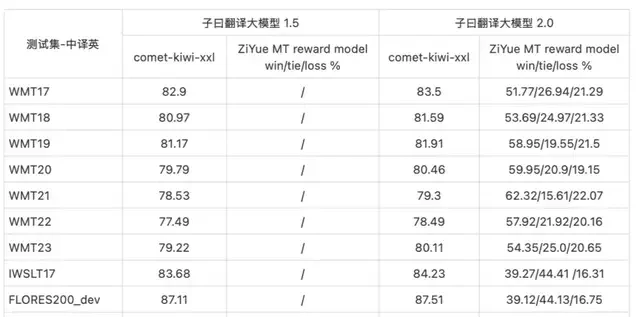
On the other hand, through a rigorous manual data collection process, NetEase Youdao has constructed a dataset covering 19 major fields, including humanities, business, lifestyle services, healthcare, and science. It has also established a comprehensive and detailed MQM (Multidimensional Quality Metrics) evaluation scheme, scoring translations across dimensions such as professionalism, accuracy, linguistic conventions, and style.
The following are the evaluation results compared with mainstream domestic and international general-purpose large language models (English to Chinese):
So, how did Ziyu 2.0 achieve this?
Not Replaced, But Made Stronger
Built on the foundation of Ziyu 2.0, NetEase Youdao Translation has completed an iteration of its underlying technology, bringing innovations across multiple dimensions including algorithms, data, and evaluation.
At the technical level, Ziyu 2.0 has further upgraded in terms of data, algorithms, and evaluation.
First, as a translation model is akin to a “liberal arts student,” higher-quality, larger-scale, and more diverse training corpora directly impact its translation performance.
Ziyu 2.0 incorporates tens of millions of high-quality translation data points cleaned by humans, including massive amounts of academic papers, international news, and authoritative dictionaries. This further enhances the model’s professional-level translation capabilities, making it more knowledgeable about different vertical domains than general-purpose large models.
Furthermore, professional translators have meticulously annotated vast numbers of prompts for the model, providing more professional and authoritative references. This strengthens the model’s domain adaptability, optimizes context understanding, and improves overall translation quality.
Secondly, looking at the core algorithm level, which is the focus of this iteration.
First, it underwent secondary training based on the Ziyu Education Large Model, further improving its performance in translation tasks and making it more specialized and targeted.
Second, through distillation (the key behind DeepSeek’s cost-effectiveness) and large model fusion, Ziyu 2.0 absorbed knowledge from two large models while achieving parameter pruning. This allows it to balance performance with operational and inference efficiency.
Large model fusion typically involves transferring the knowledge of one or more “teacher” models to a “student” model, enabling the student to learn new tasks while retaining old knowledge. This effectively avoids the problem of catastrophic forgetting in models.
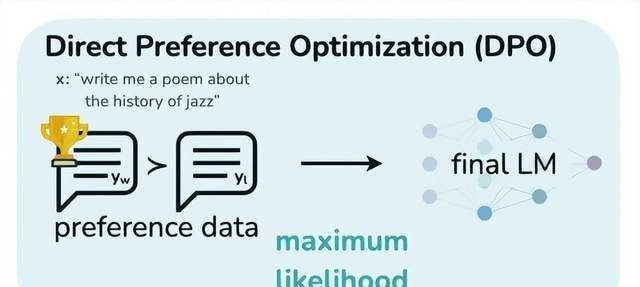
Third, the introduction of Online DPO.
DPO (Direct Preference Optimization) is an optimization method based on human preference data. It avoids the complex reward model training and policy optimization processes found in traditional reinforcement learning, converting preference learning into a simple binary classification problem to directly optimize the relative probabilities of the model’s outputs.
Online DPO further expands DPO’s capabilities by allowing rapid adjustment of the model to align with specific domain preferences across multiple domains. It also enables dynamic adjustments based on real-time feedback, ensuring continuous optimization across different preference datasets.
Finally, regarding the evaluation dimension, Ziyu 2.0 employs a self-developed translation evaluation model whose accuracy surpasses current state-of-the-art metrics like COMET, providing reliable quantitative data for assessing the performance of large language models in translation.
In terms of manual annotation and evaluation, Ziyu 2.0 uses manually annotated development sets and blind test sets. These datasets cover multiple domains and are meticulously labeled by professionals. During the evaluation process, the development set and blind test set are strictly separated to ensure objective and accurate results.
You can now experience the capabilities of Ziyu 2.0 by opening NetEase Youdao Dictionary/Translation and using its AI translation feature.
This means that amidst the wave of large models, translation apps once thought to be replaced by AI are becoming stronger by leveraging these models.
In a trend where scenarios reign supreme, players in vertical tracks who “find nails for their hammers” can deliver practical results more quickly.
Indeed, in the trend of deploying large models, scenario-focused companies have become the first group of “explorers” to deeply integrate with large models and generate profound impacts.
For example, WPS and Feishu in the office sector; Adobe and Meitu in the design sector. They have rapidly completed their AI upgrades, leading to actual revenue growth.
This collectively validates a pattern: under the wave of large models, rather than one single application handling all user needs, it is more likely that large models will reshape different vertical applications.
Large models are a new tool used to leverage greater demand and value.
Taking the translation field as an example, although general-purpose models can solve some basic translation problems, large model hallucinations still exist. Omissions, mistranslations, and redundancies occur frequently. Users sensitive to translation accuracy (such as researchers) still cannot fully trust the results generated by large models.
This is not alarmist talk but a reality many have encountered. Especially in scenarios involving long-form translations, even slight negligence during manual verification can
Negative impacts.

Thus, within vertical sectors, specialized tasks may still require specialists. In the era of large language models, we might still need a professional translation tool. It can be powered by AI, yet the translated content should carry no discernible “AI flavor.”
The wind of large models has blown not only the models themselves but also a wave of AI-powered applications.
These emerging trends and currents are collectively shaping the future.
So, between large language models and AI translation software, which do you use more frequently? Feel free to share your thoughts in the comments below.